Spark环境搭建和使用方法
目录
一、安装Spark
(一)基础环境
安装Spark之前需要安装Linux系统、Java环境(Java8或JDK1.8以上版本)和Hadoop环境。
可参考本专栏前面的博客:
大数据软件基础(3) —— 在VMware上安装Linux集群-CSDN博客
大数据存储技术(1)—— Hadoop简介及安装配置-CSDN博客
(二)安装Python3版本
1、查看当前环境下的Python版本
[root@bigdata zhc]# python --version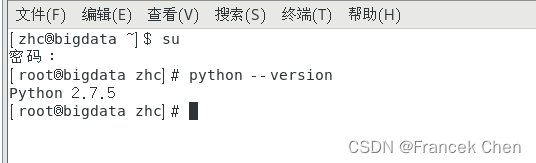
?Python 2.7.5 版本已经不能满足当前编程环境需求,所以要安装较高版本的Python3,但Python 2.7.5 版本不能卸载。
2、连网下载Python3
[root@bigdata zhc]# yum install -y python3?如图所示,Python3安装完成。
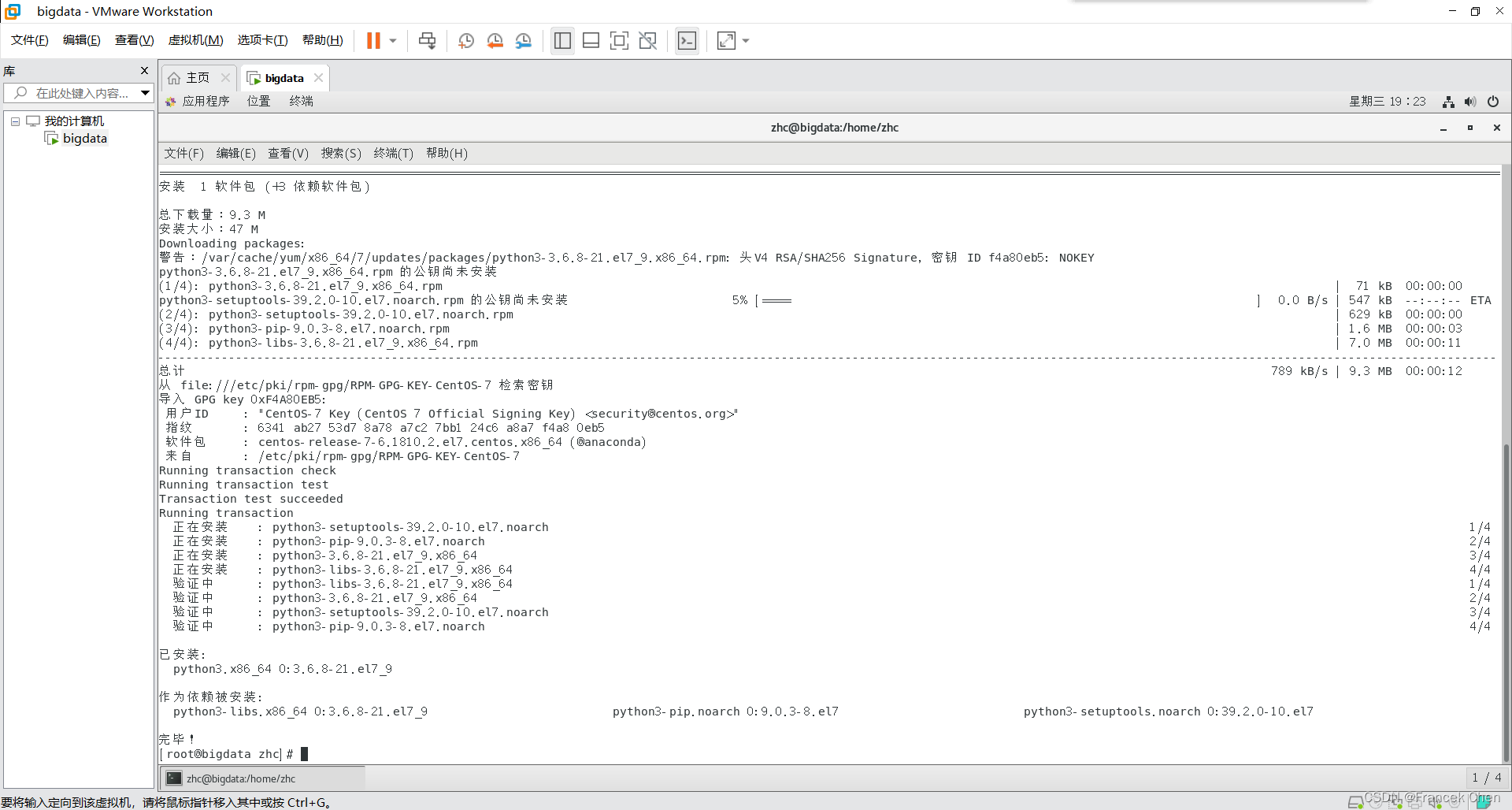
?安装的版本为Python 3.6.8。
(三)下载安装Spark
1、Spark安装包下载地址:https://spark.apache.org/
进入下载页面后,点击主页的“Download”按钮进入下载页面,下载页面中提供了几个下载选项,主要是Spark release及Package type的选择,如下图所示。
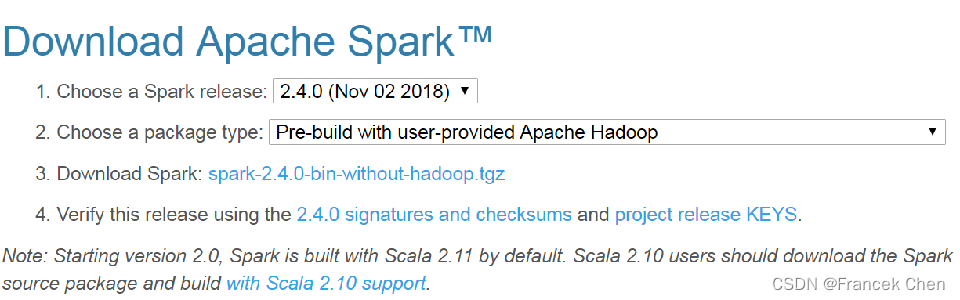
我这里下的是Spark 2.4.0版本,没有此版本的,也可以下载Spark 3.2.4或更高版本的。
2、解压安装包spark-2.4.0-bin-without-hadoop.tgz至路径 /usr/local

