基于Python实现二手房整体情况可视化分析+房价预测【500010099】
发布时间:2024年01月04日
项目描述
通过房天下兰州二手房信息,对数据进行进一步清洗处理,分析各维度的数据,筛选对房价有显著影响的特征变量,探索兰州二手房整体情况、价格情况和价格的影响因素,建立房价预测模型。
提出问题
- 探究单价、数量、总价和行政区域之间的关系
- 探究其它因素和总价的关系
- 户型分布
- 分析建筑年代情况
- 使用机器学习模型建立回归分析模型进行价格预测
数据理解
导入模块
import pandas as pd
import numpy as np
import random
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Lasso
from sklearn.ensemble import RandomForestRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
import numpy as np
获取数据
# 获取数据
df = pd.read_csv('./data/house.csv', encoding='gbk')
数据分析处理
## 1)数据总体情况
print(f'样本量共有 {df.shape[0]} 个')

## 2) 判断是否有重复项
df.duplicated().sum()

## 3) 判断是否有缺失值
df.isnull().sum()

## 4) 查看数据类型
df.dtypes

## 4) 唯一标签值
print(df['朝向'].unique())
print(df['楼层'].unique())
print(df['装修'].unique())
print(df['产权性质'].unique())
print(df['住宅类别'].unique())
print(df['建筑结构'].unique())
print(df['建筑类别'].unique())
print(df['区域'].unique())
print(df['建筑年代'].unique())

初步探索性结果:
- 去重、缺失值处理
- 建筑面积、年代、单价需要进行转换(取掉单位)
- 楼层、区域需要进行数据整合
数据清洗
数据格式转换
# 数据格式转换
df.replace('暂无',np.nan,inplace=True)
df['建筑面积'] = df['建筑面积'].map(lambda x: x.replace('平米','')).astype('float')
df['单价'] = df['单价'].map(lambda x: x.replace('元/平米','')).astype('float')
def process_year(year):
if year is not None:
year = str(year)[:4]
return year
df['建筑年代'] = df['建筑年代'].map(process_year)
floor = {'低楼层': '低','中楼层': '中','高楼层': '高','低层': '低','中层': '中','高层': '高'}
df['楼层'] = df['楼层'].map(floor)
def process_area(area):
if area != '新区':
area = area.replace('区','').replace('县','')
