【HDFS联邦(1)】ViewFs与联邦理论知识详解
文章目录
本文主要想讨论
HDFS ViewFs的(1)定义 与无联邦时的区别、(2)管理多集群的逻辑、(3)具体怎么使用ViewFs:比如跨集群任务、文件跨集群传输等。
一.ViewFs介绍
The View File System (ViewFs)提供了一种管理多个hadoop namespaces的方式,即集群中有多个namenode,也就是hdfs的联邦集群时特别有用。ViewFs类似于某些Unix/Linux系统中的客户端挂载表。ViewFs可创建个性化的名称空间视图和每个集群的公共视图。
Namespace(命名空间):命名空间是指 HDFS 中用于组织和管理文件和目录的层次结构。
NameNode :负责管理文件系统的命名空间和控制文件的访问。
本文描述了hadoop系统有多个集群的内容,即每个集群可以联合到多namespaces中。
同时描述了如何在HDFS联邦集群中使用ViewFs来提供每一个集群的namespace,以便任务或应用在联邦集群中访问单个hdfs集群,称为pre-federation world。
?
二. 联邦之前的旧世界
1. 单个 namenode集群
HDFS Federation出现之前,一个集群中只有一个namenode,提供了单个namespace。
假设有多个集群。每个集群的文件系统名称空间完全独立,互不连接,并且物理存储不能跨集群共享(即datanode不能跨集群共享)。
在core-site.xml 中,配置每个集群中的namenode
<property>
<name>fs.default.name</name>
<value>hdfs://namenodeOfClusterX:port</value>
</property>
此配置实现了:通过相对名称便能访问集群中的路径。例如,路径/foo/bar引用的是hdfs://namendeofcluster:port/foo/bar。
?
2. 路径使用逻辑
配置了fs.default.name 之后,可以通过以下方式访问路径:
- /foo/bar
与hdfs://namenodeOfClusterX:port/foo/bar格式的路径,访问路径效果相同- hdfs://namenodeOfClusterX:port/foo/bar
有效的路径名,不过推荐使用/foo/bar,因为允许跨集群输出。- hdfs://namenodeOfClusterY:port/foo/bar
集群Y的有效路径。如下命令,实现从集群Y到集群Z的跨集群数据传输
distcp hdfs://namenodeClusterY:port/pathSrc hdfs://namenodeClusterZ:port/pathDest- webhdfs://namenodeClusterX:http_port/foo/bar
通过webhdfs文件系统访问数据的URI。注意:使用namenode的HTTP端口,而不是RPC端口访问数据。- http://namenodeClusterX:http_port/webhdfs/v1/foo/bar and http://proxyClusterX:http_port/foo/bar
通过 WebHDFS REST API 和 HDFS 代理访问文件的 HTTP URL。
?
?
三. 新世界 – 联邦与ViewFs
1. How The Clusters Look
场景假设
假设有多个集群。每个集群有一个或多个namenodes。每个namenode都有自己的namespace。一个namenode只能属于一个集群,同一集群中的namenode共享该集群的物理存储。集群间的namespace和以前一样是独立的。
根据存储需求可以在集群中不同的namenode存储数据。例如,
- 将所有用户数据(/user/< username >)放在一个namenode中;
- 将所有feed数据(/data)放在另一个namenode中;
- 将所有项目(/projects)放在另一个namenode中。
?
2. 使用 ViewFs 为每个集群创建全局的Namespace
为了不影响旧世界,ViewFs file system 为每个集群创建了一个独立的namespace view,即旧世界的namespace。可以使用旧世界的命名约定,挂载新的namespace volumes。
如下图:以“/user”、“/data”、“/projects”和“/tmp”四个namespace volumes为例,挂载表如图所示。
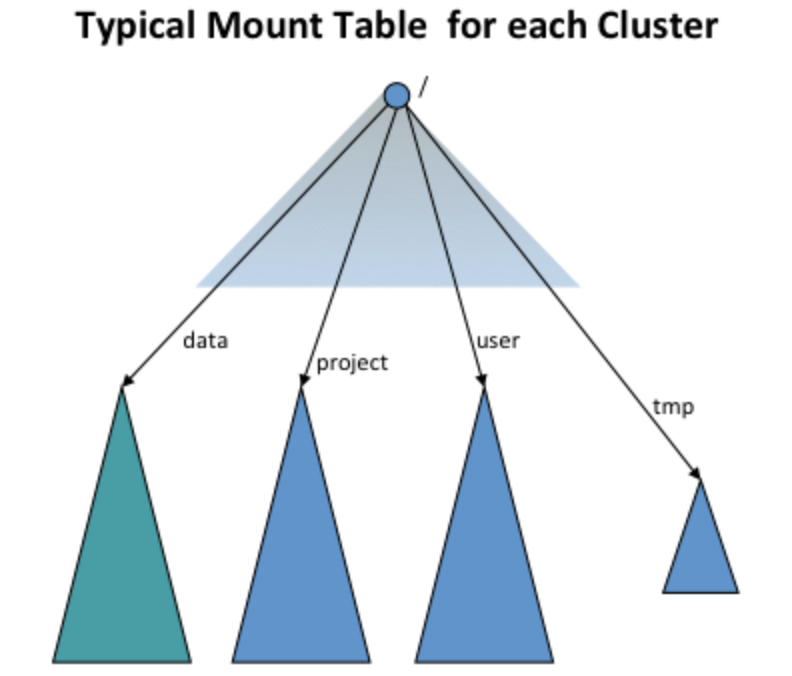
挂载表的设置
在每个集群的配置中,fs.defaultFS设置为集群的挂载表(ing)。
<property>
<name>fs.defaultFS</name>
<value>viewfs://clusterX</value>
</property>
viewfs:// 后面跟挂载表名,推荐使用集群名称来命名挂载表,比如clusterX。所有的网关和服务机器都会包含集群中所有的挂载表,这样每个集群拿到的都是自己的 default file system即fs.defaultFS。
?
