[易语言]使用易语言部署yolov7-onnx模型
【官方框架地址】
https://github.com/WongKinYiu/yolov7
【算法介绍】
YOLOv7是YOLO(You Only Look Once)系列目标检测算法的最新版本之一,其设计理念是在保持实时处理速度的同时,提高目标检测的准确性。YOLO算法因其高效的目标检测性能而广受欢迎,它可以在单次前向推断中对图像中的多个物体进行检测和分类。YOLOv7在其前身的基础上,通过引入新的架构和训练策略,进一步优化了模型的性能。
核心特性
YOLOv7具备以下主要特性:
实时性能
YOLOv7继承并增强了YOLO系列算法的实时处理能力,它通过优化的模型架构和算法,可以在保持高帧率的同时进行准确的目标检测。
准确性提升
相比之前的版本,YOLOv7在多个公开的标准数据集上展现出更高的检测准确率,这要归功于其改进的模型结构和训练技巧。
网络架构优化
YOLOv7对网络架构进行了优化,引入了更加有效的特征提取层和卷积层设计,这使得模型能够更好地捕捉图像中的细节信息,以及更好地泛化到不同的目标和背景上。
训练策略改进
YOLOv7中使用了新的训练策略,如自适应标签平滑、数据增强、自动学习速率调整等,这些都有助于提高模型的鲁棒性和泛化能力。
应用场景
YOLOv7可应用于各种需要快速且准确目标检测的场景,包括但不限于:
- 视频监控:在安全和监控应用中,YOLOv7可以实时检测和跟踪人员或车辆等目标。
- 自动驾驶:用于车辆环境感知系统,对行人、车辆和交通标志等进行检测。
- 工业自动化:在制造业中,YOLOv7可以识别和定位产品中的缺陷或组件。
- 零售分析:在零售环境中,YOLOv7可以用来跟踪顾客行为和货品管理。
技术优势
速度与准确率的平衡
YOLOv7在不牺牲速度的前提下提高了准确率,这得益于其网络设计和训练策略的优化。
适应性强
该模型对于不同大小、形状和尺度的目标都有很好的检测能力,且对于不同的应用场景都能够调整和优化。
跨平台性
YOLOv7支持在多种平台上运行,包括使用CPU、GPU和边缘计算设备,这使得它可以灵活部署在各种环境中。
总而言之,YOLOv7作为YOLO系列中的一个优秀代表,它通过创新的设计和技术改进,提供了一个高效、精确且适用性广泛的目标检测解决方案。
【效果展示】
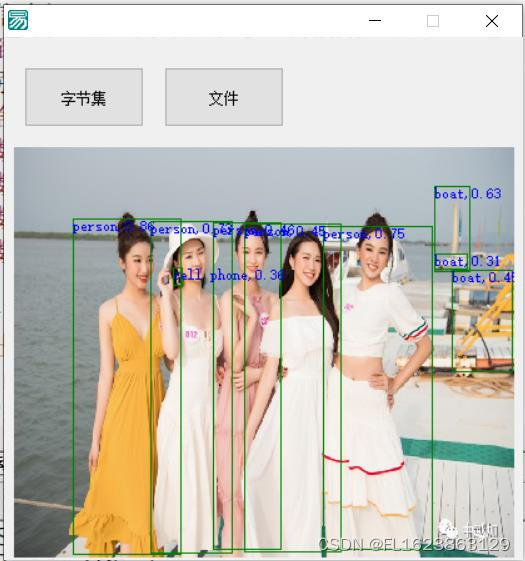
【实现部分代码】
.版本 2
.支持库 spec
YOLO7_加载模型 (“yolov7-tiny_640x640.onnx”, “labels.txt”, 0.3, 0.45)
图片字节集 = 读入文件 (“person.jpg”)
图片大小 = 取字节集长度 (图片字节集)
推理结果 = YOLO7_推理_从字节集 (图片字节集, 图片大小)
绘制结果 (图片字节集, 推理结果)
调试输出 (推理结果)
YOLO7_释放资源 ()
【视频演示】
e5.93
opencv4.7.0
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!