Mindspore 公开课 - CodeGeeX
CodeGeeX: 多语言代码生成模型
CodeGeeX 是一个具有130亿参数的多编程语言代码生成预训练模型。CodeGeeX采用华为MindSpore框架实现,在鹏城实验室“鹏城云脑II”中的192个节点(共1536个国产昇腾910 AI处理器)上训练而成。截至2022年6月22日,CodeGeeX历时两个月在20多种编程语言的代码语料库(>8500亿Token)上预训练得到。CodeGeeX有以下特点:
高精度代码生成:支持生成 Python、C++、Java、JavaScript 和 Go 等多种主流编程语言的代码,在HumanEval-X代码生成任务上取得47%~60%求解率,较其他开源基线模型有更佳的平均性能。代码生成示例
跨语言代码翻译:支持代码片段在不同编程语言间进行自动翻译转换,翻译结果正确率高,在HumanEval-X代码翻译任务上超越了其它基线模型。代码翻译示例
自动编程插件:CodeGeeX插件现已上架VSCode插件市场(完全免费),用户可以通过其强大的少样本生成能力,自定义代码生成风格和能力,更好辅助代码编写。插件下载
模型跨平台开源: 所有代码和模型权重开源开放,用作研究用途。CodeGeeX同时支持昇腾和英伟达平台,可在单张昇腾910或英伟达V100/A100上实现推理。申请模型权重
全新多编程语言评测基准HumanEval-X:HumanEval-X是第一个支持功能正确性评测的多语言、多任务的基准,包含820个人工编写的高质量代码生成题目、测试用例与参考答案,覆盖5种编程语言(Python、C++、Java、JavaScript、Go),支持代码生成与代码翻译能力的评测。
使用指南
CodeGeeX 最初使用Mindspore框架实现,并在昇腾 910AI 芯片上进行训练。为适配更多平台,我们将其转换到 Megatron-LM 框架,支持 Pytorch+GPU 环境。
需要Python 3.7+ / CUDA 11+ / PyTorch 1.10+ / DeepSpeed 0.6+,通过以下命令安装 codegeex:
git clone git@github.com:THUDM/CodeGeeX.git
cd CodeGeeX
pip install -e .
模型权重
通过 该链接 申请权重,您将收到一个包含临时下载链接文件urls.txt的邮件。推荐使用 aria2 通过以下命令快速下载(请保证有足够的硬盘空间存放权重(~26GB)):
aria2c -x 16 -s 16 -j 4 --continue=true -i urls.txt
使用以下命令合并得到完整的权重:
cat codegeex_13b.tar.gz.* > codegeex_13b.tar.gz
tar xvf codegeex_13b.tar.gz
用GPU进行推理
尝试使用CodeGeeX模型生成第一个程序吧!首先,在配置文件configs/codegeex_13b.sh中写明存放权重的路径。其次,将提示(可以是任意描述或代码片段)写入文件tests/test_prompt.txt,运行以下脚本即可开始推理(需指定GPU序号):
