实时asr新服务串讲
1.背景及现状
?????????工程方面目前语音相关服务存在大量重复代码,逻辑复杂,文档缺失,并且某些细节设计不合理。基于目前现状,代码业务与功能耦合严重,迭代困难,将来增加新的能力也需要改动音频数据相关代码,开发周期较长。
?????????推理框架目前老服务使用的Kaldi推理框架,需要使用业界最新的推理框架去替代老的框架,以便在模型大小,识别准确率,识别速率,以及实时效果等多方面进行优化。相对于Kaldi来说Whisper是一个轻量级的语音处理工具库,专注于实时语音处理和嵌入式设备。它提供了一些基本的语音处理功能,如语音增强、语音识别、语音合成等。Whisper的设计目标是在资源受限的环境下实现高效的语音处理,因此它的代码量相对较小,适合在嵌入式设备或边缘计算平台上使用,所以可以有效的降低资源占用。
2.整体流程架构
新的架构流程
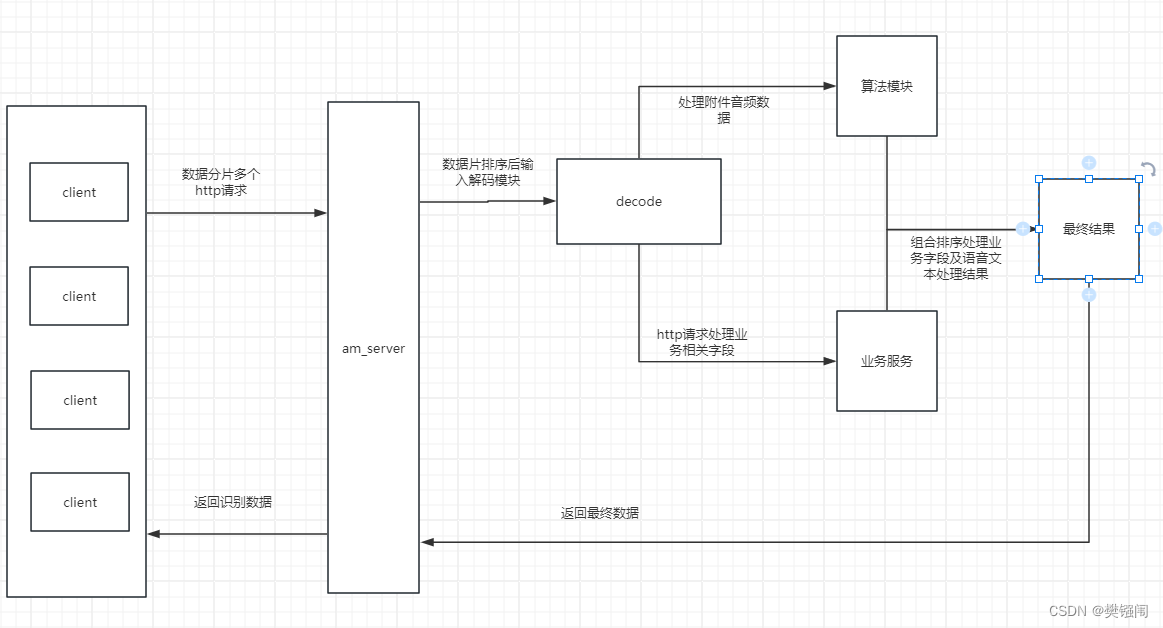
新的架构流程

可以看出,老服务有两个问题,首先是协议的选择,一次session需要进行多次http请求排序等分片组合逻辑会大大增加代码复杂度,另外很多业务能力(比如训练场,直播)处理放在了整个asr识别服务里面,属于功能与业务的耦合,需要进行拆解,方便代码维护与迭代。
3.新架构具体方案
1.协议相关
- 协议方面参考阿里接口
如何自行开发代码访问阿里语音服务_智能语音交互(ISI)-阿里云帮助中心
- 协议交互流程图
- sdk相关
???????对于用户端来说,接入asr可以通过两个方式接入,一种是直接根据协议文档进行接入,另一种是需要根据服务端提供的针对各个平台的sdk进行能力接入。
?调研是否可以复用阿里的sdk:
? ? ?相关链接
如何下载安装、使用实时语音识别PythonSDK及代码示例_智能语音交互(ISI)-阿里云帮助中心
?下载sdk查看依赖

可以看出来,阿里给的sdk需要安装他自身的核心库,这样会导致某些部分代码对我们来说是黑盒子,将来版本更替,能力升级,都可能会遇上兼容的问题。
? 测试代码
import?time
import?threading
import?sys
import?nls
#?from?tests.test_utils?import?(TEST_ACCESS_TOKEN,?TEST_ACCESS_APPKEY)
class TestSr:
def __init__(self,?tid,?test_file):
????????self.__th?=?threading.Thread(target=self.__test_run)
????????self.__id?=?tid
????????self.__test_file?=?test_file
def loadfile(self,?filename):
with open(filename, 'rb') as?f:
????????????self.__data?=?f.read()
def start(self):
????????self.loadfile(self.__test_file)
????????self.__th.start()
def test_on_start(self,?message, *args):
print('test_on_start:{}'.format(message))
def test_on_error(self,?message, *args):
print('on_error?args=>{}'.format(args))
def test_on_close(self, *args):
print('on_close:?args=>{}'.format(args))
