动手学深度学习6 自动求导
发布时间:2024年01月18日
自动求导
视频: https://www.bilibili.com/video/BV1KA411N7Px/?spm_id_from=autoNext&vd_source=eb04c9a33e87ceba9c9a2e5f09752ef8
课件: https://zh-v2.d2l.ai/chapter_preliminaries/autograd.html
课上PPT: https://courses.d2l.ai/zh-v2/assets/pdfs/part-0_7.pdf
从入门到放弃说的就是这两节课~~~
1. 自动求导




自动求导是怎么做出来的–计算图–等价于链式法则求导的过程
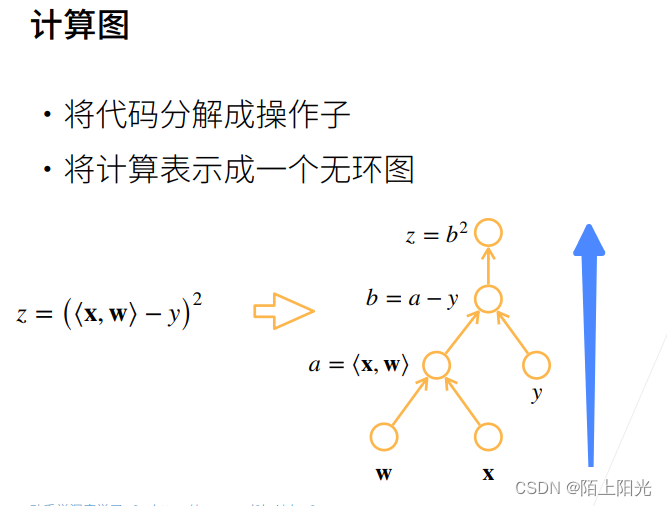



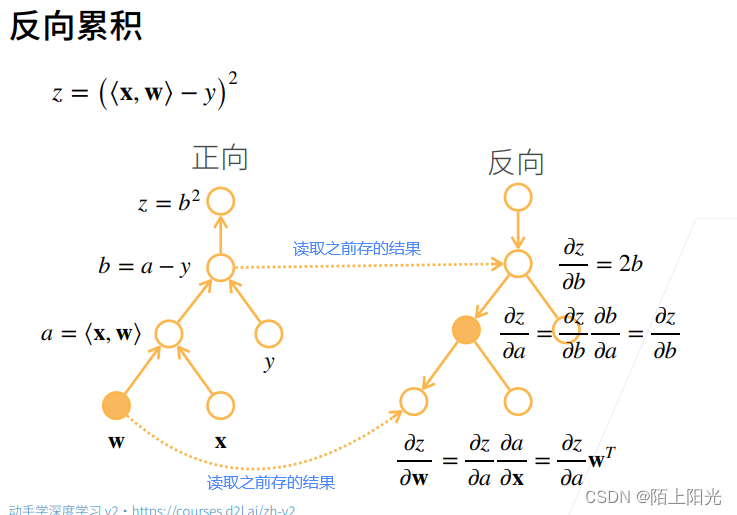
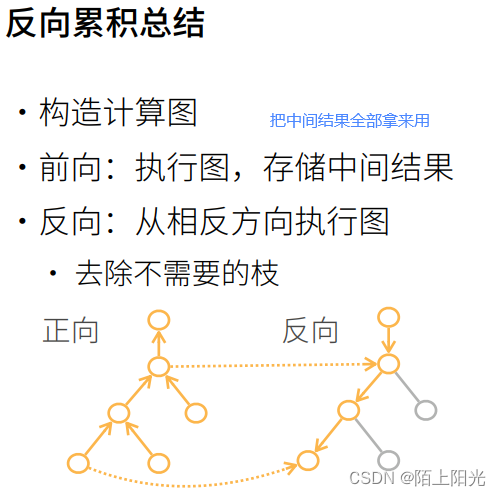
反向传播,内存复杂度O(n),存储正向计算的所有中间结果,也是深度神经网络非常耗gpu资源的原因。

正向累积需要对每一层计算梯度,计算复杂度太高【每一层应该也有很多变量】
2. 自动求导实现
1. 示例 y = 2 X T X y=2X^TX y=2XTX 关于列向量x求导。
y=sum(x) , 导数是全为1的向量

import torch
x = torch.arange(4.0)
print(x)
# 设置一个地方 保存梯度 不会在每次对一个参数求导时都分配新的内存
# 一个标量函数关于向量x的梯度是向量,并且与x具有相同的形状
# x = torch.arange(4.0, requires_grad=True) # 定义后再调梯度或者定义向量的时候就指定requires_grad参数,效果是一样的
x.requires_grad_(True)
print(x.grad) # 访问梯度 默认值是None
# 计算y 标量
y = 2 * torch.dot(x, x)
print(y) # torch会记住所有操作 grad_fn=<MulBackward0>
# 调用反向传播函数 计算y关于x每个分量的梯度 梯度与x同形状
y.backward()
print(x.grad) # 访问梯度
# 函数y=2x^Tx 关于x的梯度应为4x
print(x.grad == 4*x)
# 计算x的另一个函数,此时可以认为是另一层网络了,上一层的计算已经结束 梯度的值需要清零
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_() # 下划线表示重新写入
y = x.sum() #
y.backward()
print(x.grad) # 在梯度不清零的情况下直接求导,梯度会在原来的值上做累加求和 [0.,4.,8.,12.]+[1.,1.,1.,1.]=[1.,5.,9.,13.]
tensor([0., 1., 2., 3.])
None
tensor(28., grad_fn=<MulBackward0>)
tensor([ 0., 4., 8., 12.])
tensor([True, True, True, True])
tensor([ 1., 5., 9., 13.])
2. 非标量变量的反向传播
3. 分离计算
4. Python控制流的梯度计算
QA
明天再写
文章来源:https://blog.csdn.net/weixin_42831564/article/details/135658138
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Matlab 求阴影部分面积
- Textual Inversion、DreamBooth、LoRA、InstantID:从低成本进化到零成本实现IP专属的AI绘画模型
- xtrabackup主备报错cannot open file ibdata2
- UE4.27_PIE/SIE
- java常见面试题:如何使用Java进行文件操作?
- Gradle有那么多优点 为什么不能取代Maven
- 做饭这些事:工程师用热风枪来烤鸡翅~
- 2024.1.16 练习题目java
- 学累了怎么休息???
- 通货紧缩,通货膨胀