# On a single GPU (with more than 27GB RAM)
bash ./scripts/test_inference.sh <GPU_ID> ./tests/test_prompt.txt
# With quantization (with more than 15GB RAM)
bash ./scripts/test_inference_quantized.sh <GPU_ID> ./tests/test_prompt.txt
# On multiple GPUs (with more than 6GB RAM, need to first convert ckpt to MP_SIZE partitions)
bash ./scripts/convert_ckpt_parallel.sh <LOAD_CKPT_PATH> <SAVE_CKPT_PATH> <MP_SIZE>
bash ./scripts/test_inference_parallel.sh <MP_SIZE> ./tests/test_prompt.txt
插件使用指南
基于CodeGeeX,我们开发了免费的插件,支持 VS Code 与 Jetbrains IDEs,未来会支持更多平台。
VS Code版本,在应用市场搜索“codegeex”或通过 该链接 安装。详细的使用指南在CodeGeeX VS Code插件使用指南。
Jetbrains版本,在Plugins市场搜索“codegeex”或通过 该链接 安装。 请确保IDE版本在2021.1或更高。CodeGeeX目前支持 IntelliJ IDEA, PyCharm, GoLand, CLion, Android Studio, AppCode, Aqua, DataSpell, DataGrip, Rider, RubyMine, WebStorm。
CodeGeeX: 多语言代码生成模型
架构:CodeGeeX是一个基于transformers的大规模预训练编程语言模型。它是一个从左到右生成的自回归解码器,将代码或自然语言标识符(token)作为输入,预测下一个标识符的概率分布。CodeGeeX含有40个transformer层,每层自注意力块的隐藏层维数为5120,前馈层维数为20480,总参数量为130亿。模型支持的最大序列长度为2048。
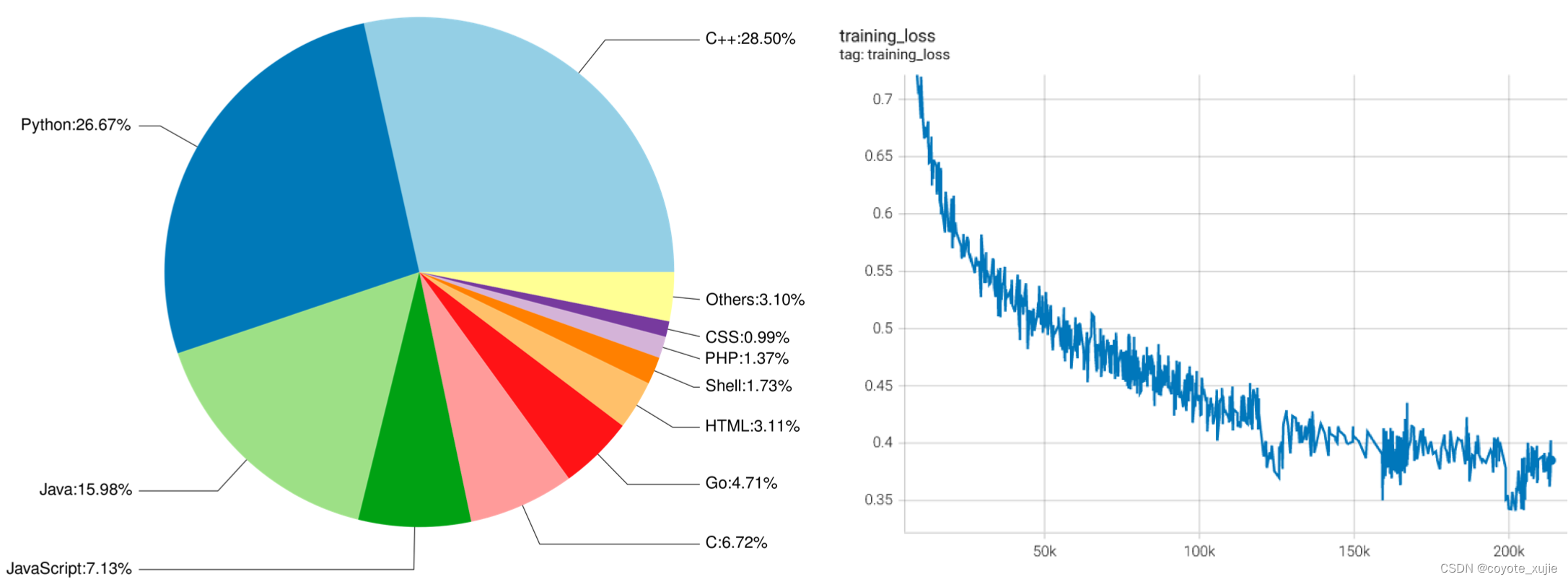
语料:CodeGeeX的训练语料由两部分组成。第一部分是开源代码数据集,The Pile 与 CodeParrot。The Pile包含GitHub上拥有超过100颗星的一部分开源仓库,我们从中选取了23种编程语言的代码。第二部分是补充数据,直接从GitHub开源仓库中爬取Python、Java、C++代码;为了获取高质量数据,我们根据以下准则选取代码仓库:1)至少拥有1颗星;2)总大小<10MB;3)不在此前的开源代码数据集中。我们还去掉了符合下列任一条件的文件:1)平均每行长度大于100字符;2)由自动生成得到;3)含有的字母不足字母表内的40%;4)大于100KB或小于1KB。为了让模型区分不同语言,我们在每个样本的开头加上一个前缀,其形式为[注释符] language: [语言],例如:# language: Python。我们使用与GPT-2相同的分词器,并将空格处理为特殊标识符,词表大小为50400。整个代码语料含有23种编程语言、总计1587亿个标识符(不含填充符)。
