[Python] scikit-learn - K近邻算法介绍和使用案例
发布时间:2024年01月23日
什么是K近邻算法?
K近邻算法(K-Nearest Neighbors,简称KNN)是一种基于实例的学习方法,主要用于分类和回归任务。它的基本思想是:给定一个训练数据集,对于一个新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数类别就是该输入实例的类别。
思路:
- 计算输入实例与训练数据集中每个实例之间的距离。
- 对距离进行排序,找到距离最近的K个实例。
- 根据这K个实例的类别进行投票,得到输入实例的类别。
K近邻算法使用场景和注意事项
K近邻算法(K-Nearest Neighbors,简称KNN)是一种基于实例的学习方法,主要用于分类和回归任务。它的使用场景包括:
- 数据集较小的情况:当数据集较小时,KNN算法可以快速地进行训练和预测,而不需要大量的计算资源。
- 数据集中存在噪声的情况:由于KNN算法是基于实例的,因此它对数据集中的噪声具有一定的容忍度。
- 数据集中存在异常值的情况:KNN算法在处理异常值时,会根据邻近实例的类别来进行投票,从而降低了异常值对结果的影响。
- 数据集中存在不平衡类别的情况:KNN算法在处理不平衡类别的数据集时,可以通过调整K值来平衡各个类别之间的样本数量。
在使用KNN算法时,需要注意以下几点:
- 选择合适的K值:K值的选择对算法的性能有很大影响。通常情况下,可以通过交叉验证等方法来选择合适的K值。
- 特征选择:KNN算法对特征的数量和质量要求较高,因此需要对特征进行选择和预处理,以提高算法的性能。
- 距离度量:KNN算法需要计算实例之间的距离,因此需要选择合适的距离度量方法,如欧氏距离、曼哈顿距离等。
- 性能评估:为了确保算法的性能,需要对算法进行性能评估,如准确率等指标。
K近邻算法python实现
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
from collections import Counter
def euclidean_distance(x1, x2):
# 计算欧氏距离
return np.sqrt(np.sum((x1 - x2) ** 2))
class KNN:
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X):
y_pred = [self._predict(x) for x in X]
return np.array(y_pred)
def _predict(self, x):
# 计算输入实例与训练数据集中每个实例之间的距离
distances = [euclidean_distance(x, x_train) for x_train in self.X_train]
# 对距离进行排序,找到距离最近的K个实例的索引
k_indices = np.argsort(distances)[:self.k]
# 根据这K个实例的类别进行投票,得到输入实例的类别
k_nearest_labels = [self.y_train[i] for i in k_indices]