return area
df['区域'] = df['区域'].map(process_area)
df.replace('nan',np.nan,inplace=True)
重复值处理
# 重复值处理
df.drop_duplicates(inplace=True)
df.reset_index(drop=True, inplace=True)
缺失值处理
# 缺失值处理
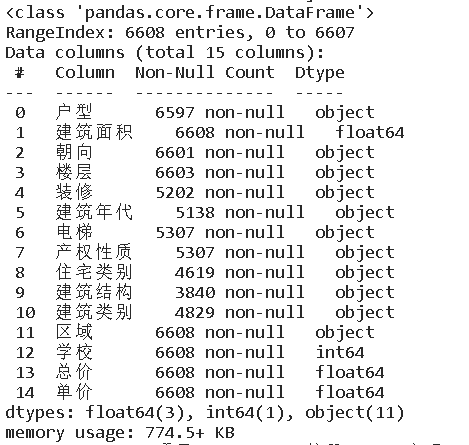
df.info()
数据可视化
箱线图分析
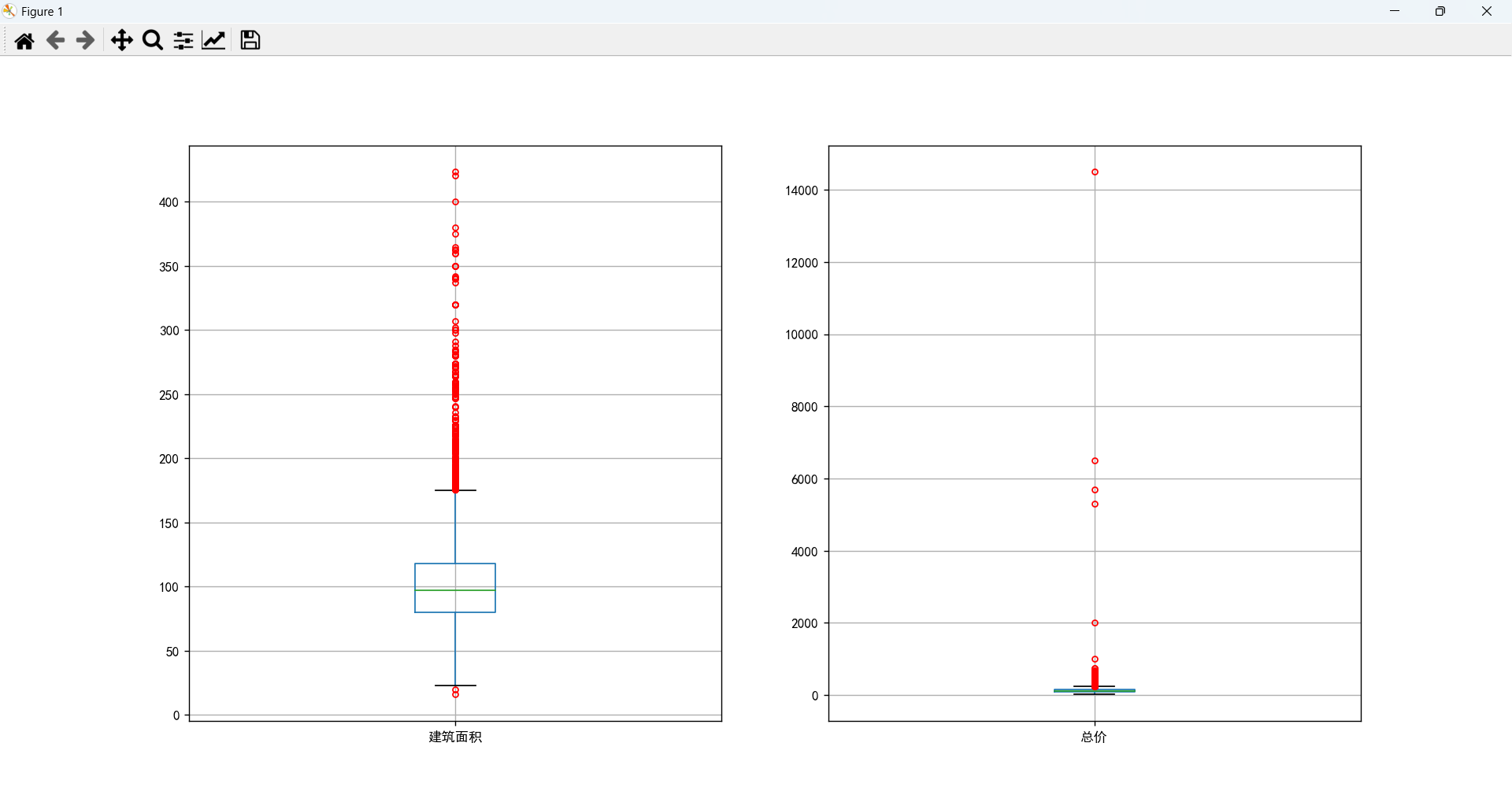
# 描述性分析
df.describe()

- 二手房最小面积为15.9平米,最大面积为423.43平米,最便宜的14万,最贵的14500万。
- 面积大概集中在80-118平米,价格大概集中在83-148万。
- 将总价高于上限的当作异常值进行处理(直接删除法),仅考虑大多数人可购买的情况。
# 将高于房价200万的删除
df.drop(index = df[df['总价'] > 200].index, inplace=True)
# 另存为新文件
df.to_excel('house.xlsx',encoding='utf8',index=False)
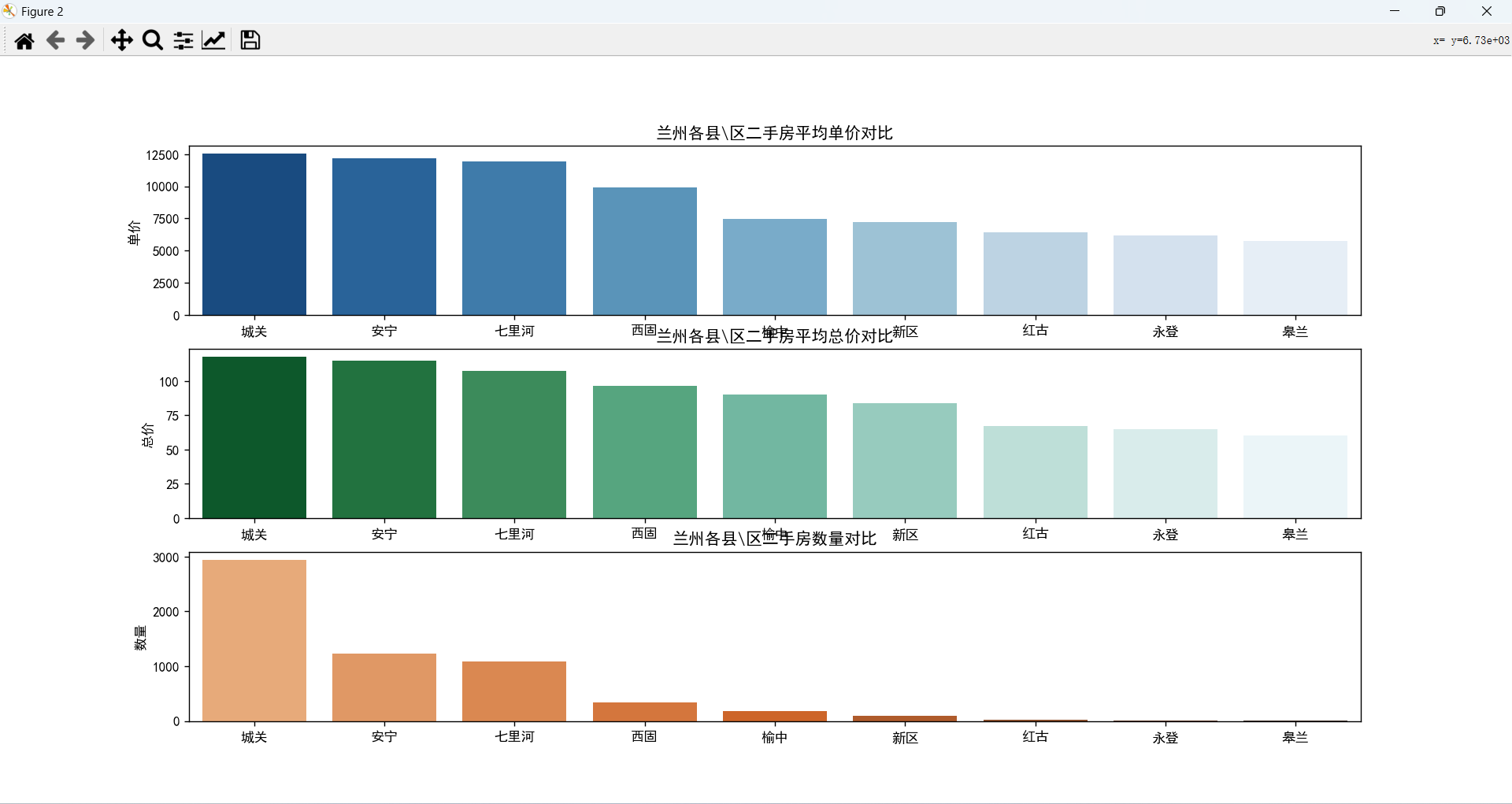
单价、数量、总价和行政区域之间的关系
各区二手房平均单价、总价、数量都是一样的排列顺序,最高的是城关区,最低的是皋兰县。
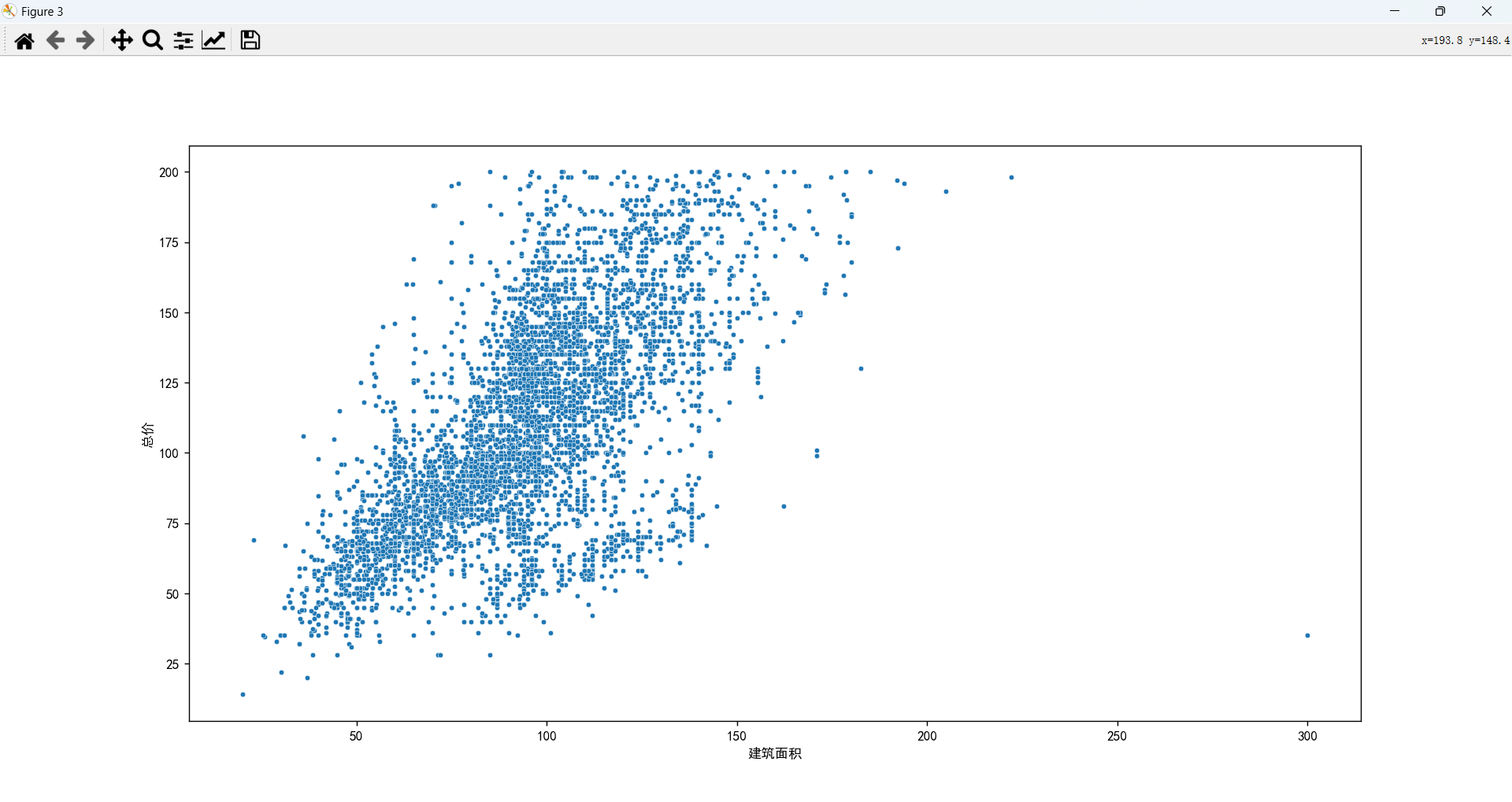
面积和总价的关系
基本服从面积越大,价格越高的关系。
