可媲美Gen2的视频生成大一统模型;Vlogger根据用户描述生成分钟级视频;Vision Mamba提速2.8倍节省86.8%
本文首发于公众号:机器感知
可媲美Gen2的视频生成大一统模型;Vlogger根据用户描述生成分钟级视频;Vision Mamba提速2.8倍节省86.8%
UniVG: Towards UNIfied-modal Video Generation

Current efforts are mainly concentrated on single-objective or single-task video generation, such as generation driven by text, by image, or by a combination of text and image. We propose a Unified-modal Video Genearation system that is capable of handling multiple video generation tasks across text and image modalities. Our method achieves the lowest Fr\'echet Video Distance (FVD) on the public academic benchmark MSR-VTT, surpasses the current open-source methods in human evaluations, and is on par with the current close-source method Gen2.
Training-Free Semantic Video Composition via Pre-trained Diffusion Model
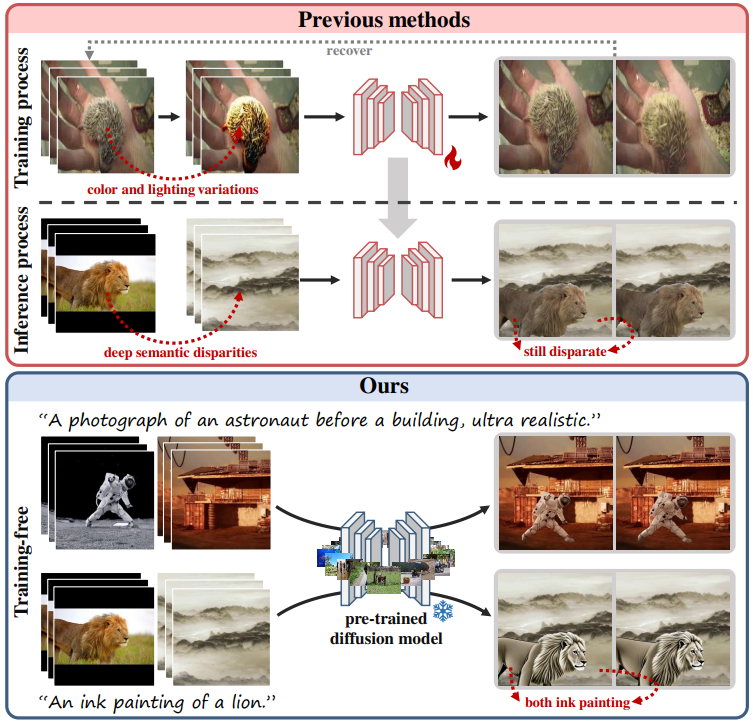
The video composition task aims to integrate specified foregrounds and backgrounds from different videos into a harmonious composite. Current approaches, predominantly trained on videos with adjusted foreground color and lighting, struggle to address deep semantic disparities beyond superficial adjustments, such as domain gaps. Therefore, we propose a training-free pipeline employing a pre-trained diffusion model imbued with semantic prior knowledge, which can process composite videos with broader semantic disparities.
Vlogger: Make Your Dream A Vlog

In this work, we present Vlogger, a generic AI system for generating a minute-level video blog (i.e., vlog) of user descriptions. Different from short videos with a few seconds, vlog often contains a complex storyline with diversified scenes, which is challenging for most existing video generation approaches. To break through this bottleneck, our Vlogger smartly leverages Large Language Model (LLM) as Director and decomposes a long video generation task of vlog into four key stages, where we invoke various foundation models to play the critical roles of vlog professionals, including (1) Script, (2) Actor, (3) ShowMaker, and (4) Voicer. With such a design of mimicking human beings, our Vlogger can generate vlogs through explainable cooperation of top-down planning and bottom-up shooting.
Vision Mamba: Efficient Visual Representation Learning with ?Bidirectional State Space Model
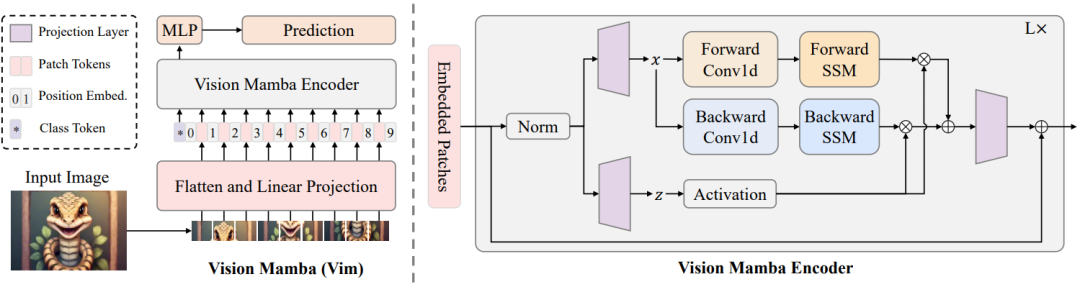
In this paper, we show that the reliance of visual representation learning on self-attention is not necessary and propose a new generic vision backbone with bidirectional Mamba blocks (Vim), which marks the image sequences with position embeddings and compresses the visual representation with bidirectional state space models. On ImageNet classification, COCO object detection, and ADE20k semantic segmentation tasks, Vim achieves higher performance compared to well-established vision transformers like DeiT, while also demonstrating significantly improved computation & memory efficiency. For example, Vim is 2.8$\times$ faster than DeiT and saves 86.8% GPU memory when performing batch inference to extract features on images with a resolution of 1248$\times$1248.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python将已标注的两张图片进行上下拼接并修改、合并其对应的Labelme标注文件(v2.0)
- python学习3
- 【vue】前端页面点击按钮弹窗播放m3u8格式视频
- 精彩回顾 I DatenLord Hackathon 2023圆满结束!
- 神经网络分类模型的评价函数和曲线图
- 初识Dubbo学习,一文掌握Dubbo基础知识文集(1)
- PostgreSQL数据库安装部署
- ssm某某学校绩效管理系统(程序+开题)
- 一位面试了20+家公司的测试工程师,发现了面试“绝杀四重技”!
- OpenCV4应用开发:入门、进阶与工程化实践