国产平台实现与训练
我们在Mindspore 1.7框架上实现了CodeGeeX模型,并使用鹏城实验室的全国产计算平台上进行训练。具体来说,CodeGeeX使用了其一个计算集群中的1536个昇腾910 AI处理器(32GB)进行了两个月左右的训练(2022年4月18日至6月22日)。除了Layer-norm与Softmax使用FP32格式以获得更高的精度与稳定性,模型参数整体使用FP16格式,最终整个模型需要占用约27GB显存。为了增加训练效率,我们使用8路模型并行和192路数据并行的训练策略,微批大小为16、全局批大小为3072,并采用ZeRO-2优化器降低显存占用。
在开发与训练过程中,我们和华为Mindspore团队合作,对MindSpore框架进行了部分优化,进而大幅度提升训练效率。比如,我们发现矩阵乘法的计算时间占比仅为22.9%,大量时间被用于各类其它算子,因此实现了一系列算子融合,包括单元素算子融合、层归一化算子融合、FastGelu与矩阵乘法融合、批量矩阵乘法与加法融合等;再比如我们还对矩阵乘法算子的维度实现自动搜索调优,使其搜索出效率最高的计算维度组合。这些优化为训练速度带来了显著提升,在同等GPU卡数规模下(128卡),昇腾910对CodeGeeX这一模型的训练效率从约为NVIDIA A100的16.7%提升至43%;在千卡规模下,昇腾910训练效率相比自身优化前提升近300%。使用优化后的软硬件训练时,CodeGeeX单日训练量可达到54.3B个标识符(含填充符),证明了国产深度学习平台与工具的快速迭代能力以及强大竞争力。
HumanEval-X: 多语言代码生成基准
为了更好地评测代码生成模型的多语言生成能力,我们构建了一个新基准HumanEval-X。此前,多语言代码生成能力是基于语义相似度(比如CodeBLEU)衡量的,具有一定误导性;HumanEval-X则可用于衡量生成代码的功能正确性。HumanEval-X包含820个高质量手写样本,覆盖Python、C++、Java、JavaScript、Go,可用于多种任务。

HumanEval-X中每个语言的样本,包含了声明、描述和解答,它们之间的组合可以支持不同的下游任务,包括生成、翻译、概括等。我们目前关注两个任务:代码生成与代码翻译。对于代码生成任务,模型将函数声明与文档字符串作为输入,输出函数实现;对于代码翻译任务,模型将两种语言的函数声明与源语言的实现作为输入,输出目标语言上的实现。我们在代码翻译任务中不将文档字符串输入模型,以避免模型直接通过描述生成答案。在两种任务下,我们都采用Codex所使用的无偏pass@k指标,判断生成代码的功能正确性:
pass
@
k
:
=
E
[
1
?