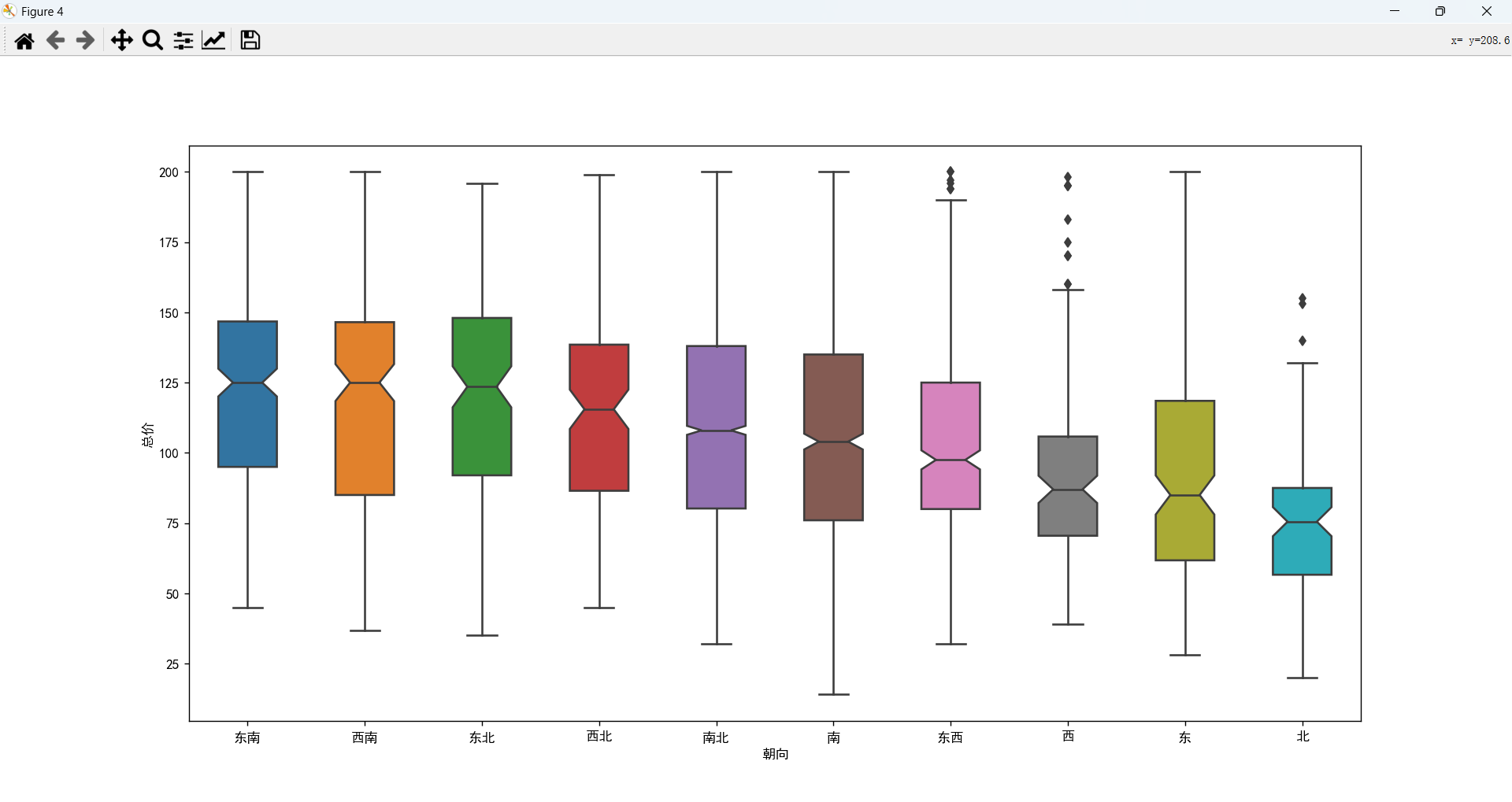
朝向和总价的关系
风水:人们在挑选房子时,经常喜欢挑坐北朝南的房子,因为这种房子采光好,顺光顺水,冬暖夏凉,很适合人居住。
包含南、北朝向方位的价格相对来说要贵一点。
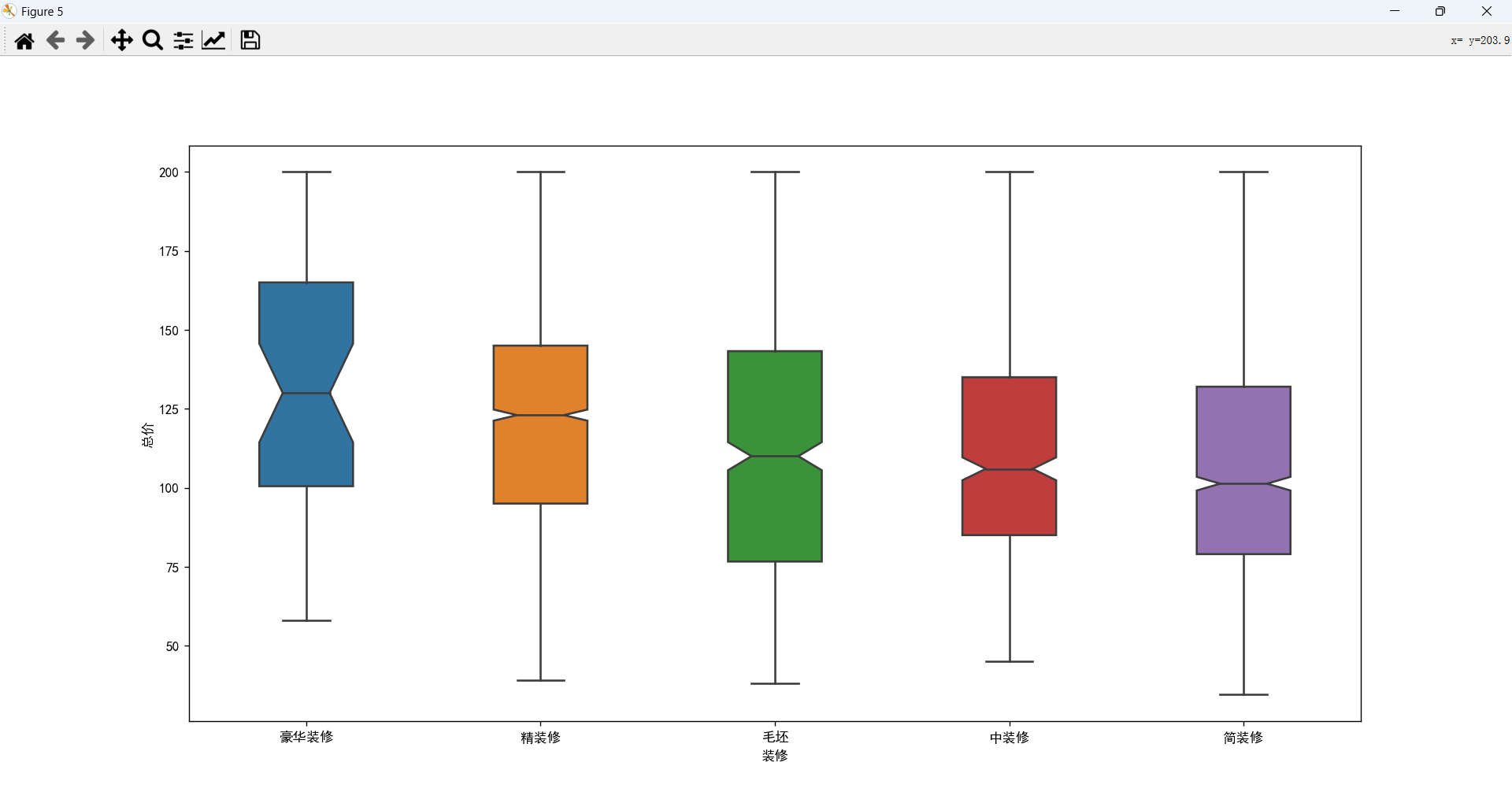
装修和总价的关系
不同装修信息对总价是有一定影响的,装修情况越好价格会偏高一点。
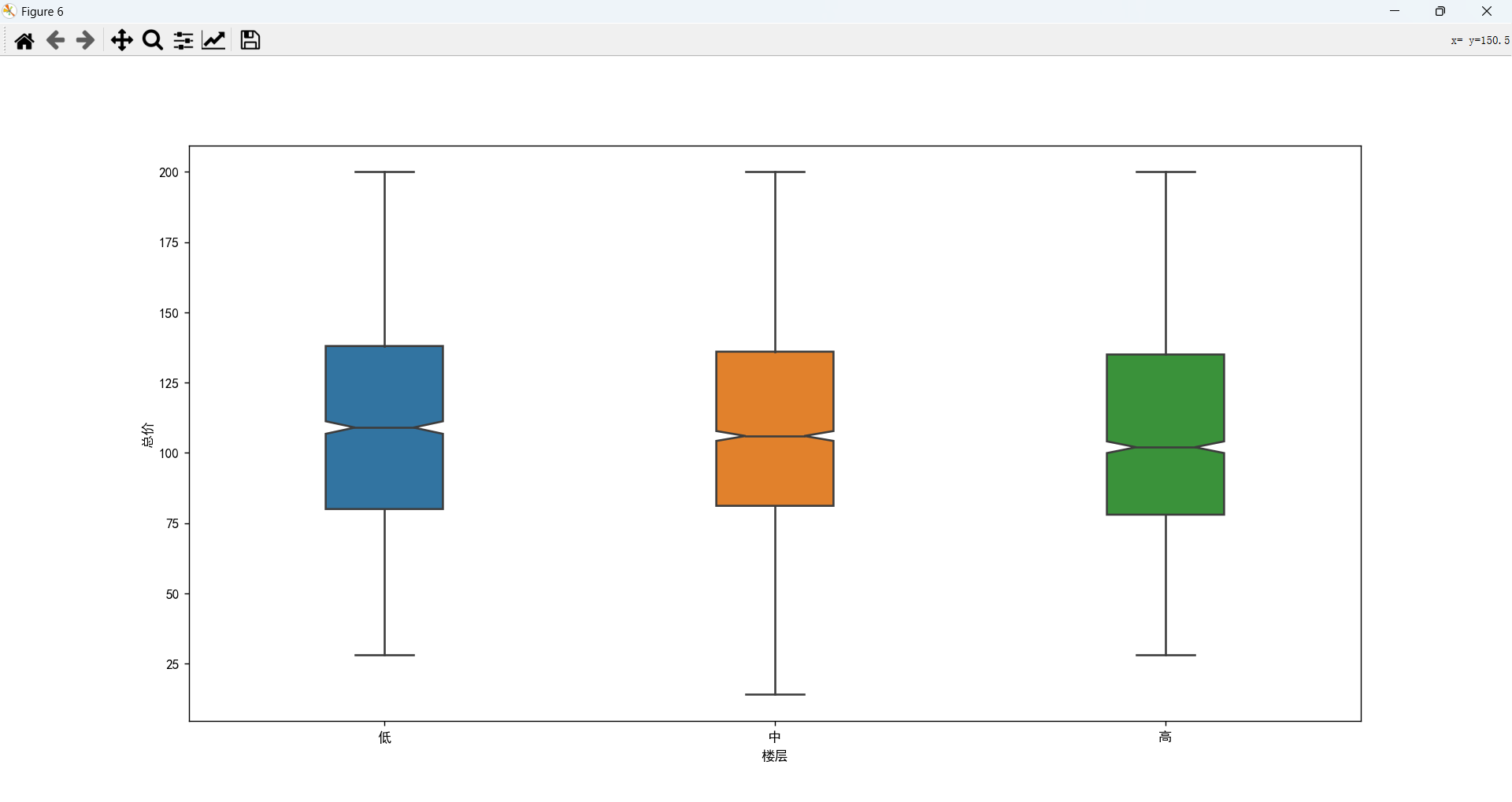
楼层和总价的关系
不同楼层对总价影响较小。
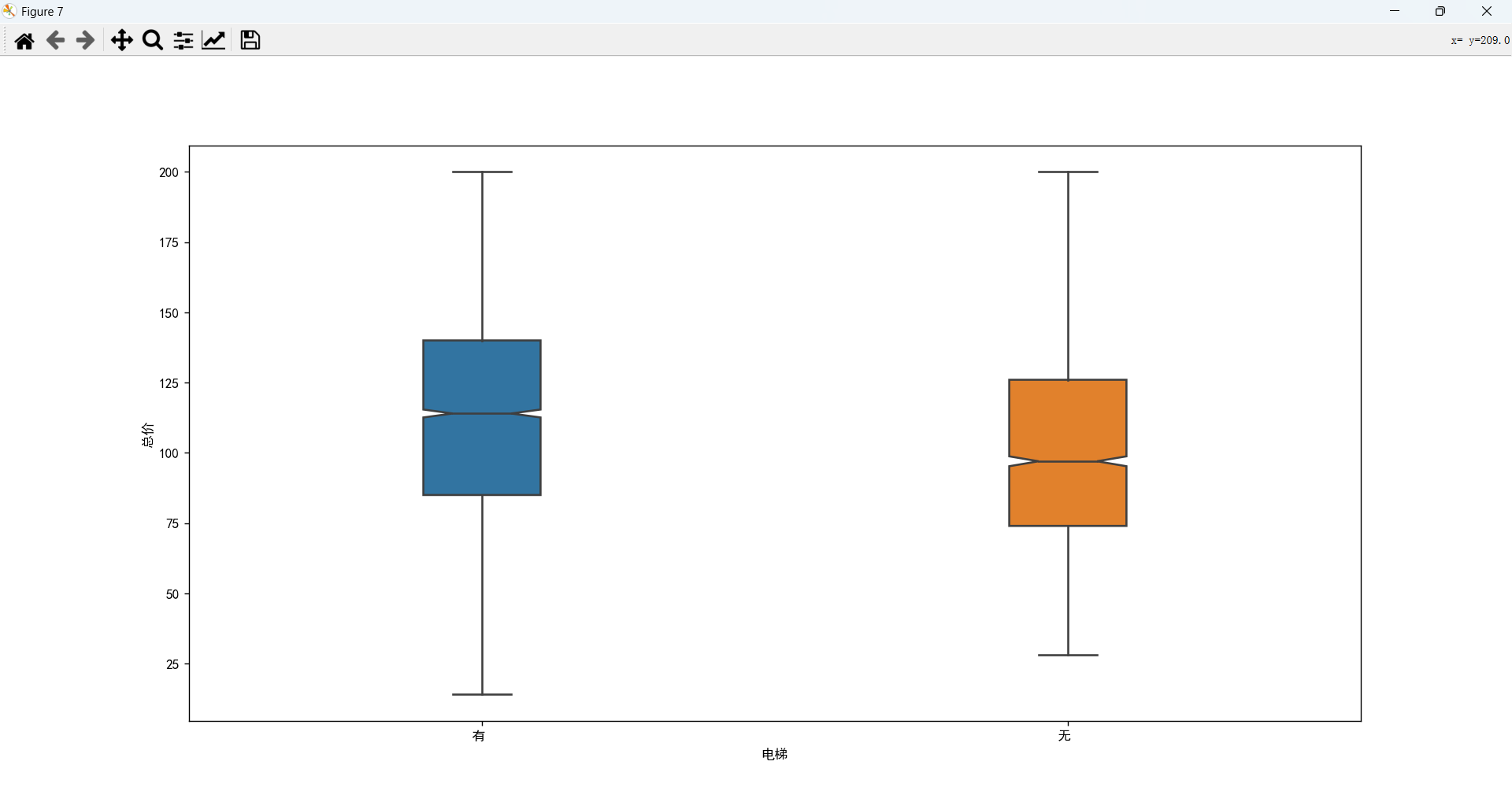
电梯和总价的关系
有电梯的房子比没电梯的房子要贵。
学区房和总价的关系
附近有学校的房子价格会高一些。
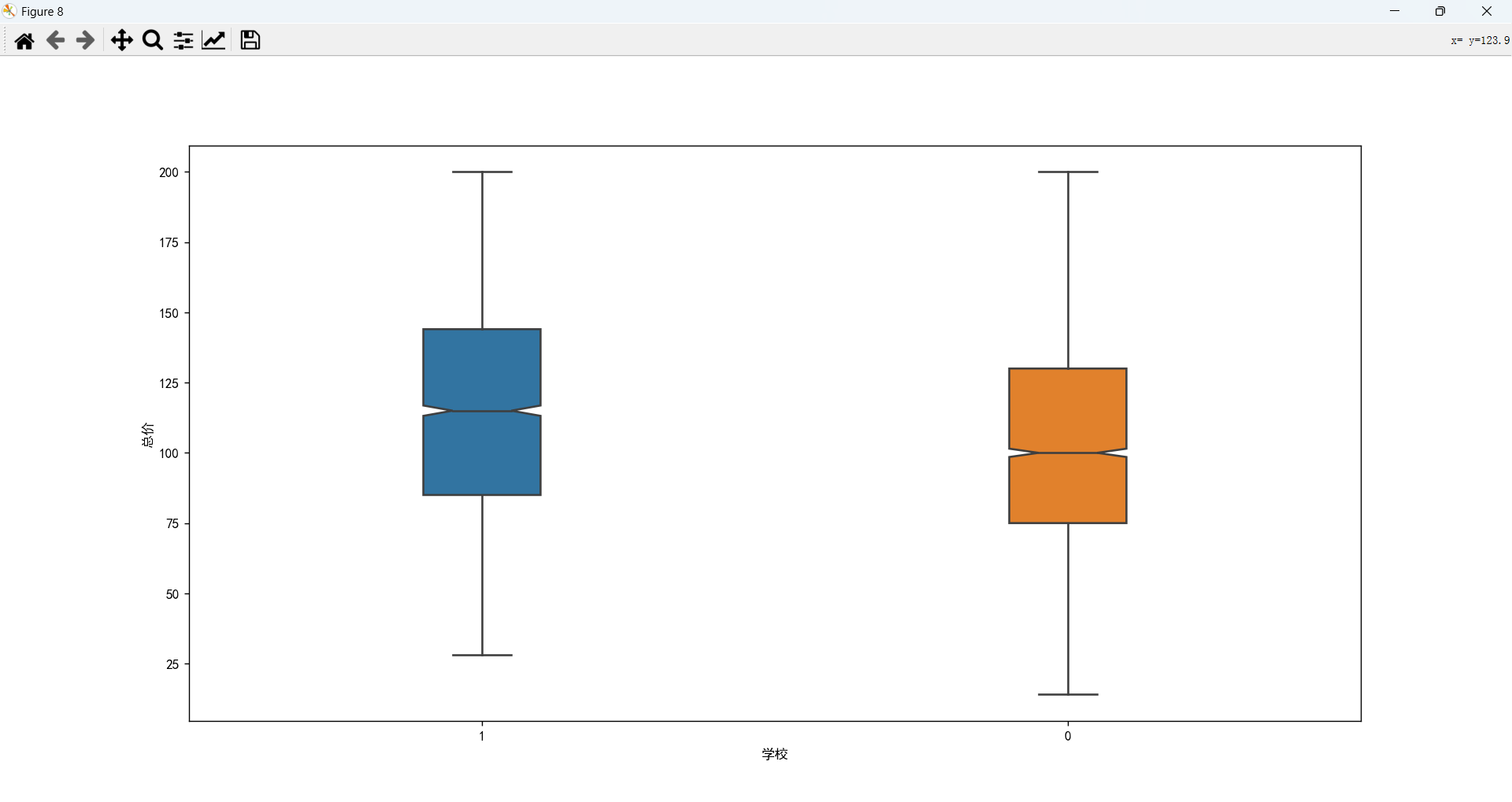
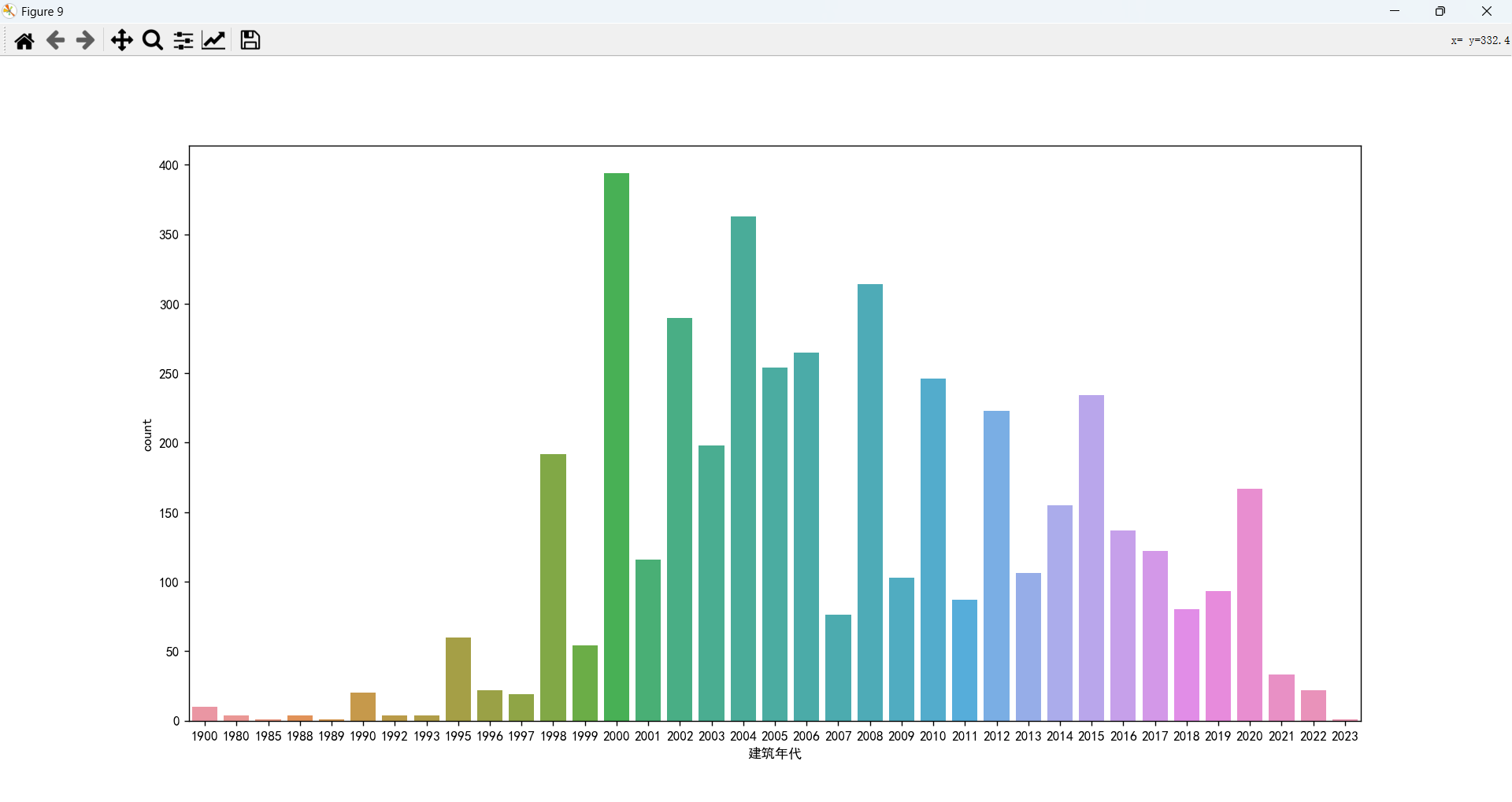
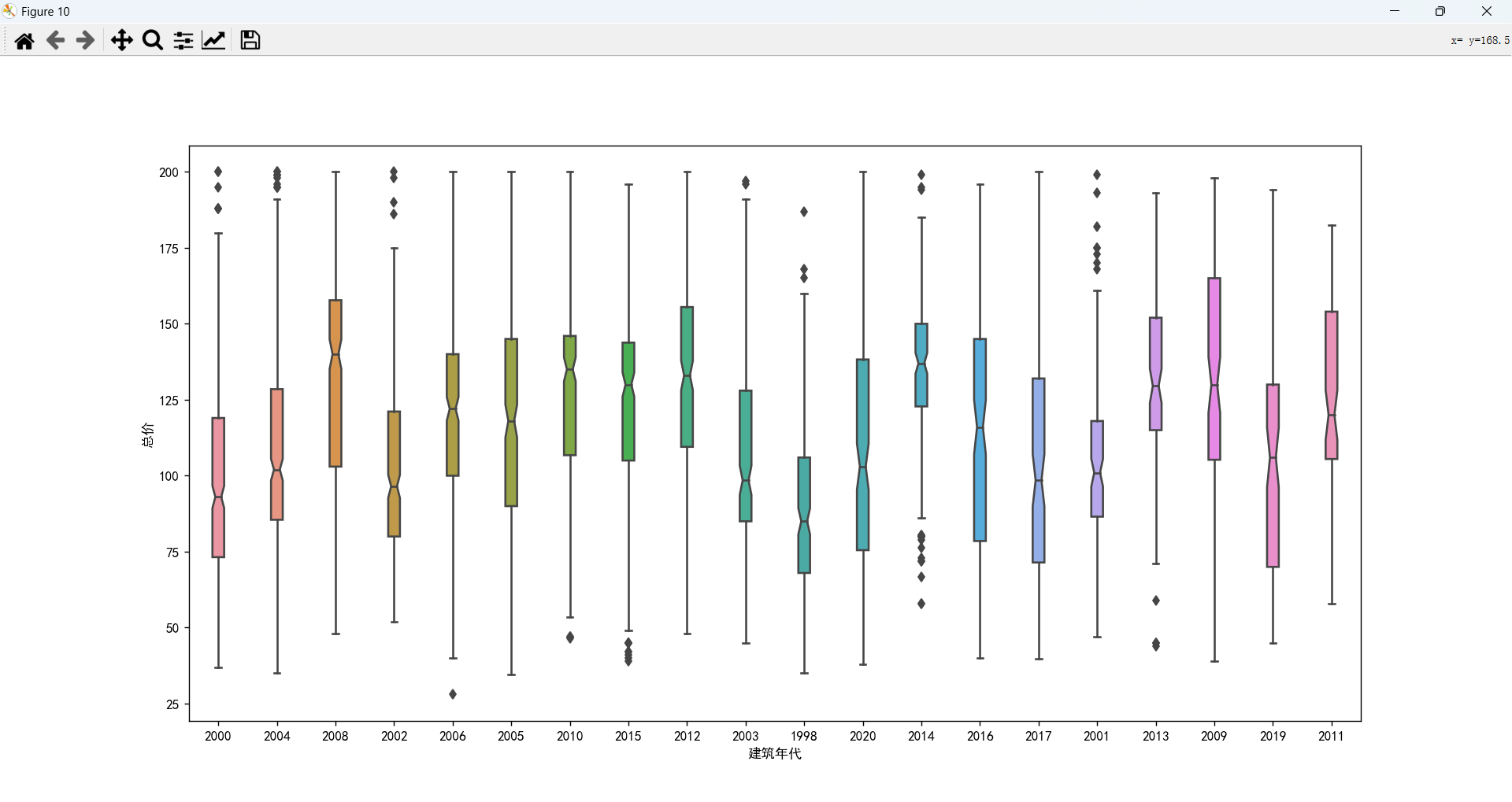
建筑年代情况分析以及和总价的关系
出售的二手房大都是十几年前的,比较符合现实情况,新房很少会有人出售的。
年代太久的房子价格会偏低,在2008年之后的房子价格会比较高,最新的房子(2017年之后)价格不如之前年代的。
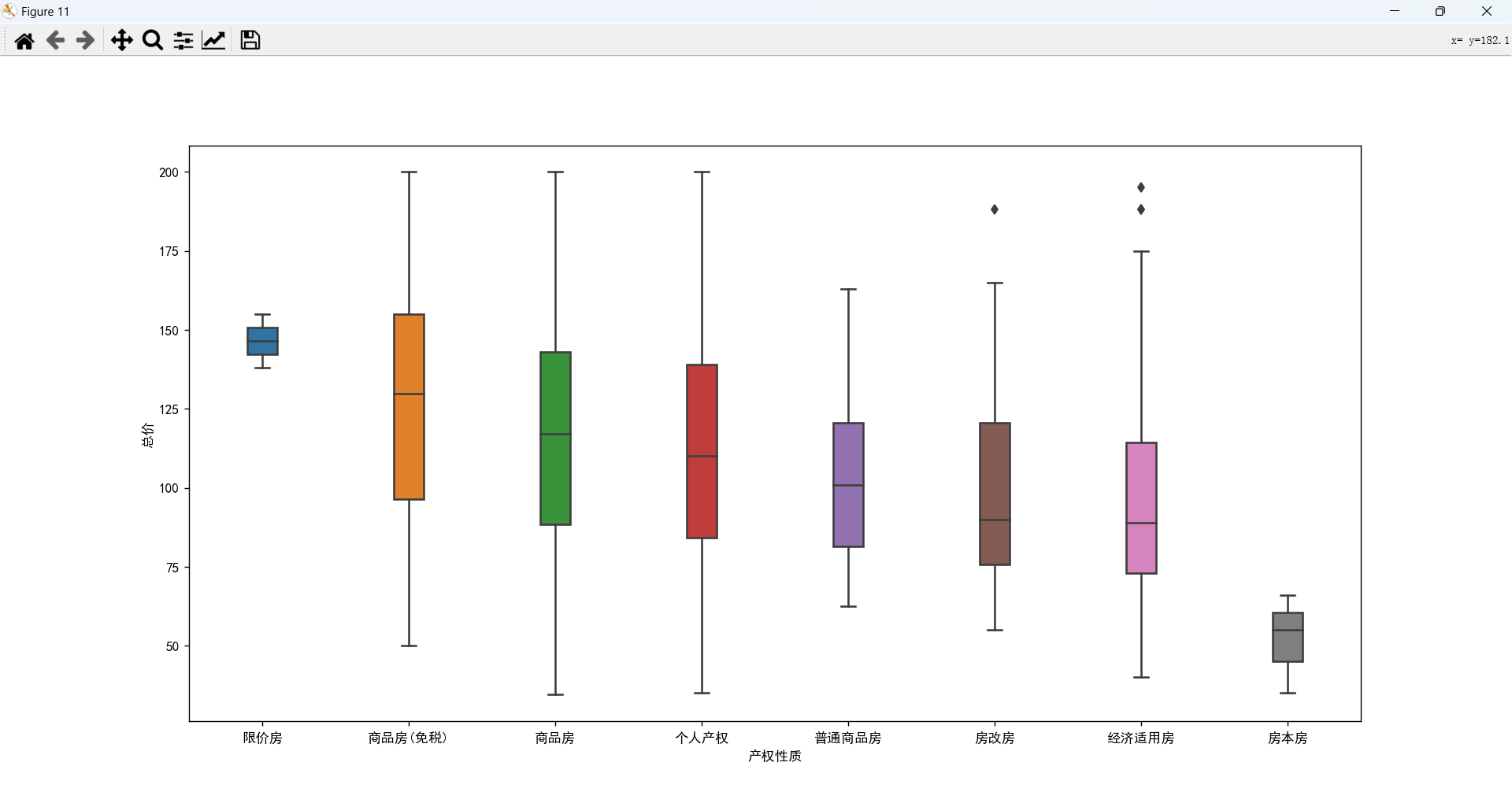
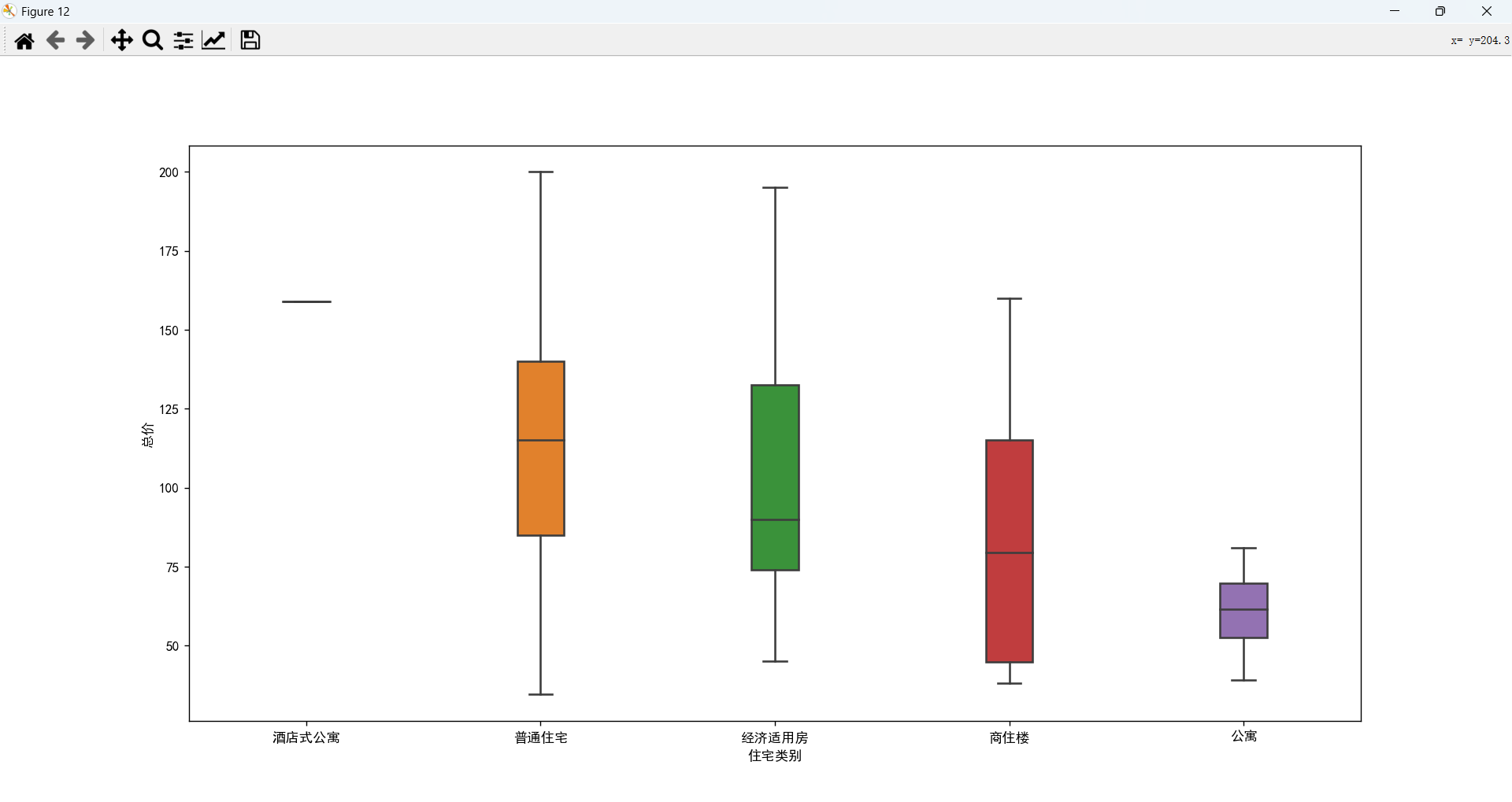
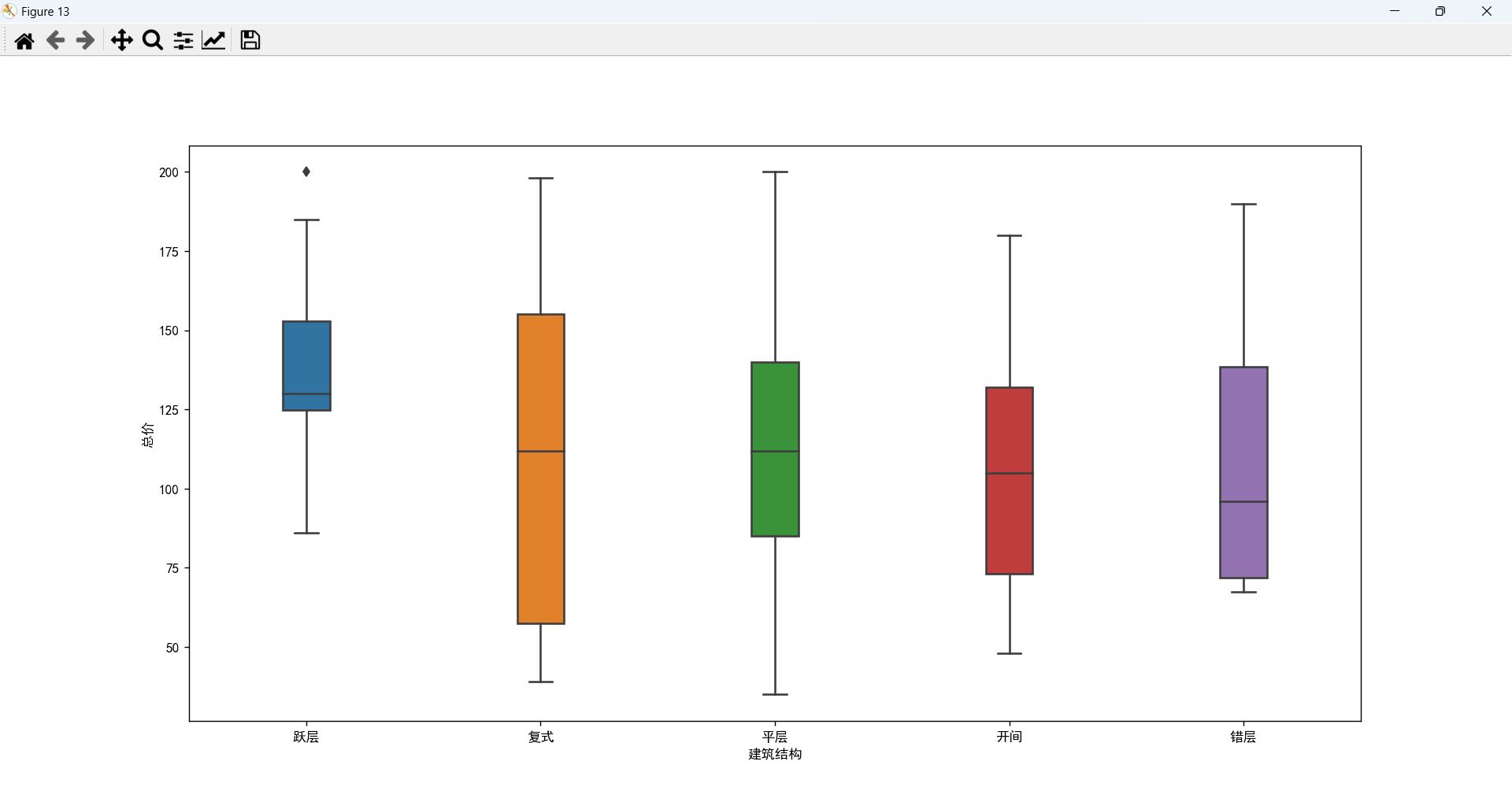
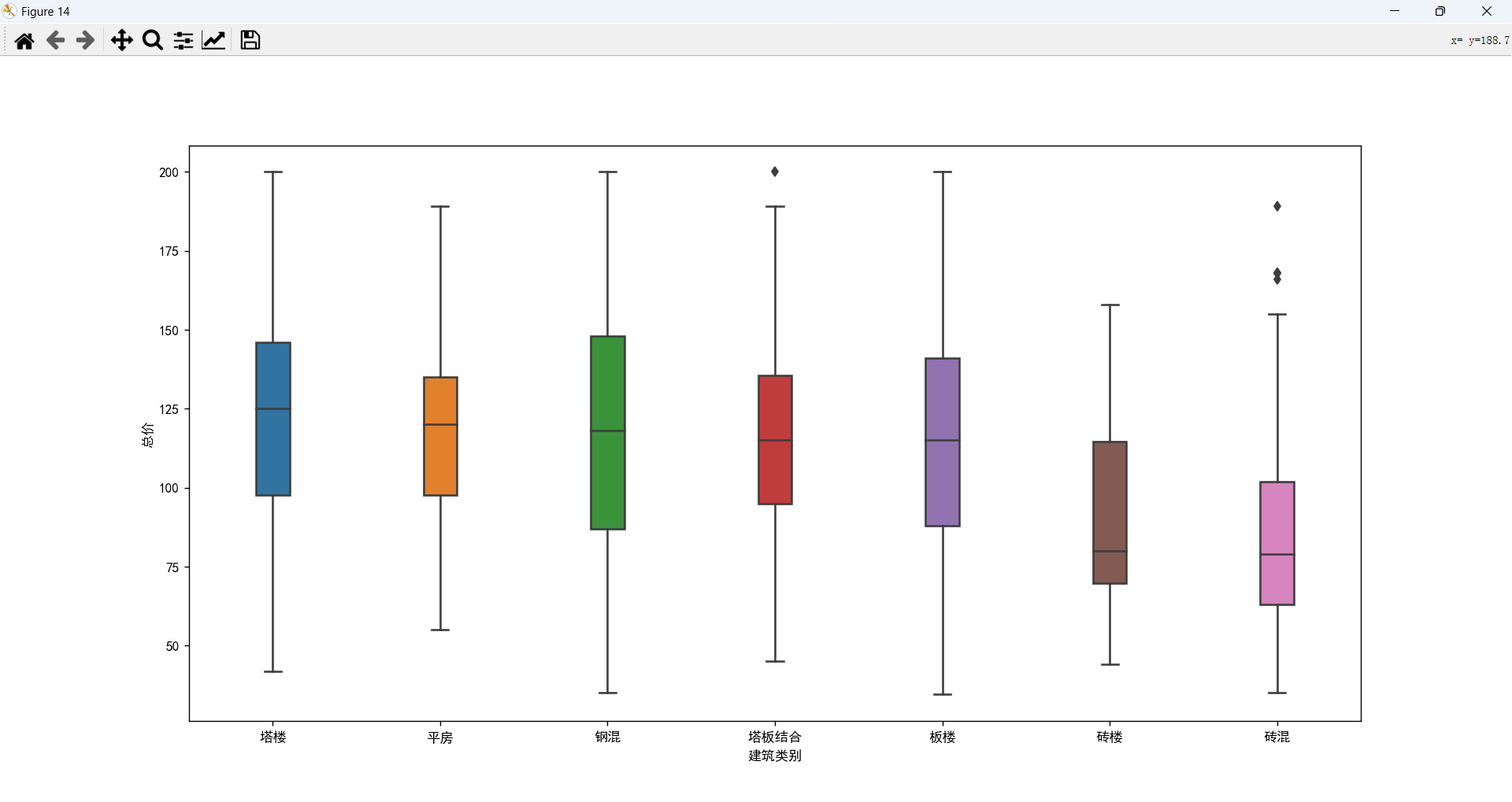