[root@bigdata uploads]# tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /usr/local更改文件目录名:
[root@bigdata local]# mv spark-2.4.0-bin-without-hadoop/ spark?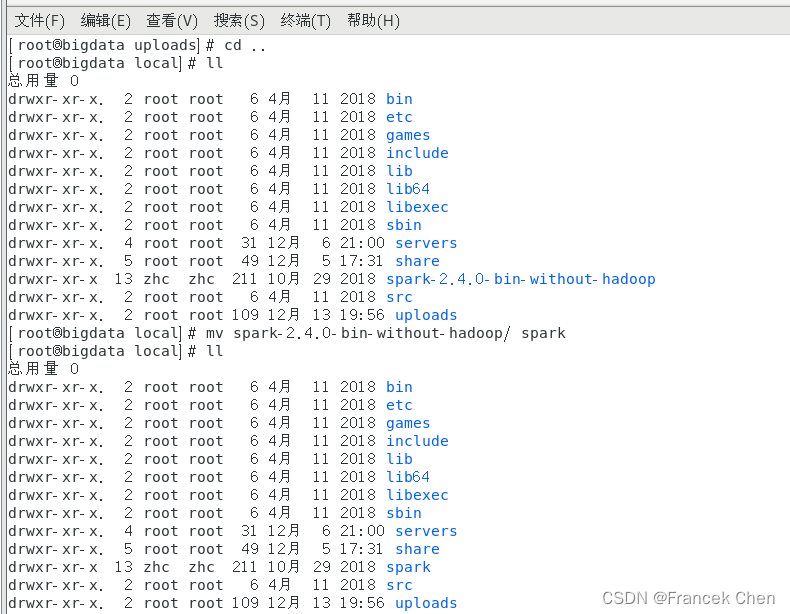
(四)配置相关文件
1、配置Spark的classpath
先切换到 /usr/local/spark/conf 目录下,复制spark-env.sh.template重命名为spark-env.sh。
[root@bigdata local]# cd /usr/local/spark/conf
[root@bigdata conf]# cp spark-env.sh.template spark-env.sh
[root@bigdata conf]# ll
总用量 44
-rw-r--r-- 1 zhc zhc 996 10月 29 2018 docker.properties.template
-rw-r--r-- 1 zhc zhc 1105 10月 29 2018 fairscheduler.xml.template
-rw-r--r-- 1 zhc zhc 2025 10月 29 2018 log4j.properties.template
-rw-r--r-- 1 zhc zhc 7801 10月 29 2018 metrics.properties.template
-rw-r--r-- 1 zhc zhc 865 10月 29 2018 slaves.template