def test_on_result_chg(self,?message, *args):
print('test_on_chg:{}'.format(message))
def test_on_completed(self,?message, *args):
print('on_completed:args=>{}?message=>{}'.format(args,?message))
def __test_run(self):
print('thread:{}?start..'.format(self.__id))
#ws://127.0.0.1:8081/v1/asr/realtime
????????sr?=?nls.NlsSpeechRecognizer(
????????????????????url?= 'ws://127.0.0.1:8081/v1/asr/realtime',
????????????????????token='none',
????????????????????appkey='none',
????????????????????on_start=self.test_on_start,
????????????????????on_result_changed=self.test_on_result_chg,
????????????????????on_completed=self.test_on_completed,
????????????????????on_error=self.test_on_error,
????????????????????on_close=self.test_on_close,
????????????????????callback_args=[self.__id]
)
while True:
print('{}:?session?start'.format(self.__id))
????????????r?=?sr.start(ex={'format':'pcm', 'hello':123})
????????????self.__slices?= zip(*(iter(self.__data),) * 640)
for?i?in?self.__slices:
????????????????sr.send_audio(bytes(i))
????????????????time.sleep(0.01)
????????????r?=?sr.stop()
print('{}:?sr?stopped:{}'.format(self.__id,?r))
????????????time.sleep(5)
def multiruntest(num=500):
for?i?in range(0,?num):
????????name?= 'thread' + str(i)
????????t?=?TestSr(name, 'tests/test1.pcm')
????????t.start()
nls.enableTrace(True)
multiruntest(1)
结论
?????使用官网sdk的话需要绕过相关验证机制,目前觉得应该不太合适.。
2.引擎框架
???????目前依据不同的库实现了两套引擎,一套是基于transform,一套基于fast-whisper,两种开元框架使用了不同的窗口策略。总体思路都是切分的方式,控制模型每次运算接收到的上下文窗口大小,让模型可以有对序列局部建模能力,然后将局部计算的结果拼接起来。
基本流程图

音频数据分片传输

??????上面是一段单通道?16khz??16bit?的pcm原始音频数据的波形图,录音设备获取原始数据后将数据按照时间分片存储在内存中,也就是数据采样的过程。将连续的模拟信号改为可存储量化的数字信号。