产权性质、住宅类别、建筑结构、建筑类别与总价的关系
产权性质、住宅类别、建筑结构、建筑类别对价格都有一定的影响力。
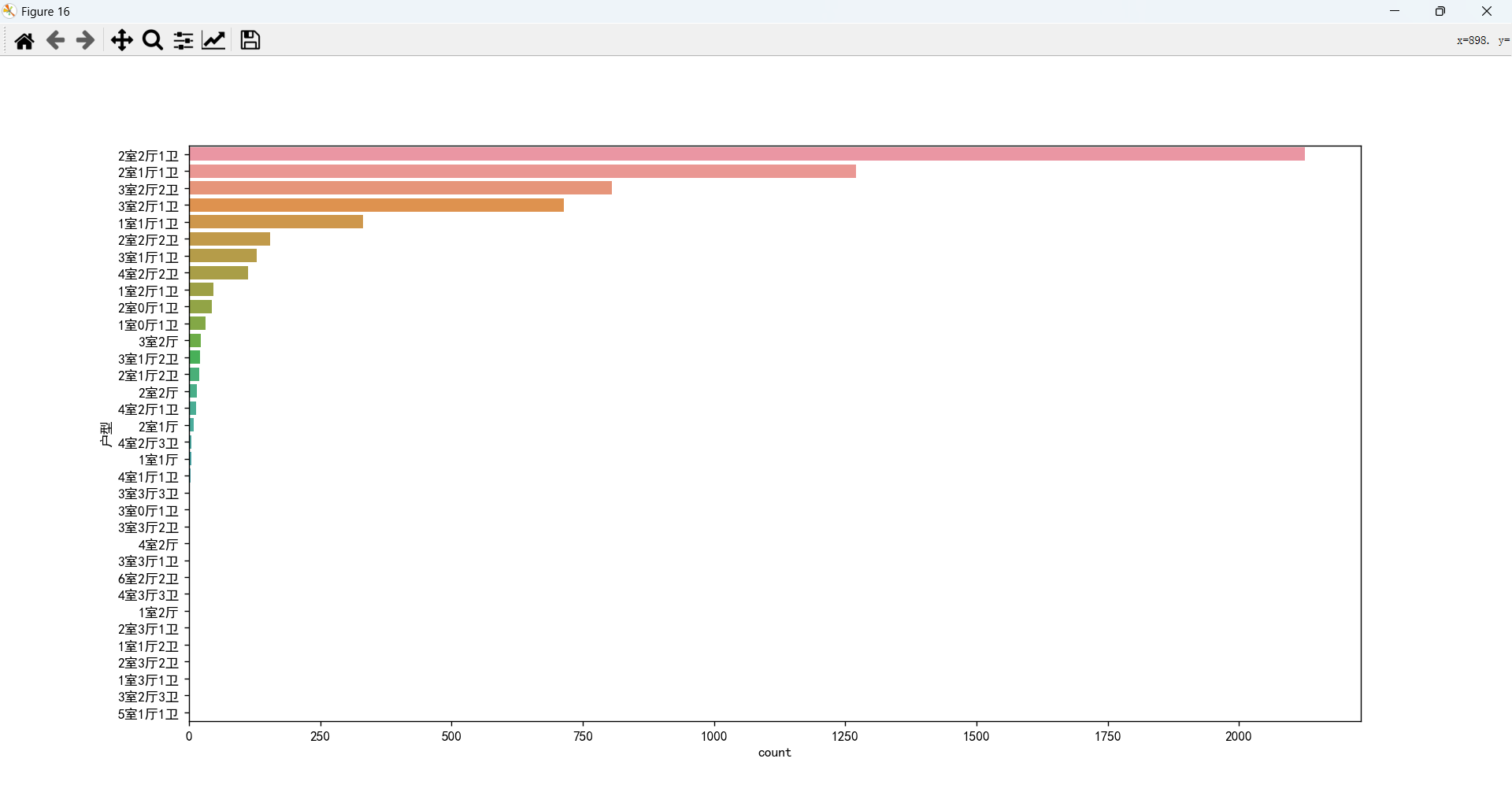
户型和总价的关系
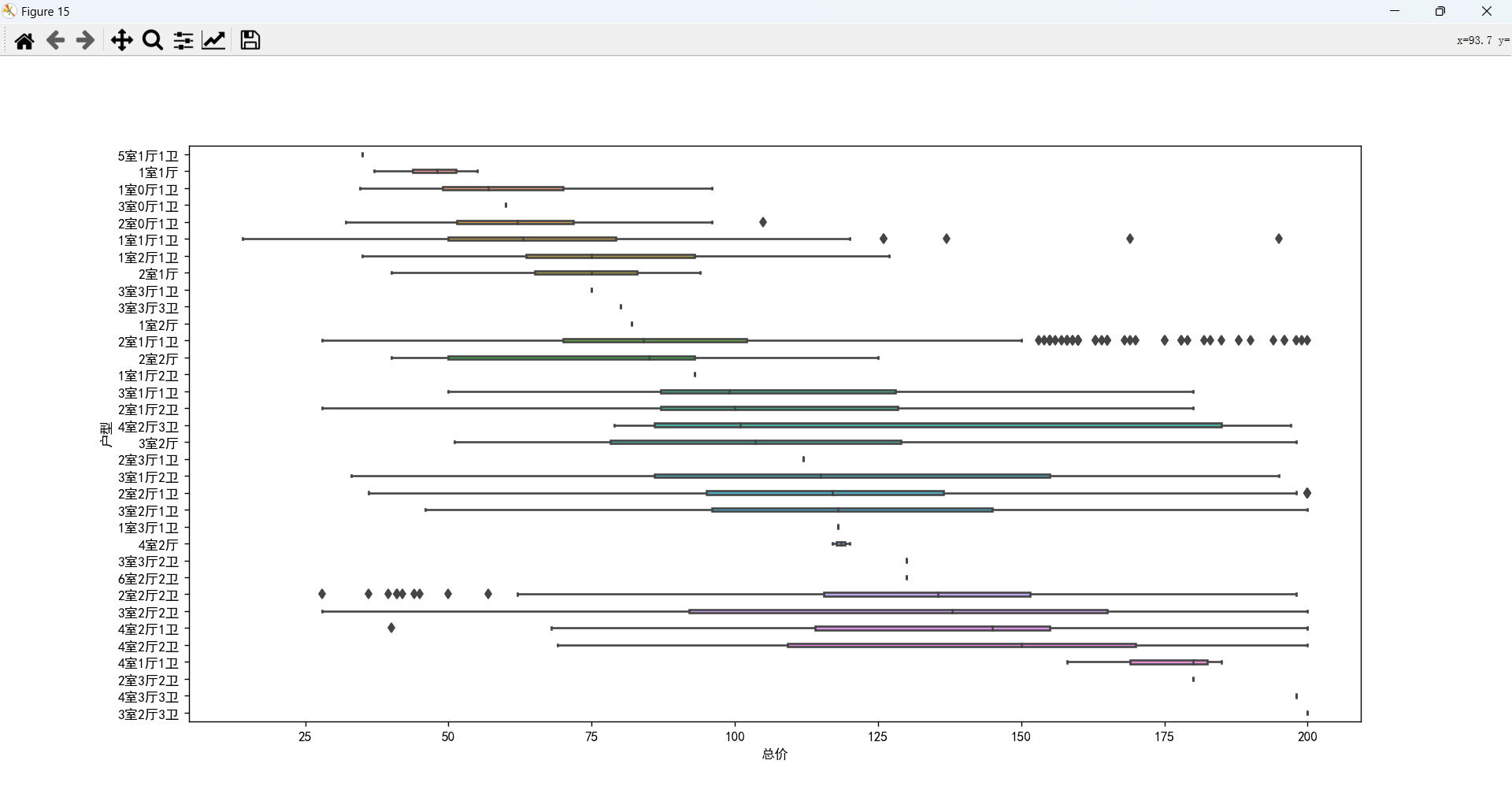
户型对总价影响比较大,不同的室、厅、卫又会产生不同的影响。
大多数需求集中在 2或3 室 1或2 厅 1或2 卫。
模型建立及预测
删除所有缺失值
# 删除所有缺失值
d1 = df.dropna().reset_index(drop=True)
分解户型
# 分解户型
def apart_room(x):
room = x.split('室')[0]
return int(room)
def apart_hall(x):
hall = x.split('厅')[0].split('室')[1]
return int(hall)
def apart_wc(x):
wc = x.split('卫')[0].split('厅')[1]
return int(wc)
d1['室'] = d1['户型'].map(apart_room)
d1['厅'] = d1['户型'].map(apart_hall)
d1['卫'] = d1['户型'].map(apart_wc)
编码
# 编码-有序多分类(根据上面可视化的结果,按照对价格的影响程度排序,越大影响越高)
# 无序多分类无法直接引入,必须“哑元”化变量
# 等级变量(有序多分类)可以直接引入模型
map1 = {'南':5, '南北':6, '北':1, '西南':10, '东西':4, '东':2, '东北':8, '东南':9, '西':3, '西北':7}
