ViT中的上采样和下采样——patch merge
发布时间:2023年12月25日
在视觉Transformer(Vision Transformer,ViT)中,上采样和下采样通常指的是在不同层之间调整特征图的空间分辨率,以便在不同层次上捕获图像的不同尺度的信息。与传统的卷积神经网络(CNN)不同,ViT使用自注意力机制而不是卷积操作来处理输入图像,因此上采样和下采样的方式也有所不同。
1.下采样(Downsampling):
在ViT中,通常使用池化操作来实现下采样,减小特征图的空间分辨率。这有助于提取图像中的全局信息,并减少计算负担。
通常,在ViT的初始输入部分,会使用一些池化操作或步幅大的卷积来减小图像的空间维度,以便更有效地进行自注意力计算。
2.上采样(Upsampling):
在解码器部分,或者在输出部分,可能需要上采样来恢复图像的空间分辨率。这可以通过插值等方法实现。
由于ViT并没有明确的解码器结构,而是通过全局自注意力来处理整个图像,因此上采样的操作可能不像传统的卷积神经网络那样明显。
总体而言,ViT中的上采样和下采样主要是通过池化和插值等操作来实现的,以在不同层次上处理输入图像的尺度信息。这有助于使模型能够同时捕获全局和局部的视觉信息。在一些变体中,可能会使用多尺度的注意力机制,以更好地处理不同尺度的信息。
在ViT中,下采样可以是使用patch merge。如下图所示。4倍的下采样变成8倍下采样。原本的特征图的大小(h,w,c),变成了(h/2, w/2, 2c)。图片单位大小变小了4倍,通道数变大了两倍。

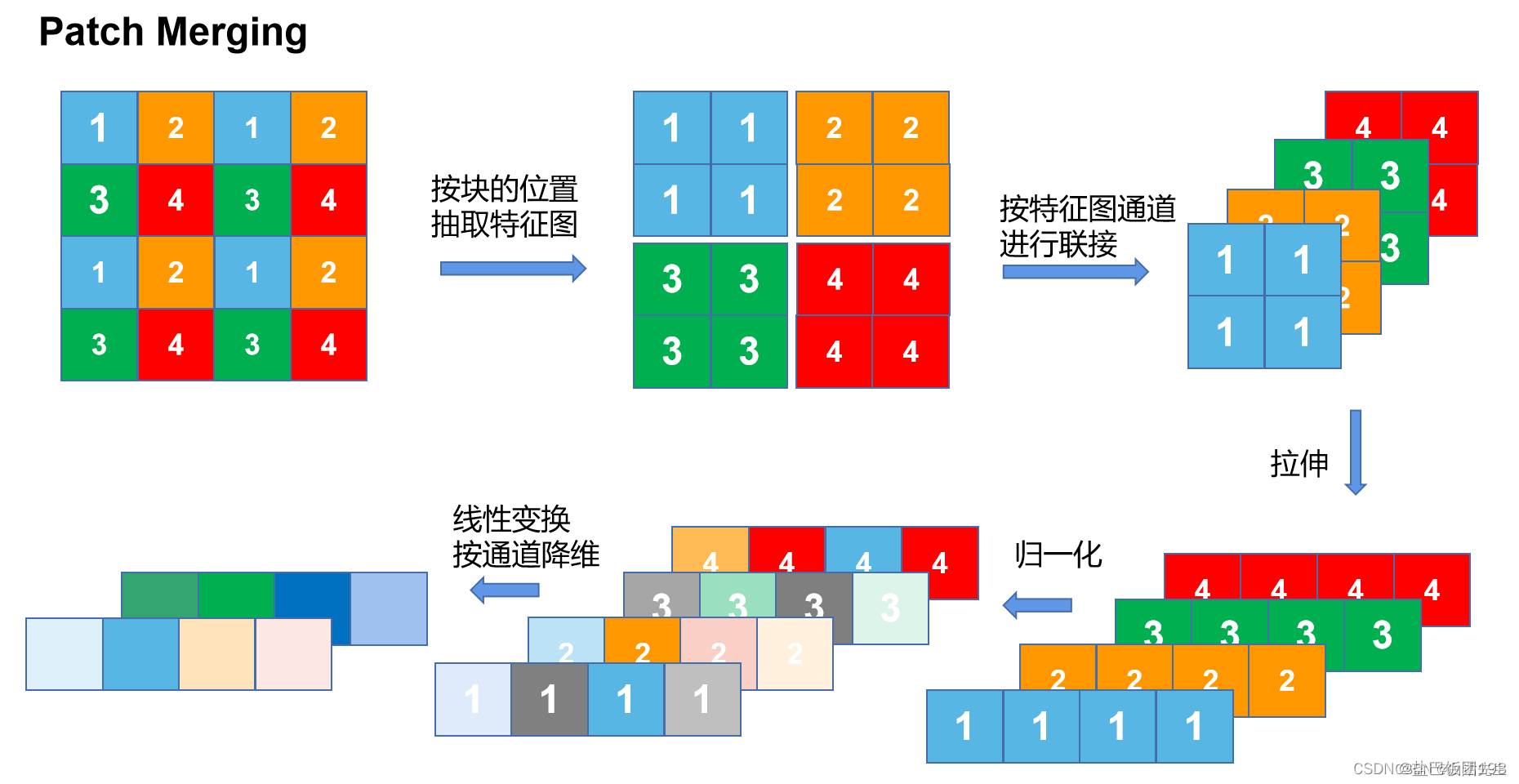
patch Merging是一个类似于池化的操作,但是比Pooling操作复杂一些。 池化会损失信息,patch Merging不会。
文章来源:https://blog.csdn.net/zhu_ba/article/details/135199587
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 华为HCIE-Datacom课程介绍
- 西南地区直播产业市场规模分析,透视成都直播基地产业全景
- 从免费到付费:比较和评测不同类型的代理IP资源
- [c]超半的数
- Linux端口开放- minio外网访问不了
- 任务5:安装并配置Hadoop
- 定时任务 crontab (centos)+定时查看top的数据并按日期输出到指定文件
- 使用ObjectARX事务功能做小动画处理
- 面试算法90:环形房屋偷盗
- 【Python百宝箱】从平凡到卓越:如何通过评估和调优提升机器学习模型质量