【从零开始学习Redis | 第七篇】利用Redis构造全局唯一ID(含其他构造方法)
目录
?
前言:
? ? ? ? 在各种实际业务中,全局唯一ID是一个重要的存在,它用来标识用户的特定服务,方便用户在后续基于这个ID来进行各种服务。而如何构造全局唯一ID也是一个比较重要的知识点。因此今天来介绍一下如何基于Redis构造全局唯一ID。

什么是全局唯一ID??
????????全局唯一ID(Global Unique Identifier,简称GUID)是在计算机系统中用于唯一标识实体或对象的标识符。它通常由一个128位的数字字符串组成,采用特定的算法生成,以确保在相同的算法和生成器设置下几乎不会重复。
让我们回到业务中:
每个店铺都可下发自己店铺的优惠卷,当用户抢购的时候,就会生成订单到订单表中,并且返回订单号给用户。但是如果只是使用简单的数据库自增就会出现问题:
????????1.少量数据下,采用数据库自增的方式,会泄漏信息给用户。用户可以根据订单ID推测出优惠卷的订单数,可能会引发恶意行为。
????????2.大量数据下,如果所有的订单都在一个张表中,在进行SQL查询的时候效率会大大降低,并且如果我们进行了分表,那么多个订单表中间的数据库自增是隔离的,并不能保证多表下的ID唯一。
????????那么我们目前可以知道:如果要追求ID的唯一性,那么就应该避免在数据库中进行ID的构造。基于这种情况,那么我们就把ID的构造放到Redis中进行。
尝试构造全局唯一ID:?
而为了增加ID的安全性,我们也不直接使用Redis的自增数值,而是再拼接一些其他的信息:

由图可看得,我们设计的ID一共分为三部分:
1.符号位:永远为0,标识我们的ID是一个整数。
2.时间戳:从自定义时间开始,按秒计算。那么32位我们大约可以使用60多年。
3.序列号:同一时间内下单进行自增。在时间戳相等的形况下的区分不同的订单。
代码实现:
public long nextId(String keyPrefix) {
//1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowhSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowhSecond - BEGIN_TIMESTAMP;
//2.生成序列号
//1.获取日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
Long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
return (timestamp << COUNT_BITS) | count;
}?在这里我们唯一需要讲的就是返回结果中的(timestamp << COUNT_BITS) | count:
? ? ????????? ? 其实是他就是一个拼接序列号的过程,只不过相比较于符号运算来讲,使用位运算的效率更高。
其他构造全局唯一ID的方法
1.基于数据库自增构造全局唯一ID:
?基于数据库自增构造ID,之前我们讲了主要的难点是:分表之后无法统一构造自增唯一ID,多个订单表在构造ID的时候可能会出现重复。
那么其实解决方案很简单:既然多个表在构造ID的时候会出现重复问题,那么我们就不要在订单表中构造ID了,创建一个订单ID表去专门维护ID。
比如我们可以这样设计一个订单ID表:
create table order_test.order_id
(
id int auto_increment
primary key,
name varchar(20) null,
constraint name
unique (name)
);
那么我们就得到了这样一张表:

在查询的时候,我们使用这样一条语句:
begin ;
replace into order_id (name) values ("order_id");
SELECT last_insert_id();
COMMIT ;?这样我们基于name的唯一性,就做到了对id的自增:

?但是这种创建一张表去维护订单ID的方式仍然是有问题的:高并发场景下,万一这张表挂了怎么办?
所以为了优化,我们还可以采取多表的思想:
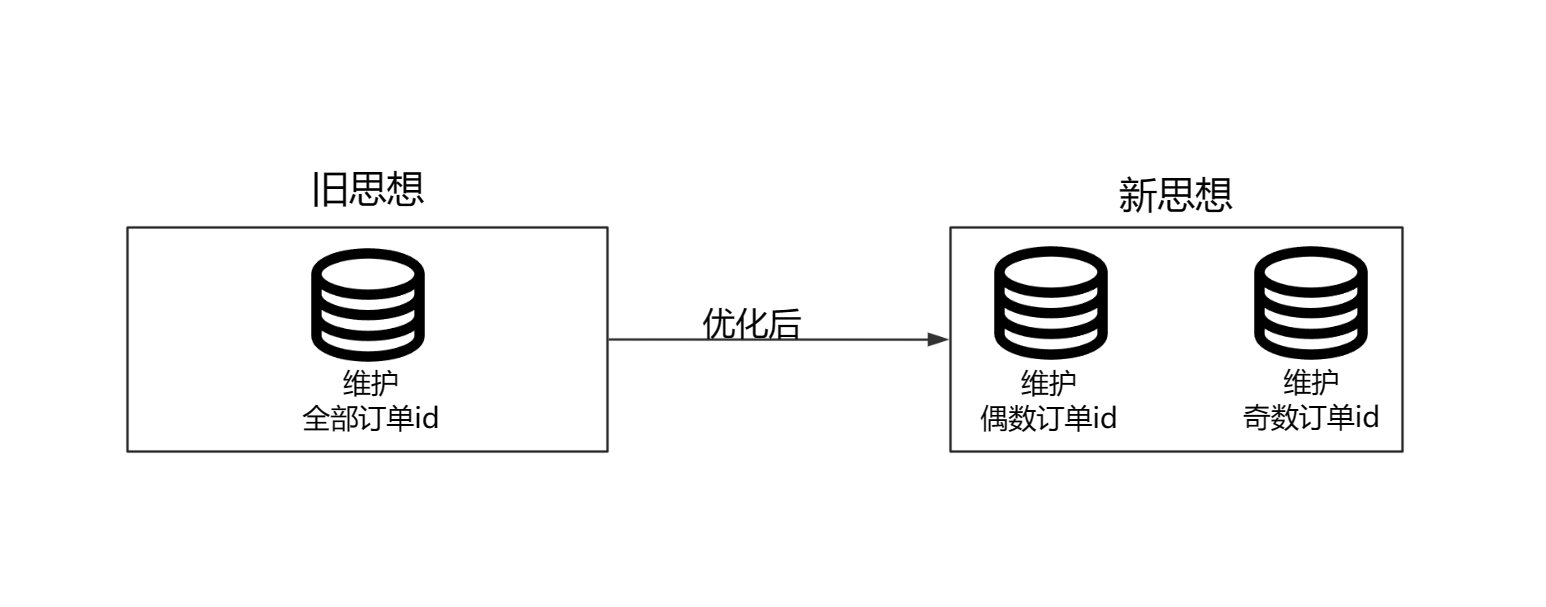
在新思想中,我们让一个表维护订单id为偶数,一个表维护订单id为奇数。这样的话,我们就是实现了减轻单表压力。而且这种思想是可以不断的改进的,我们可以通过让表维护不同类型的数字来不断的拆表,减轻单表压力
但是这种方法得到的订单id,他不一定是逐个递增的,只能说是整体呈现递增趋势。
而且这种方式如果要抵抗高并发的话,就要不断的去加数据库,对维护数字进行分类。因此这种方式其实缺点还是比较明显的。
但其实基于数据库构造全局唯一ID是有成熟的方案的:美团的LEAF数据库方案,原文链接我也留在这里:
Leaf——美团点评分布式ID生成系统 - 美团技术团队 (meituan.com)![]() https://tech.meituan.com/2017/04/21/mt-leaf.html????????LEAF数据库方案简而言之就一句话:批量获取ID进行处理。在上文我们简单的对数据库进行优化的时候,优化问题基本都来源于高并发下数据库高频的读写操作。而LEAF数据库方案也是针对这个方面进行优化的。
https://tech.meituan.com/2017/04/21/mt-leaf.html????????LEAF数据库方案简而言之就一句话:批量获取ID进行处理。在上文我们简单的对数据库进行优化的时候,优化问题基本都来源于高并发下数据库高频的读写操作。而LEAF数据库方案也是针对这个方面进行优化的。
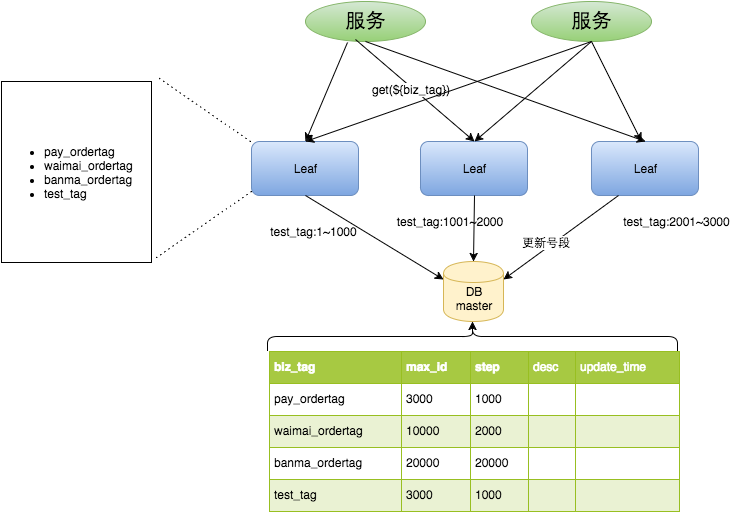
我们可以把图中的leaf简单的理解为是一个生成全局唯一ID的服务。那么整个LEAF数据库的思想就是:leaf服务提前就拿好一批号端,例如从0-1000。那么我在生成唯一ID的时候,压力就从数据库转到了Leaf这个服务里面。
优点:
????????1.leaf只是一个简单的web服务,方便进行扩展。
????????2.ID号也满足趋势递增的要求
????????3.容灾性高,由于生成唯一ID的是leaf服务,而且内部有号段缓存,因此即使数据库挂了,短时间内也可以正常对外提供服务
缺点:
????????当所有的leaf用完自己的号段之后,就会向数据库再次请求号段,此时leaf服务是不可用的。而如果此时有大量的请求leaf服务,就会引发一段尖刺。
解决方案:
? ? ? ? 我们并不会等到号段全部用完之后再去请求新的号段。美团给出的技术方案是当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。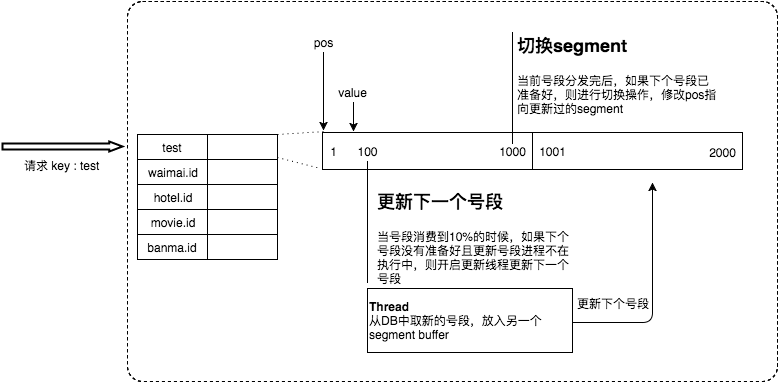
????????一开始先用A号段,等 A号段消耗10%的时候,就向数据库请求新号段。之后当前号段消耗完之后就可以进行快速的切换。如此循环往复。
2.基于UUID构造全局唯一ID:
虽然基于UUID可以保证构造ID的唯一性,但是UUID是随机生成的数字+字母。这使得UUID构造出的ID不具备递增性,在做数据库索引的时候效率比较慢。
而且UUID也存在安全性问题:UUID有一版是基于MAC地址来构造唯一标识的,可能会有泄漏MAC地址的风险。
import java.util.UUID;
public class UUIDExample {
public static void main(String[] args) {
// 生成随机的UUID
UUID uuid = UUID.randomUUID();
System.out.println("随机生成的UUID: " + uuid.toString());
// 根据字符串生成UUID
String uuidString = "38400000-8cf0-11bd-b23e-10b96e4ef00d";
UUID fromString = UUID.fromString(uuidString);
System.out.println("从字符串生成的UUID: " + fromString.toString());
}
}
3.基于雪花算法构造全局唯一ID:
六十四位雪花算法构成:

其实可以看出,雪花算法跟我们上文提到的基于Redis生成全局唯一ID的思路是一样的。因此这里不做赘述。
而基于雪花算法,最常问的一个面试问题就是:如何解决时间回拨问题?
其实就是说:如果时间戳回拨了,我们要如何处理?因为时间戳回拨之后,生成的id就有可能和以前的重合,那么我们要如何进行处理呢?
大部分的开源版本的雪花算法面对时间回拨问题采用的是抛异常的处理方法,其实我感觉这属于是没处理。
比较好的处理方法是根据回拨时间的长短来个性化处理方案:
????????1.回拨时间很短(<=100ms):直接睡眠当前线程,等到时间戳加载正常之后再生成ID
????????2.回拨时间适中(>100ms<=1s):寻找当前回拨时间毫秒内的最大id,直接沿着那个id++就可以。
????????3.回拨时间较长(>1s<=5s):创建多个雪花算法服务,当前使用的雪花算法服务时间戳发生回拨就换一个。
????????4.回拨时间很长(>5s):直接下线服务,人工介入手动调试时间戳。
除此之外,我们还可以提前就预留好一部分的分布式ID,在时间戳回拨之后,我们使用这部分预留的分布式ID,直至时间戳恢复正常。
总结:
当我们在设计分布式系统时,唯一ID的生成是一个非常重要的问题。为了保证分布式环境下ID的唯一性和无序性,我们可以采用雪花算法、UUID、数据库自增等方式生成唯一ID。
其中,雪花算法是目前应用最广泛的分布式ID生成算法之一。它通过使用时间戳、机器ID和序列号来生成64位的唯一ID,可以在多个节点上生成ID而不会重复。
除了ID的生成算法外,还需要考虑时钟回拨问题、ID的长度、ID的可读性等问题。为了解决时钟回拨问题,我们可以采取物理时钟、NTP同步、预留ID范围等方式;
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 介绍 Apache Spark 的基本概念和在大数据分析中的应用
- 记chrome的hackbar无法post php://input的问题
- 【华为OD】C卷200分真题:石头剪刀布游戏 100%通过 JS源码实现 [思路+源码]
- 激光打标机:快速、精确、耐用的标记解决方案
- RHEL8中ansible的使用
- 最详细的ubuntu 安装 docker教程
- 【AIGC-图片生成视频系列-6】SSR-Encoder:用于主题驱动生成的通用编码器
- LauraGPT
- 可靠且免费的数据恢复软件EasyRecovery2024
- 记录汇川:H5U与Fctory IO测试8