d1['朝向'] = d1['朝向'].map(map1)
map2 = {'毛坯':1, '简装修':2, '精装修':3, '中装修':4, '豪华装修':5}
d1['装修'] = d1['装修'].map(map2)
map3 = {'有 ':1, '无 ':0}
d1['电梯'] = d1['电梯'].map(map3)
map4 = {'商品房':6, '个人产权':5, '商品房(免税)':7, '普通商品房':4, '经济适用房':2, '房改房':3, '限价房':8, '房本房':1}
d1['产权性质'] = d1['产权性质'].map(map4)
map5 = {'普通住宅':4, '经济适用房':3, '公寓':1, '商住楼':2, '酒店式公寓':5}
d1['住宅类别'] = d1['住宅类别'].map(map5)
map6 = {'平层':4, '开间':2, '跃层':5, '错层':1, '复式':3}
d1['建筑结构'] = d1['建筑结构'].map(map6)
map7 = {'板楼':4, '钢混':5, '塔板结合':3, '平房':6, '砖混':1, '塔楼':7, '砖楼':2}
d1['建筑类别'] = d1['建筑类别'].map(map7)
map8 = {'城关':6, '安宁':5, '七里河':4, '西固':3,'榆中':2, '永登':1}
d1['区域'] = d1['区域'].map(map8)
# 删除超过2019年的房子,年代转变为房龄
d1['建筑年代'] = d1['建筑年代'].astype('int32')
