爬虫—中信证券资管产品抓取
发布时间:2024年01月14日
爬虫—中信证券资管产品抓取
中信证券资管产品板块网址:http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/
页面截图如下:
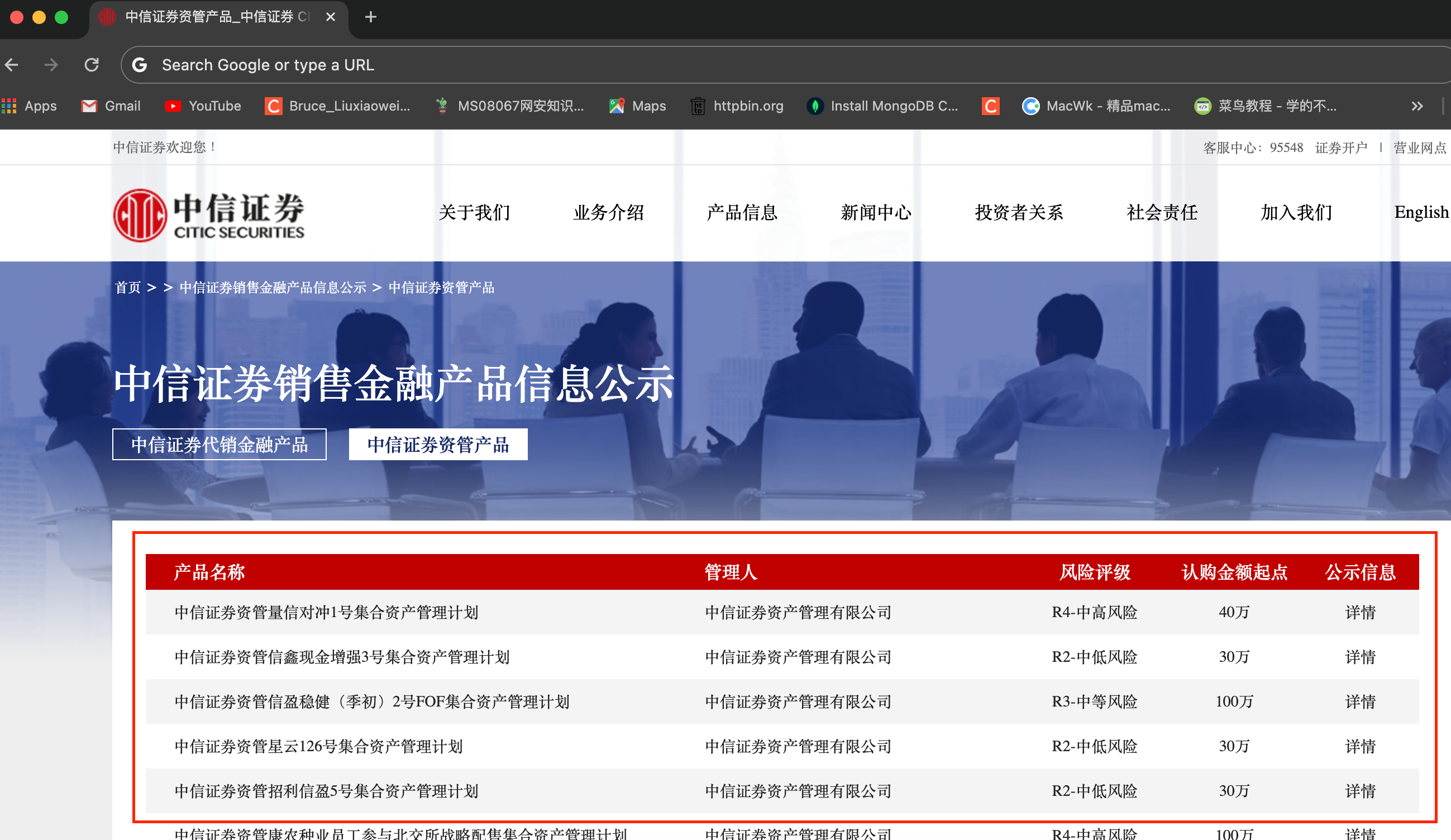
目标:抓取上图中红框内的所有资产信息
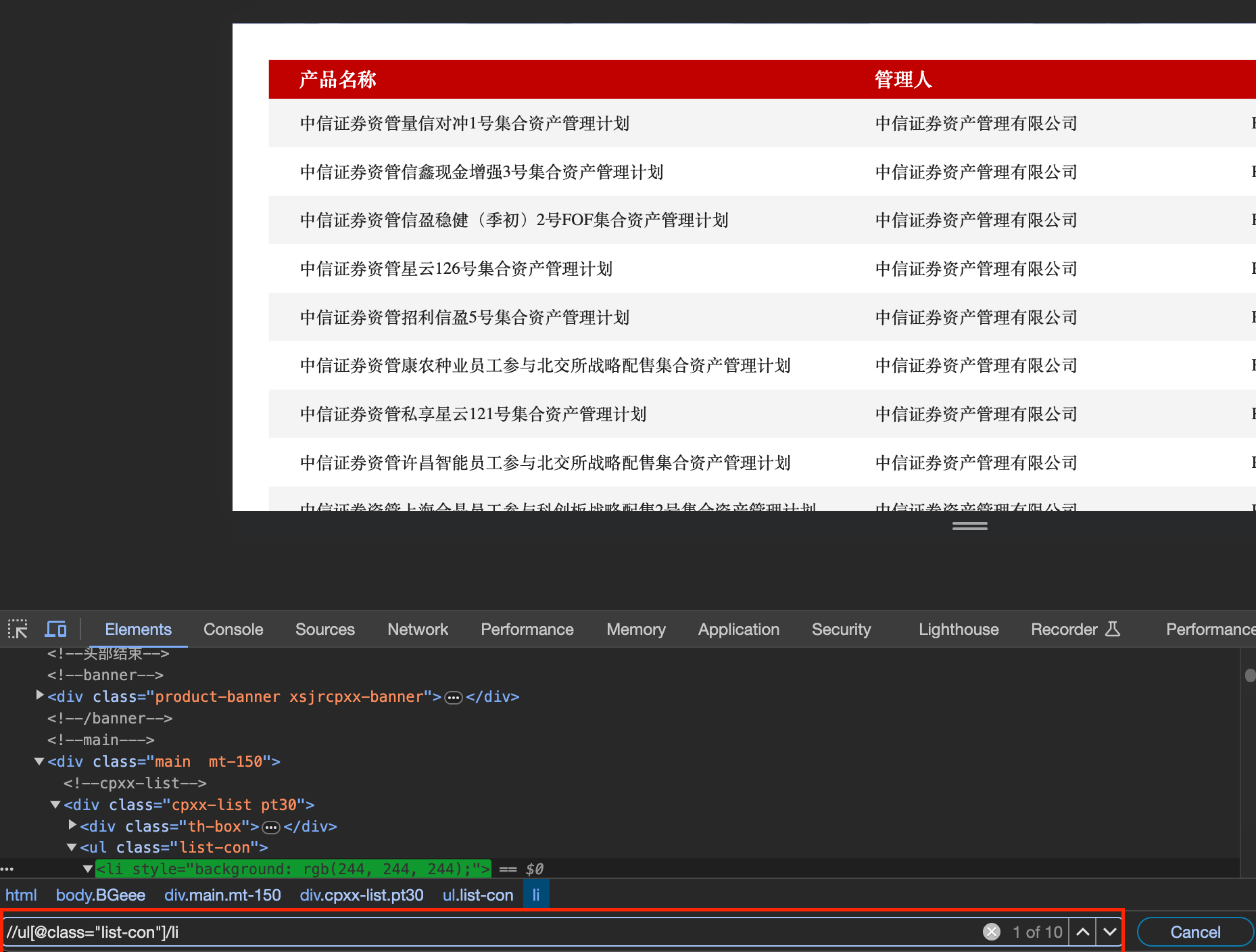
按F12进入开发者工具模式,在Elements板块下,在搜索框内输入“//ul[@class=“list-con”]/li",匹配ul列表里的所有资管产品的li标签,如图:
抓取单页数据,源码如下:
import requests
from lxml import etree
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
url = 'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index.html'
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
data = res.text
tree = etree.HTML(data)
# 获取每个li标签
li_lst = tree.xpath('//ul[@class="list-con"]/li')
i = 1
for li in li_lst:
print(str(i)+'.', ', '.join(li.xpath('./span/text()')))
i += 1
运行结果如下:

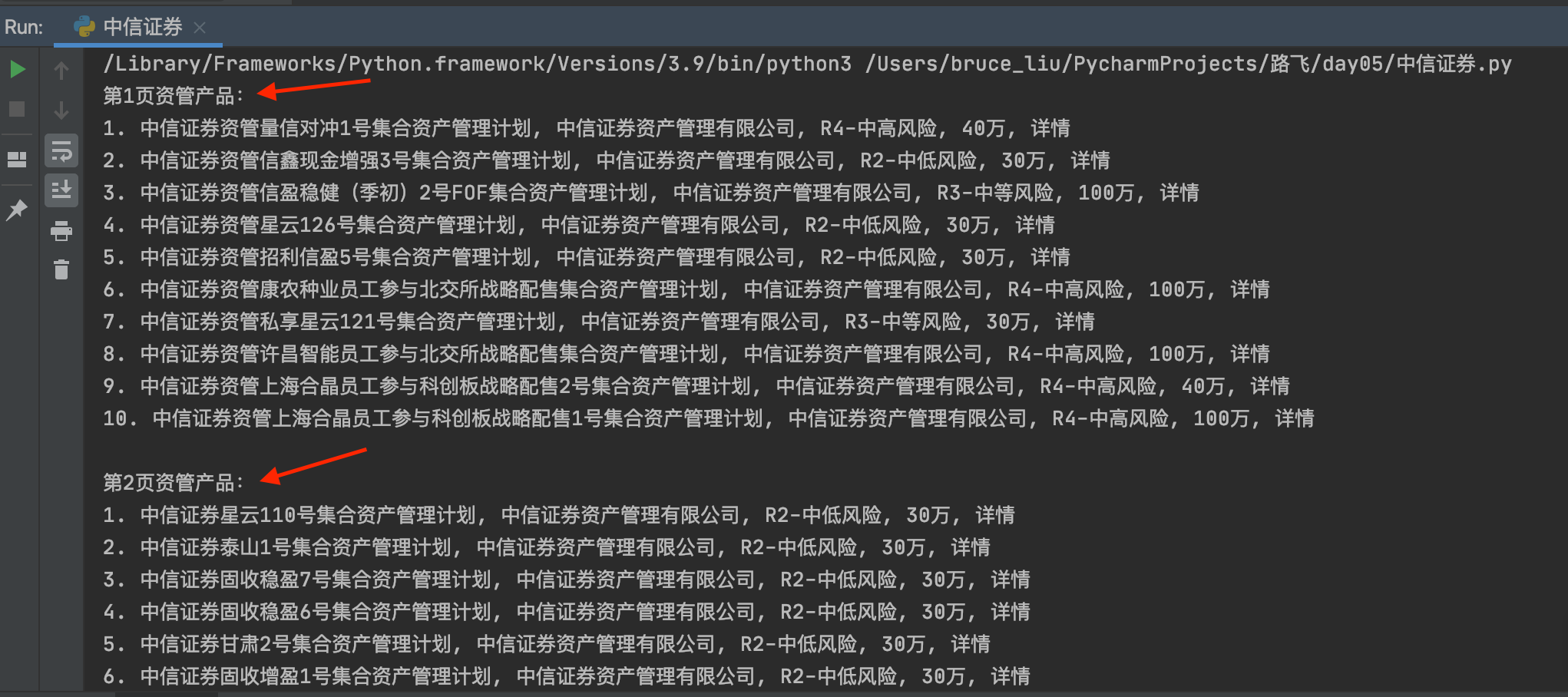
本案例只抓取第一页的资管产品信息,如果想抓取多页,可以自行修改代码。
抓取多页数据,源码如下:
import requests
from lxml import etree
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 定义一个函数,抓取每页的数据
def get_page(page_url):
res = requests.get(page_url, headers=headers)
res.encoding = res.apparent_encoding
data = res.text
tree = etree.HTML(data)
# 获取每个li标签
li_lst = tree.xpath('//ul[@class="list-con"]/li')
i = 1
for li in li_lst:
print(str(i) + '.', ', '.join(li.xpath('./span/text()')))
i += 1
# 抓取前4页的数据
for page_n in range(4):
# 格式化资管产品的页面网址
page_url = f'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index_{page_n}.html'
# 第一页的资管产品网址
if page_n == 0:
page_url = 'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index.html'
print(f'第{page_n + 1}页资管产品:')
get_page(page_url)
运行结果如下:
思考:如果抓取任意页数的数据,可以参考如下代码。
# 定义一个页数变量
page_num = input('请输入要抓取的页数: ')
把抓取多页源码的range()内的数字替换为page_num,要转成整型数据int(page_num)。
.....
文章来源:https://blog.csdn.net/weixin_41905135/article/details/135579274
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mini-Batch梯度下降
- MyBatis应用
- Redis 面试题 | 05.精选Redis高频面试题
- 网络逻辑示意图工具
- 调试ad5245的总结
- Note: A Horrible Earthquake
- 52.常用shell之 gzip / gunzip - 压缩和解压文件 的用法及衍生用法
- Linux 命令行调试WiFi
- 鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之线性布局容器Column组件
- 什么软件能查出微信聊天记录(3款实用工具盘点!)