手把手教你调用文心一言API,含py调用示例代码
发布时间:2024年01月11日

获取API密钥
注册或登录账号

选择应用接入
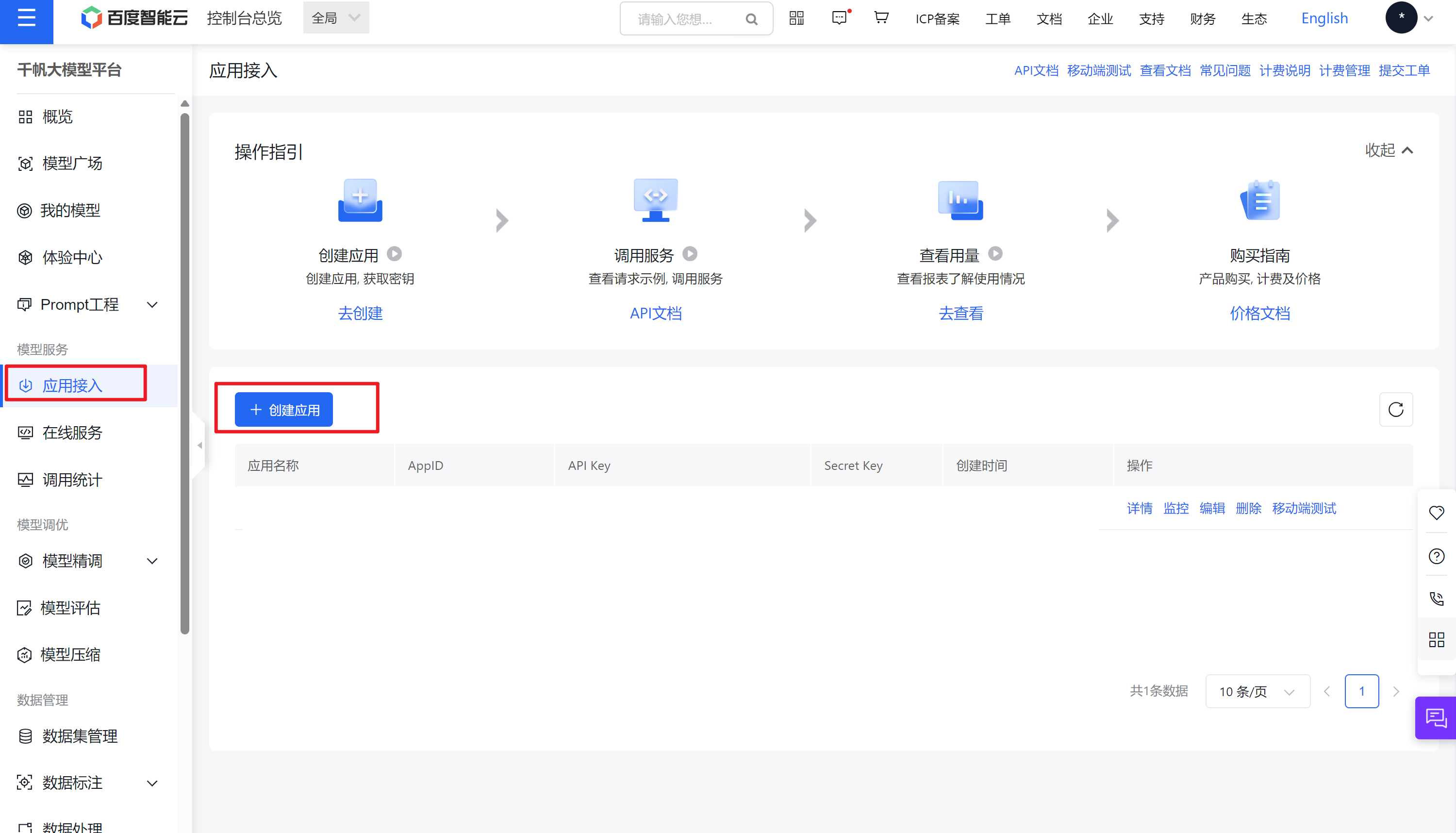
创建应用
随便起个名字
点击显示即可。
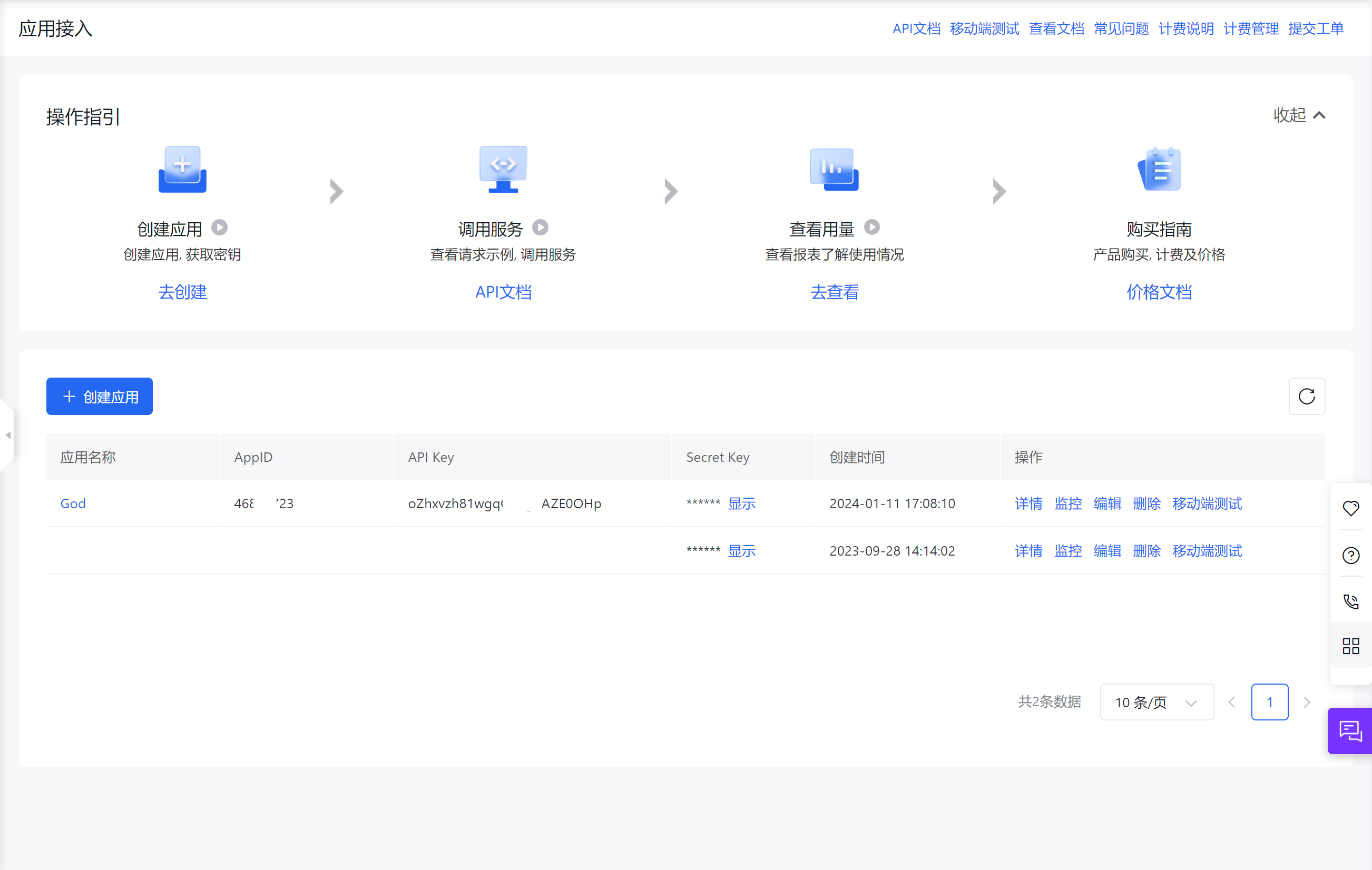
这个API Key和Secret Key就是我们需要的。

