Hadoop和Spark的区别
发布时间:2023年12月18日
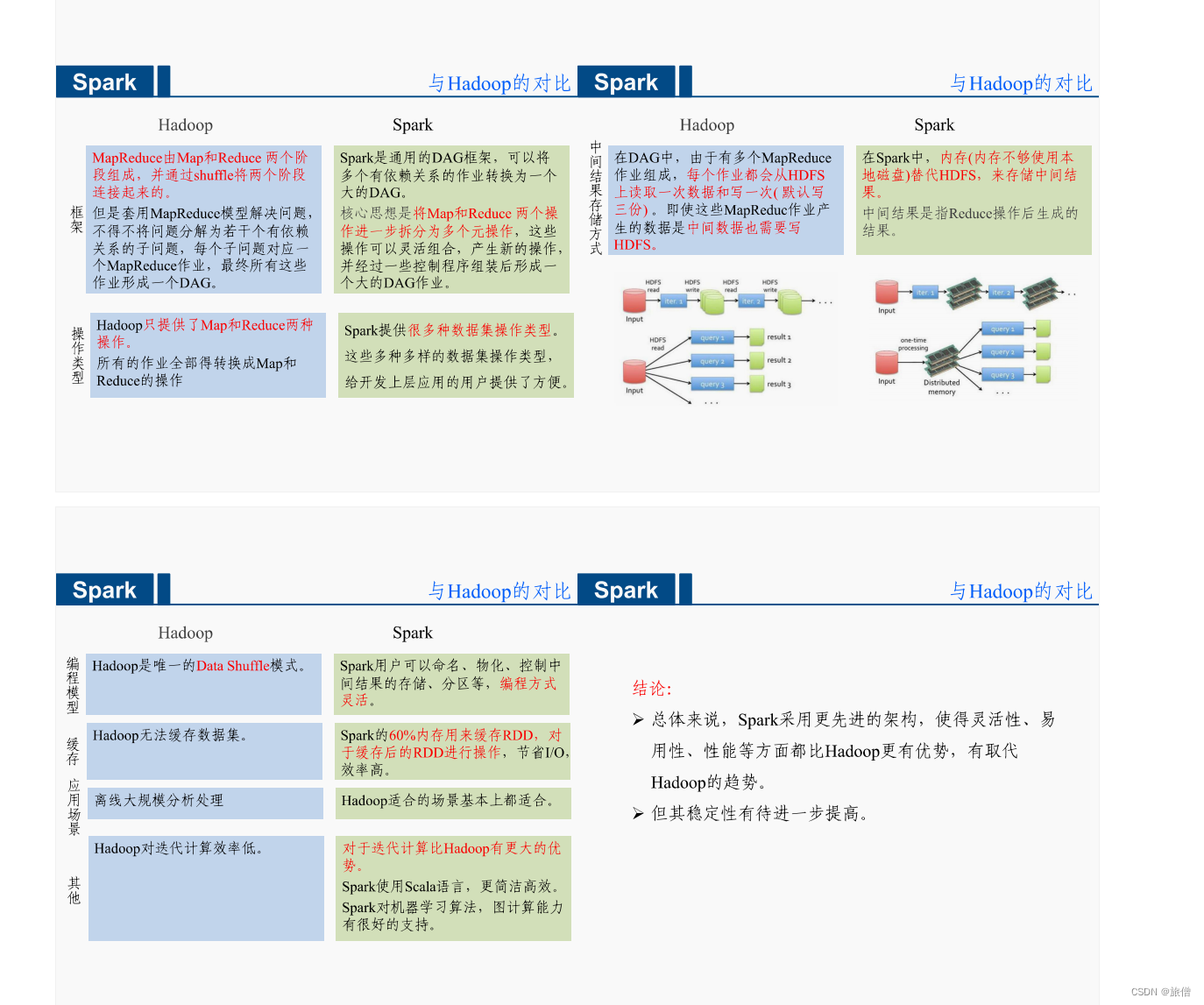
Hadoop
- 表达能力有限。
- 磁盘IO开销大,延迟度高。
- 任务和任务之间的衔接涉及IO开销。
- 前一个任务完成之前其他任务无法完成,难以胜任复杂、多阶段的计算任务。
Spark
-
Spark模型是对Mapreduce模型的改进,可以说没有HDFS、Mapreduce就没有Spark。
-
Spark可以使用Yarn作为他的资源管理器,并且可以处理HDFS数据。这对于已经部署了Hadoop集群的用户特别重要,因为他们不需要任何的数据迁移就可以使用到spark的强大功能了。?
文章来源:https://blog.csdn.net/qq_62260432/article/details/135014654
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 内部员工满意度抽样方法
- 编程语言的未来:飞速发展的时代里有不可或缺的你
- 【计算机网络】TCP协议——3. 可靠性策略&效率策略
- 2SK3019 中低压MOSFET 60V 100mA 双N通道 SOT-723封装
- 跨Android、iOS、鸿蒙多平台框架ArkUI-X
- 【flink番外篇】7、flink的State(Keyed State和operator state)介绍及示例(2) - operator state
- 玩转Mock.js:构建模拟数据的利器
- hub汉语有轮毂的意思吗?
- 显示报错: nmap.nmap.PortScannerError: ‘nmap program was not found in path‘
- 电路图——DRV8833直流电机驱动芯片电路图(详细)