-rw-r--r-- 1 zhc zhc 1292 10月 29 2018 spark-defaults.conf.template
-rwxr-xr-x 1 root root 4221 12月 13 20:23 spark-env.sh
-rwxr-xr-x 1 zhc zhc 4221 10月 29 2018 spark-env.sh.template
[root@bigdata conf]# vi spark-env.sh将如下内容加到spark-env.sh文件的第一行。
export SPARK_DIST_CLASSPATH=$(/usr/local/servers/hadoop/bin/hadoop classpath)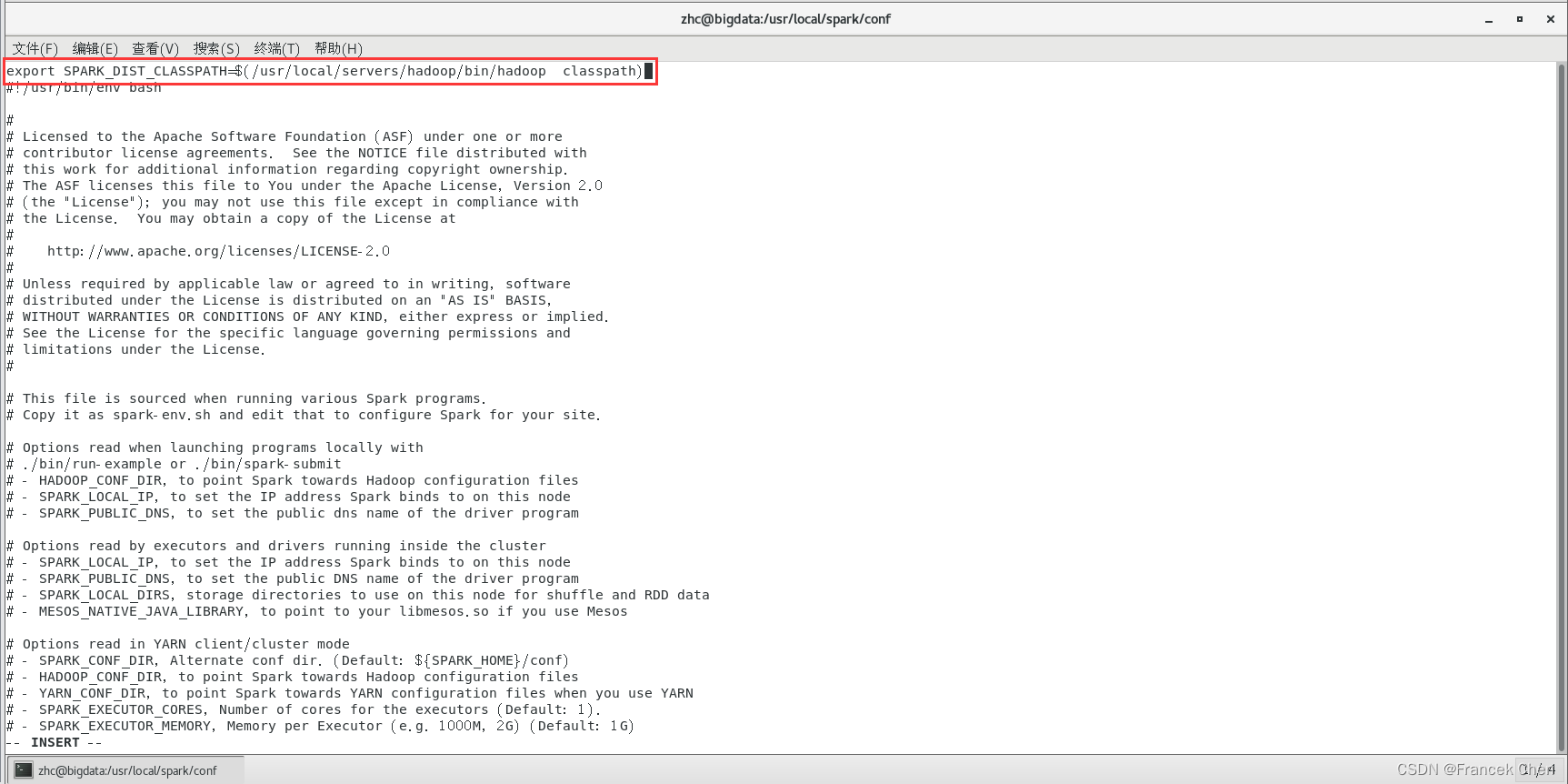
实现了Spark和Hadoop的交互。
2、配置 /etc/profile 文件
将如下内容添加到 /etc/profile 文件最后,并使其生效。
[root@bigdata conf]# vi /etc/profile
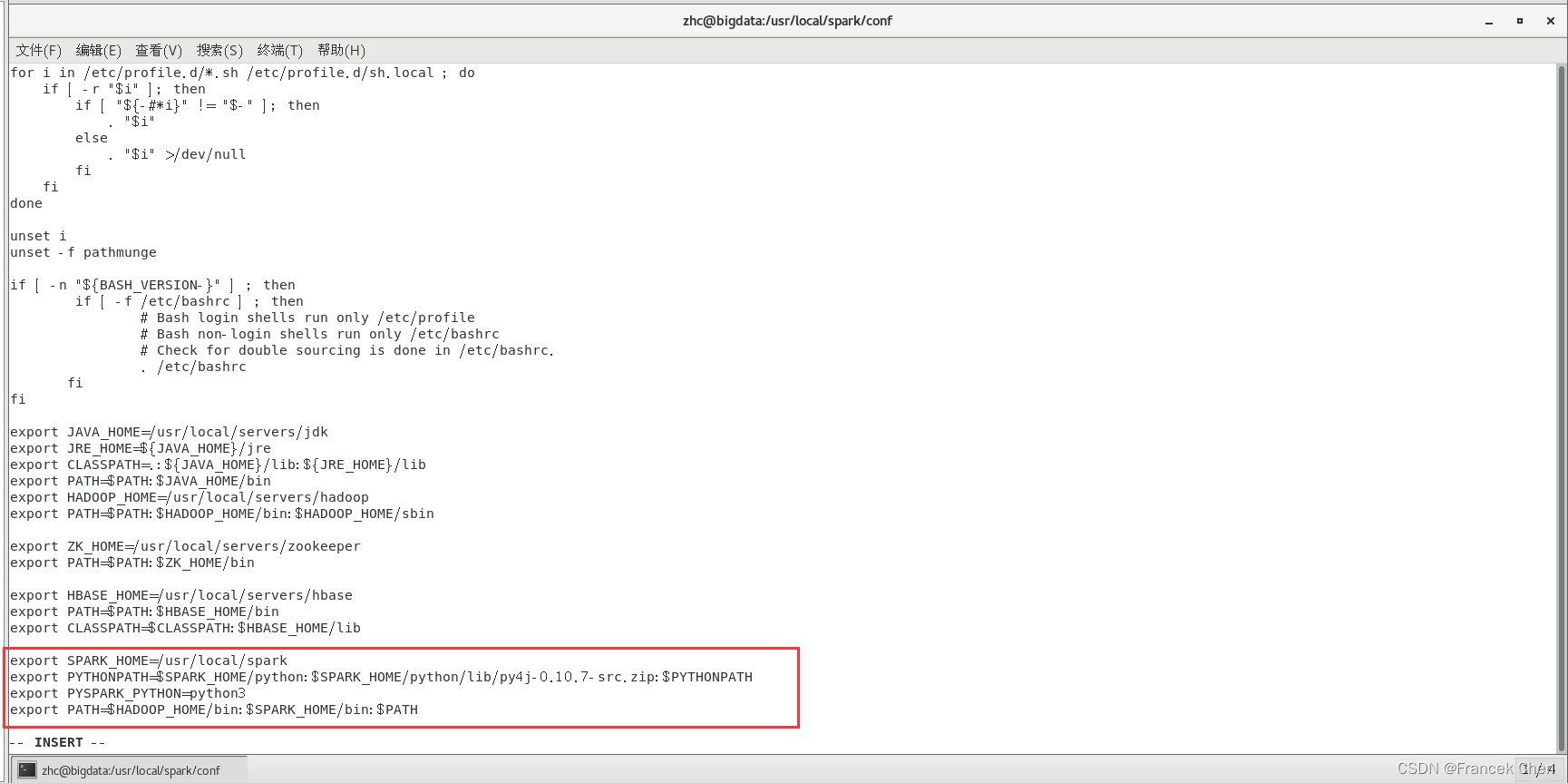
[root@bigdata conf]# source /etc/profileexport SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH如下图所示。?
至此,Spark环境就安装配置好了。
输入实例SparkPi验证Spark环境。为了从大量的输出信息中快速找到我们想要的自行结果,可以使用grep命令进行过滤。命令如下:
[root@bigdata spark]# run-example SparkPi 2>&1 |grep "Pi is" ?