Python调用示例
下面的例子是用文心一言批量回答问题。
输入长这样就行:
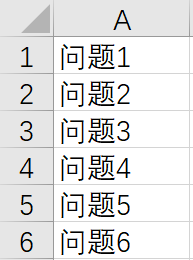
下面就是代码啦!
"""
@author: HeroZhang(池塘春草梦)
@contact:herozhang101@gmail.com
@version: 1.0.0
@file: law_ques.py
@time: 2024/1/11 16:25
@description: 调用文心一言api,实现批量回答问题
"""
import json
import pandas as pd
import requests
from tqdm import tqdm
filename = "一列问题.CSV"
# 格式:一列问题
filepath = "D:/gun/data/"
API_KEY = "换成你的"
SECRET_KEY = "换成你的"
def ask_Q(question):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions?access_token=" + get_access_token()
payload = json.dumps({
"messages": [
{
"role": "user",
"content": question
}
]
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return response
# print(response.text)
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
questions = pd.read_csv(filepath + filename, encoding="gbk", header=None, names=['questions'])
questions['answer'] = ""
# %%
for i in tqdm(range(len(questions))):
question = questions.iloc[i, 0]
Input = question + '并给出具体的法律条文'
ans = ask_Q(Input)
ans = json.loads(ans.text)
questions.loc[i, 'answer'] = ans['result']
questions.to_csv(filepath + '输出文件_文心一言.csv', encoding="gbk", index=False)
上面是个比较简单的例子,大家可以自由拓展。
可以看看我写的用gpt辅助读文献的代码,可以实现总结+分段总结,并且用简介好看的格式输出到markdown文件里。
【文献copilot】调用文心一言api对论文逐段总结_总结文章内容api-CSDN博客
如果觉得还不错,记得点赞+收藏哟!谢谢大家的阅读!( ̄︶ ̄)↗
最后给大家分享一首词。
鹧鸪天·西都作
宋 · 朱敦儒
我是清都山水郎。天教分付与疏狂。曾批给雨支风券,累上留云借月章。
)
如果觉得还不错,记得点赞+收藏哟!谢谢大家的阅读!( ̄︶ ̄)↗
最后给大家分享一首词。
鹧鸪天·西都作
宋 · 朱敦儒
我是清都山水郎。天教分付与疏狂。曾批给雨支风券,累上留云借月章。
诗万首,酒千觞。几曾著眼看侯王。玉楼金阙慵归去,且插梅花醉洛阳。
文章来源:https://blog.csdn.net/dream_of_grass/article/details/135535369
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- kubeadm来快速搭建一个K8S集群
- 银行接口测试学习笔记:接口测试从分析到设计!
- Zookeeper-Zookeeper应用场景实战(二)
- Docker安装WebRTC下TURN服务
- 2-6基础算法-快速幂/倍增/构造
- 【软件工程】融通未来的工艺:深度解析统一过程在软件开发中的角色
- easyExcel 获取多个sheet中复杂表头的数据
- 【已解决】本地使用Git拉取代码的时候提示:master has no tracked branch的解决办法
- 深度学习中的正则化指的是什么?
- 什么是网络工程师? 就业前景好吗?