挂载点的设置
-
挂载表的挂载点在hadoop配置文件中配置,挂载点的配置入口以
fs.viewfs.mounttable为前缀。挂载点通过使用link tags来连接其他文件系统。 -
建议将文件系统中链接的目标位置来命名挂载点。
-
对于有些namespace没有配置到挂载表中,通过linkFallback可以获取没在挂载表中的namespaces。
例子:
在下面的挂载表配置中,
- /data命名空间链接到文件系统hdfs://nn1-clusterx.example.com:8020/data,
- /project链接到文件系统hdfs://nn2-clusterx.example.com:8020/project。
- 所有未在挂载表中配置的命名空间,如/logs,都链接到文件系统hdfs://nn5clusterx.example.com:8020/home。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://nn1-clusterx.example.com:8020/data</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./project</name>
<value>hdfs://nn2-clusterx.example.com:8020/project</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://nn3-clusterx.example.com:8020/user</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn4-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://nn5-clusterx.example.com:8020/home</value>
</property>
</configuration>
- 我们还可以使用linkMergeSlash,将一个挂载表的
root filesystem与另外一个文件系统的root filesystem合并到一起,如下:将ClusterY’s的根与hdfs://nn1-clustery.example.com:8020.的root filesystem合并到一起。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterY.linkMergeSlash</name>
<value>hdfs://nn1-clustery.example.com:8020/</value>
</property>
</configuration>
?
2. 路径使用逻辑
因此对于集群X,core-site.xml 设置的default fs 作为集群的挂载表,典型的路径如下:
- /foo/bar
路径等同于:viewfs://clusterX/foo/bar.。如果这样的路径/foo/bar用于无联邦的环境下,它将会转换为联邦环境。- viewfs://clusterX/foo/bar
是一个有效的路径名称,推荐使用/foo/bar,因为允许传输数据时到另外一个集群。- viewfs://clusterY/foo/bar
Cluster Y的路径URI。特别的跨集群传输文件时,使用如下命令:
distcp viewfs://clusterY/pathSrc viewfs://clusterZ/pathDest- viewfs://clusterX-webhdfs/foo/bar
WebHDFS file system的路径URI- http://namenodeClusterX:http_port/webhdfs/v1/foo/bar and http://proxyClusterX:http_port/foo/bar
与之前相同:通过 WebHDFS REST API 和 HDFS 代理访问文件的 HTTP URL。
?
3. 路径使用最佳实践(ing)
当位于集群内时,建议使用上面类型 (1) 的路径名,而不是像 (2) 这样的完全限定 URI。此外,应用程序不应使用挂载点的知识,也不应使用 hdfs://namenodeContainingUserDirs:port/joe/foo/bar 之类的路径来引用特定名称节点中的文件。应该使用 /user/joe/foo/bar 来代替。
?
?
?
参考:【hadoop】ViewFs Guide
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 水果音乐编曲软件 FL Studio v21.2.2.3914 中文免费版(附中文设置教程)
- 【python】搭建自己专属的工具包,供import调用
- Taro+vue3 实现滑动列表 时切换电影
- 基于LSTM神经网络结构模型的北京空气质量预测实验报告含python程序源代码
- c++关联容器详细介绍
- C++ 得分后,可以排名和删除排名相关操作的贪吃蛇
- 神经网络:开放性问题
- NPM介绍与使用
- Java研学-Servlet 进阶
- 【神经网络】火箭点火发射-诠释一场数据与学习的奇妙之旅