(
n
?
c
k
)
(
n
k
)
]
\text{pass}@k:= \mathbb{E}[1-\frac{\tbinom{n-c}{k}}{\tbinom{n}{k}}]
pass@k:=E[1?(kn?)(kn?c?)?],
k
∈
(
1
,
10
,
100
)
k\in(1,10,100)
k∈(1,10,100)
多语言代码生成
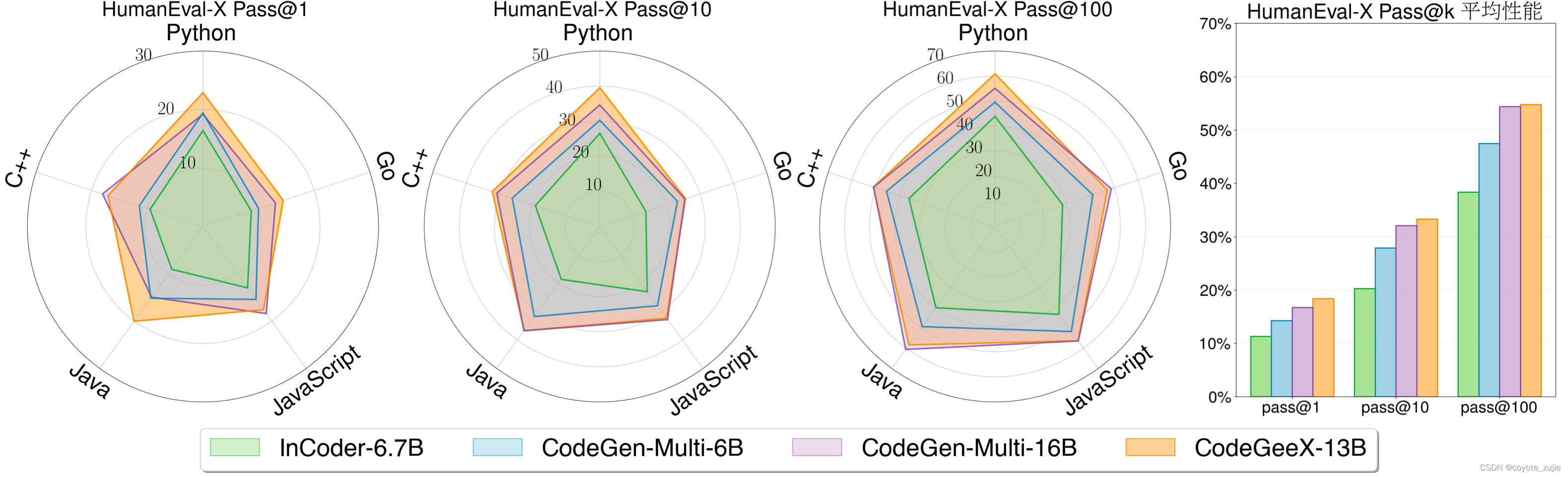
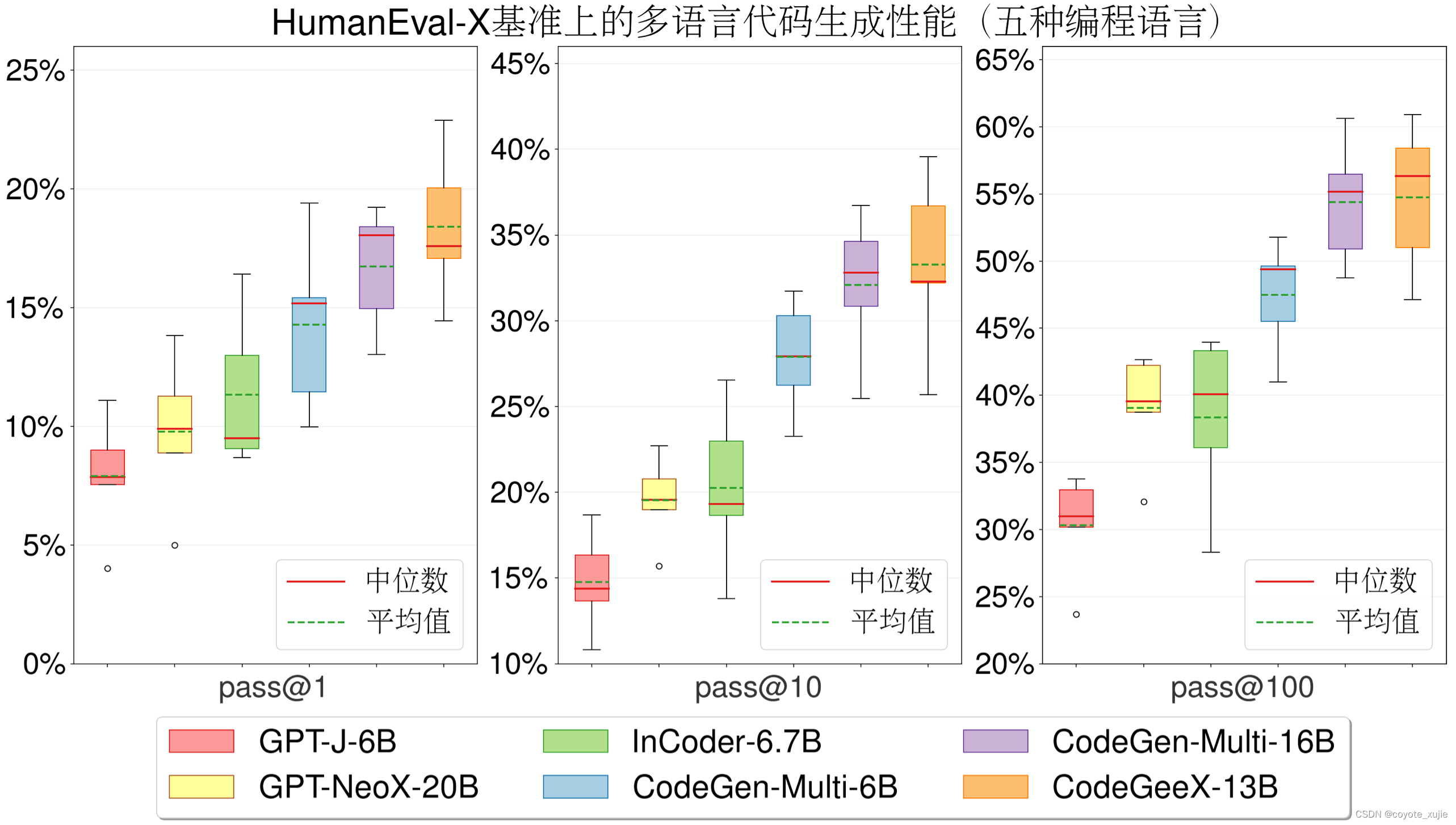
我们将CodeGeeX与另外两个开源代码生成模型进行比较,分别为Meta的 InCoder 与Salesforce的 CodeGen,选取InCoder-6.7B、CodeGen-Multi-6B 与 CodeGen-Multi-16B。