d1.drop(index=d1[d1['建筑年代']>2019].index,inplace=True)
d1['房龄'] = d1['建筑年代'].map(lambda x: 2020-x)
d1.drop(columns=['建筑年代'],inplace=True)
X = d1.drop(columns=['总价'])
y = d1['总价']
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=33)
poly = PolynomialFeatures(degree=2)
x_train = poly.fit_transform(X_train.values)
x_test = poly.fit_transform(X_test)
套索回归
# 套索回归
la = Lasso(alpha=0.1,max_iter=100000)
la.fit(x_train,y_train)
print(f'训练集得分:{round(la.score(x_train,y_train),2)}')
print(f'测试集得分:{round(la.score(x_test,y_test),2)}')
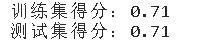
随机森林
# 随机森林
rf = RandomForestRegressor()
rf.fit(x_train,y_train)
print(f'训练集得分:{round(rf.score(x_train,y_train),2)}')
print(f'测试集得分:{round(rf.score(x_test,y_test),2)}')
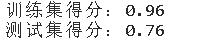
决策树
# 决策树
dt = DecisionTreeRegressor(max_depth = 6)
dt.fit(x_train,y_train)
print(f'训练集得分:{round(dt.score(x_train,y_train),2)}')
print(f'测试集得分:{round(dt.score(x_test,y_test),2)}')
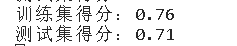
k近邻
# k近邻
kn = KNeighborsRegressor(n_neighbors=20)
kn.fit(x_train,y_train)
print(f'训练集得分:{round(kn.score(x_train,y_train),2)}')
print(f'测试集得分:{round(kn.score(x_test,y_test),2)}')

比较几种模型,最终在测试集的得分都能保持在70%以上。
随机森林训练集得分达到90%以上,测试集得分在几种模型里表现也是最好的。
情景模拟
一家三口,孩子即将上学,大人城关区工作,需要购买房子,假设要求如下:3室1厅1卫(3、1、1)、面积大概再95㎡左右(95)、学区房(1)、东南(10)、中装修 (4)、无电梯 (0)、个人产权(5)、普通住宅(4)、平层(4)、钢混(5)、城关(6)、房龄 (10)。

文章来源:https://blog.csdn.net/s1t16/article/details/135390532
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!