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
knn = KNN(k=3)
knn.fit(X_train, y_train)
predictions = knn.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))scikit-learn中的K近邻算法
K近邻算法用于分类任务
sklearn.neighbors.KNeighborsClassifier — scikit-learn 1.4.0 documentation

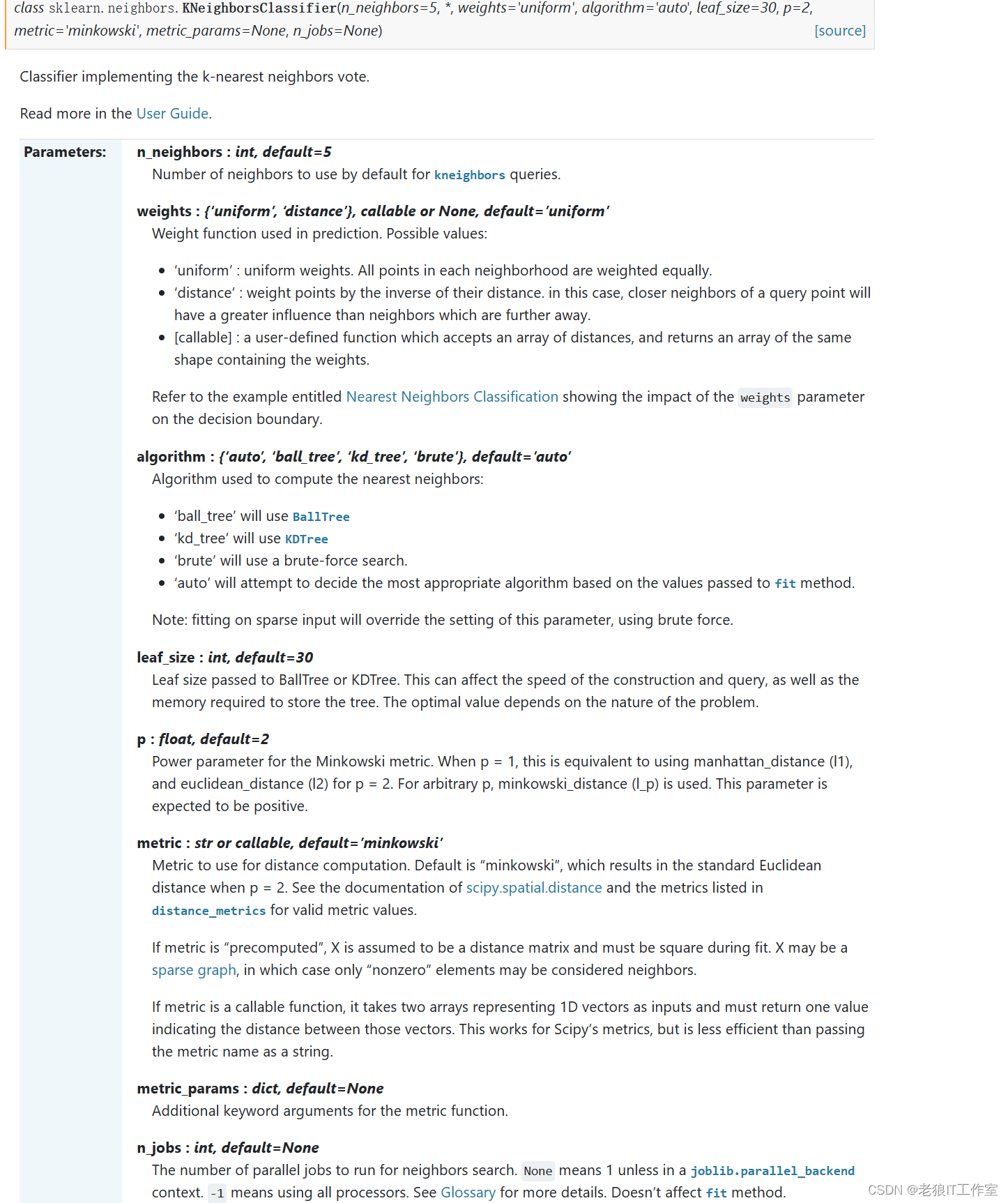 ?
?
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
knc = KNeighborsClassifier(n_neighbors=3)
knc.fit(X_train, y_train)
predictions = knc.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))在这个示例中,我们首先从scikit-learn库中加载了iris花卉数据集,并将其划分为训练集和测试集。然后,我们创建了一个KNeighborsClassifier对象,并设置了K值为3。接下来,我们使用训练集对模型进行训练,并使用测试集进行预测。最后,我们计算了预测结果的准确度。?
K近邻算法用于回归任务
sklearn.neighbors.KNeighborsRegressor — scikit-learn 1.4.0 documentation

 ?
?
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
# 加载iris花卉数据集
data = load_iris()
X = data.data
y = data.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNeighborsRegressor对象,设置K值为3
knn = KNeighborsRegressor(n_neighbors=3)
# 使用训练集对模型进行训练
knn.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = knn.predict(X_test)
# 计算预测结果的均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)在这个示例中,我们首先从scikit-learn库中加载了iris花卉数据集,并将其划分为训练集和测试集。然后,我们创建了一个KNeighborsRegressor对象,并设置了K值为3。接下来,我们使用训练集对模型进行训练,并使用测试集进行预测。最后,我们计算了预测结果的均方误差。
文章来源:https://blog.csdn.net/u011775793/article/details/135789277
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!