音频数据量化
???????将采样获取的数据使用numpy库进行音频数据量化,根据位深将数据量化为相应的数组,数组中每一个数据绝对值都小于2的16次方,方便后续输入算法模块。
静音检测处理
音频数据量化的基础上,后续的滑动窗口策略需要使用到静音来进行断句,静音原理是根据量化后的数据值是否大于100来确定的,因为外界有你声音的话,声音数据波动在2000以上。但是对于以后得优化可以进一步通过模型识别人声和非人声将这块逻辑进行替换,这样对于一些噪音很大的场景会提升识别准确率。
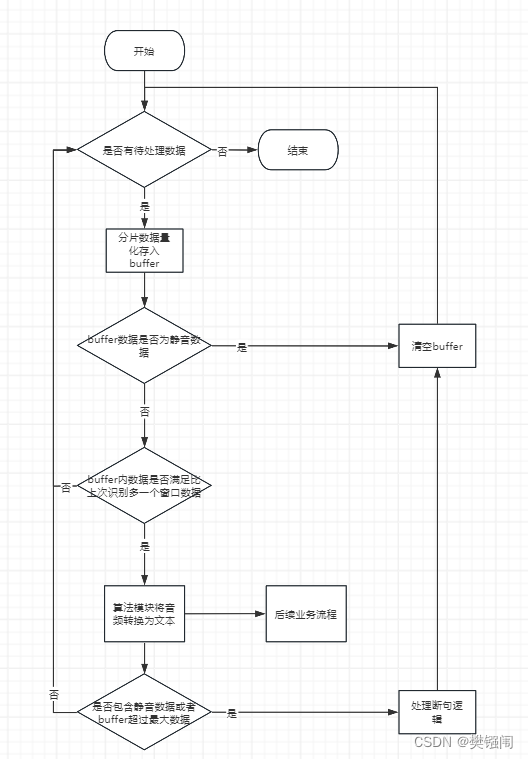
滑动窗口策略
- 基于transform实现流式的窗口策略
?????????使用该推理框架实现流式,由于窗口太小识别数据不准确,另外依据测试结果,对于稍微长的语音(小于30s),识别的rtf参数值小于1.0,可以满足流式的基本要求,所以滑动窗口采用音频buffer逐渐增加的方式最为窗口滑动策略。
具体流程图如下:
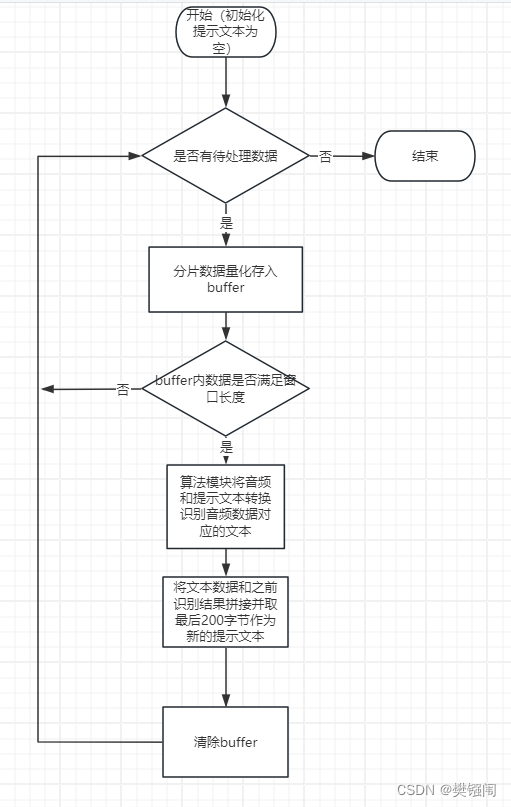
- 基于fast-whisper实现流式窗口策略
对于fast-whisper,使用github上开源的流式推理工程:
分析源码,发现由于fast-whisper提供的音频识别api支持condition_on_previous_text
参数,可以将之前识别的文本输出输入模型,协助模型识别该段音频数据,所以该推理工程使用数据buffer窗口大小不变,文本buffer滚动的方式进行流式处理。
具体流程如下:
4.测试指标
测试指标目前主要是字准与数据返回速度:
结论:
1.阿里目前首字时间打开600毫秒到800毫秒左右,流式过程中平均延时300ms到600ms范围内波动。
2.目前transform引擎目前首字时间打开600毫秒到800毫秒左右,流式过程中平均延时300ms到600ms范围内波动。
5.后续优化思考
- 工程方面
在调试过程中,不同的窗口大小,不同的数据流速,静音阈值的大小,对识别效果或多或少都有一定的影响,可能也是因为这个原因(当然也有别的原因,比如网络不稳定或者音频文件本身噪音就比较大等),会导致之前算法测试结果和实际使用中的结果有很大差异,所以如果遇上算法同学认为识别效果不错但是工程实现之后发现识别结果不尽人意,可以尝试调节不同的工程参数,尝试找到最契合算法测试环境的情况。
- ??推理框架
??????对于推理框架不只需要熟悉相关api相关参数,还要尽可能熟悉具体的内部原理,这样在模型调参过程中就不是盲目取尝试,做到先预期结果然后再验证。
??????另外比如想办法让模型可以识别人声,这样对于噪音场景的识别效果也会有所提升。
- ?????接入方式
???后续需要提供各个平台的sdk接入接口(第一阶段可以先让试用方根据协议进行接入)。
1
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深度解析JVM类加载器与双亲委派模型
- 外包干了2个月,技术倒退2年。。。
- 【第五节】java语言关键字
- Python Bokeh库详解:交互式数据可视化
- 图形化少儿编程的优点、现状以及未来发展趋势
- 操作系统导论-课后作业-ch4
- VsCode 配置Copilot的详细步骤与示例
- java版商城之一件代发设置 Spring Cloud+SpringBoot+mybatis+uniapp b2b2c o2o 多商家入驻商城 直播带货商城 电子商务 免 费 小程序商城搭建
- 适用于车载电动升窗器的芯片解决方案
- Python 输入输出, 标识符, import(保留字关键字) ,注释 , 缩进