CodeGeeX能获得最佳的平均性能,显著超越了参数量更小的模型(7.5%~16.3%的提升),与参数量更大的模型CodeGen-Multi-16B表现相当(平均性能 54.76% vs. 54.39%)。
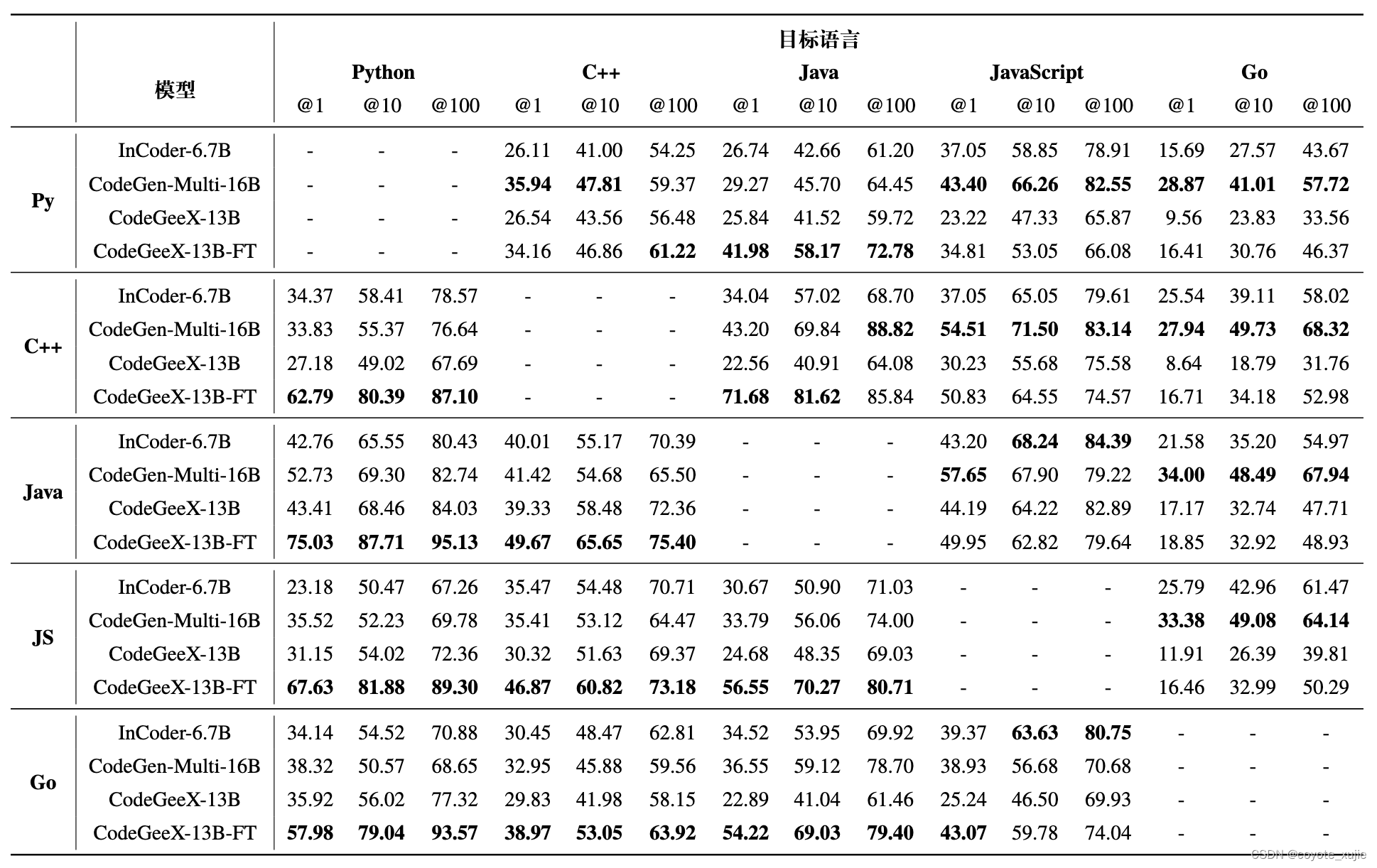
对于CodeGeeX,评测了未经微调的CodeGeeX-13B与经过微调的CodeGeeX-13B-FT(使用XLCoST中代码翻译任务的训练集与一部分Go语言数据微调)。如上表显示,模型对特定语言存在偏好,比如CodeGeeX擅长将其他语言翻译为Python与C++,而CodeGen-Multi-16B擅长翻译为JavaScript和Go,这可能是由于训练集中的语料占比存在差异。在20个翻译对中,我们还观察到两种语言互相翻译的表现常常是呈负相关的,这可能说明现有的模型还不足以学好所有的语言。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 345. 牛站(Floyd倍增算法,Floyd快速幂)
- Spring-AOP入门案例
- 成功在windows系统上安装OpenPCDet-踩坑无数版
- BP神经网络
- PS安装失败-182的解决办法
- Copernicus DEM 30m高程地形瓦片数据介绍
- 号称 10 分钟搞定,前端新手引导功能
- RPC框架选型:gRPC、Thrift、Dubbo、Spring Cloud
- AI写作生成器哪个好用一点,试试下面这五款
- java 数据结构总结之 集合 collection