基于pytorch的支持向量机
发布时间:2024年01月11日
本文主要实现了一个以pytorch编写的支持向量机。
任务目标
针对已知类别的5张卧室照片(标签为+1)和5张森林照片(标签为-1)所对应的矩阵数据进行分类训练,得到训练集模型;再利用支持向量机对另外未知类别的5张卧室照片和5张森林照片数据进行测试分类(二分类),得到分类结果及其准确率。
先导入查看基本数据
模型构建与训练
可以将支持向量机看成一个简单的,只有输入输出层的神经网络。所以直接使用pytroch框架中的神经网络的框架进行构建,并且自行定义出损失函数来达到支持向量机的结果
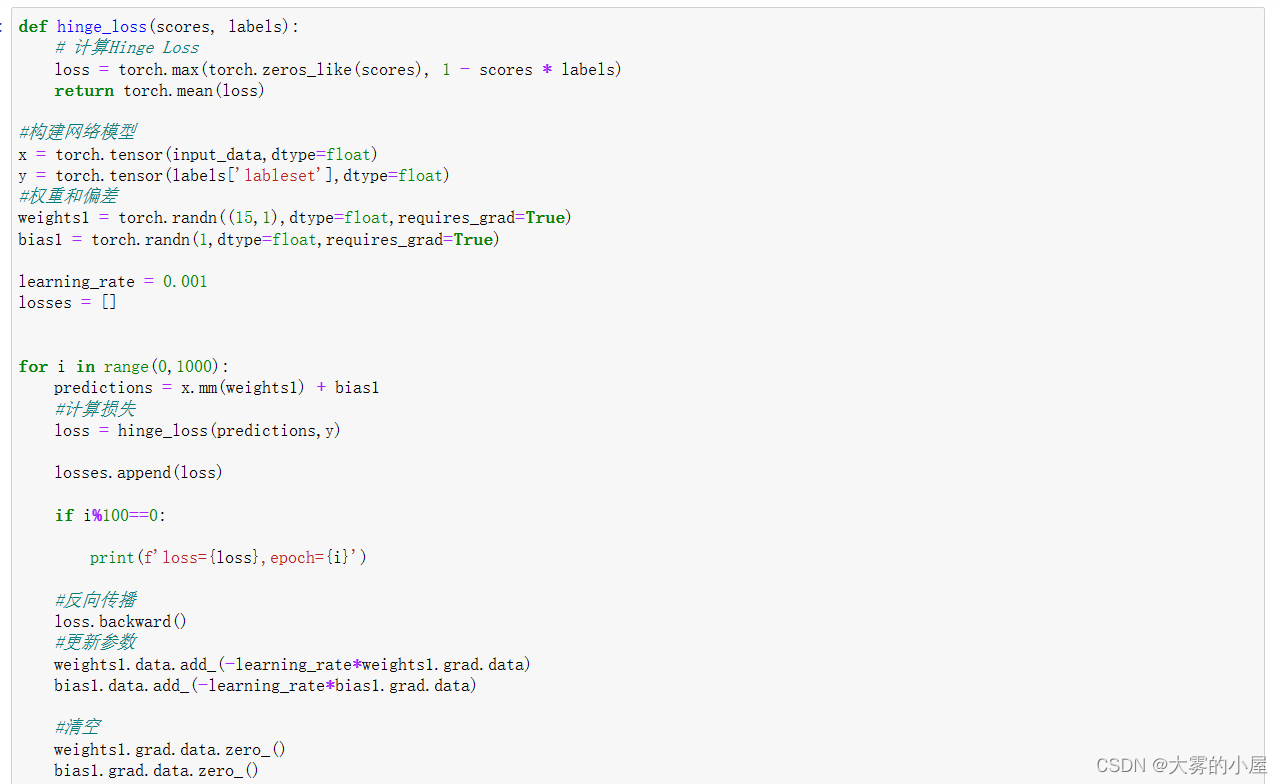
结果与可视化
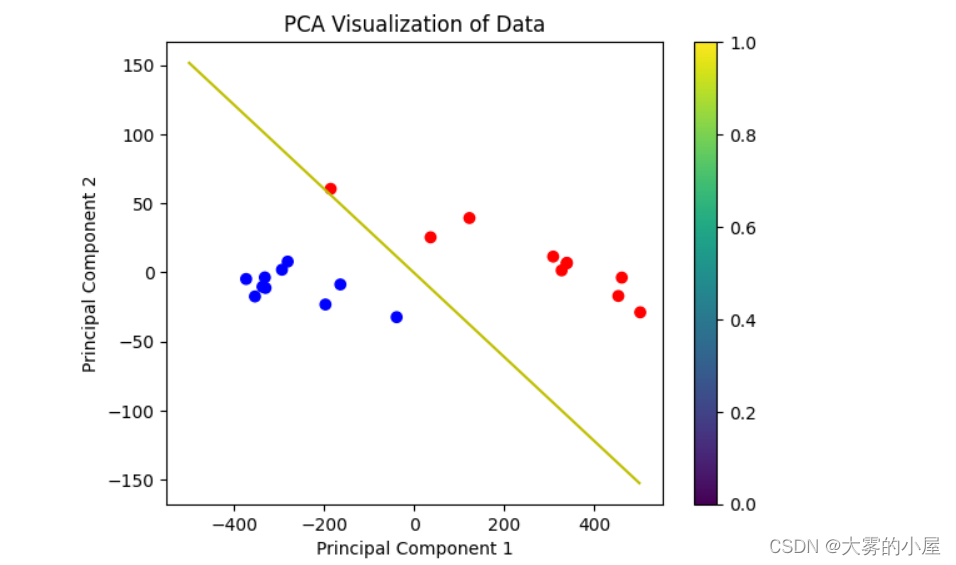
由于原本数据的维度较高,无法直接画出,所以这里先对数据进行PCA降维处理。然后将支持向量机所表示的超平面上的部分点找到也进行一样的处理(随机选取),而后再在二维平面上连成直线(由于降维问题,图像并不完美)
完整代码
import scipy.io as scio
import torch
import numpy as np
import torch.optim as optim
bedroom = scio.loadmat('bedroom')
forest = scio.loadmat('forest')
labels = scio.loadmat('labelset')
input_data = np.concatenate((bedroom['bedroom'], forest['MITforest']), axis=0)
def hinge_loss(scores, labels):
# 计算Hinge Loss
loss = torch.max(torch.zeros_like(scores), 1 - scores * labels)
return torch.mean(loss)
#构建网络模型
x = torch.tensor(input_data,dtype=float)
y = torch.tensor(labels['lableset'],dtype=float)
#权重和偏差
weights1 = torch.randn((15,1),dtype=float,requires_grad=True)
bias1 = torch.randn(1,dtype=float,requires_grad=True)
learning_rate = 0.001
losses = []
for i in range(0,1000):
predictions = x.mm(weights1) + bias1
#计算损失
loss = hinge_loss(predictions,y)
losses.append(loss)
if i%100==0:
print(f'loss={loss},epoch={i}')
#反向传播
loss.backward()
#更新参数
weights1.data.add_(-learning_rate*weights1.grad.data)
bias1.data.add_(-learning_rate*bias1.grad.data)
#清空
weights1.grad.data.zero_()
bias1.grad.data.zero_()
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.svm import SVC
color = []
for i in labels['lableset']:
if i == 1:
color.append('red')
else:
color.append('blue')
# 设置随机种子,以确保每次运行代码时生成的随机数相同(可选步骤)
np.random.seed(42)
# 生成随机的 15 维向量组
num_samples = 100 # 设置生成向量组的数量
dimensionality = 15 # 向量的维度
random_vectors = np.random.rand(num_samples, dimensionality)
print(random_ve)
# 使用PCA降维并可视化数据
pca = PCA(n_components=2) # 将数据降到2维
data_pca = pca.fit_transform(input_data)
plt.scatter(data_pca[:, 0], data_pca[:, 1], c=color, cmap='viridis', marker='o')
plt.title('PCA Visualization of Data')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.colorbar()
plt.show()
文章来源:https://blog.csdn.net/weixin_43486940/article/details/135483704
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 最新版Navicat的安装与激活
- HTML基础
- 若依微服务-spring-cloud配置HTTPS访问及SSL证书,保姆级,带详细说明
- 竞赛保研 基于机器视觉的行人口罩佩戴检测
- OSS存储引擎如何使用以及如何添加图片【建议收藏】
- 算法自学__三分法
- 代码随想录算法训练营第55天|● 392.判断子序列 ● 115.不同的子序列
- 【C语言】Ubuntu 22上用GTK写GUI程序
- 【论文解读】LERF:语言嵌入的辐射场(ICCV 2023 Oral)
- 【开源】基于JAVA语言的停车场收费系统