?
二、在pyspark中运行代码
(一)pyspark命令
pyspark命令及其常用的参数如下:
pyspark --master <master-url>
Spark的运行模式取决于传递给SparkContext的Master URL的值。Master URL可以是以下任一种形式:
? ? ? ? (1)local 使用一个Worker线程本地化运行SPARK(完全不并行)
? ? ? ? (2)local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark
? ? ? ? (3)local[K] 使用K个Worker线程本地化运行Spark(理想情况下,K应该根据运行机器的CPU核数设定)
? ? ? ? (4)spark://HOST:PORT 连接到指定的Spark standalone master。默认端口是7077
? ? ? ? (5)yarn-client 以客户端模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR环境变量中找到
? ? ? ? (6)yarn-cluster 以集群模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR环境变量中找到
? ? ? ? (7)mesos://HOST:PORT 连接到指定的Mesos集群。默认接口是5050
在Spark中采用本地模式启动pyspark的命令主要包含以下参数:
--master:这个参数表示当前的pyspark要连接到哪个master,如果是local[*],就是使用本地模式启动pyspark,其中,中括号内的星号表示需要使用几个CPU核心(core),也就是启动几个线程模拟Spark集群
--jars: 这个参数用于把相关的JAR包添加到CLASSPATH中;如果有多个jar包,可以使用逗号分隔符连接它们。
比如,要采用本地模式,在4个CPU核心上运行pyspark:
$ cd /usr/local/spark
$ ./bin/pyspark --master local[4]或者,可以在CLASSPATH中添加code.jar,命令如下:
$ cd /usr/local/spark
$ ./bin/pyspark --master local[4] --jars code.jar ?可以执行“pyspark --help”命令,获取完整的选项列表,具体如下:
$ cd /usr/local/spark
$ ./bin/pyspark --help(二)启动pyspark?
执行如下命令启动pyspark(默认是local模式):
[root@bigdata zhc]# cd /usr/local/spark
[root@bigdata spark]# pyspark
可以在里面输入scala代码进行调试:
>>> 8*2+5
21
?可以使用命令“exit()”退出pyspark:
>>> exit()
三、开发Spark独立应用程序
(一)编写程序
# /home/zhc/mycode/WordCount.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
logFile = "file:///usr/local/spark/README.md"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))
对于这段Python代码,可以直接使用如下命令执行:
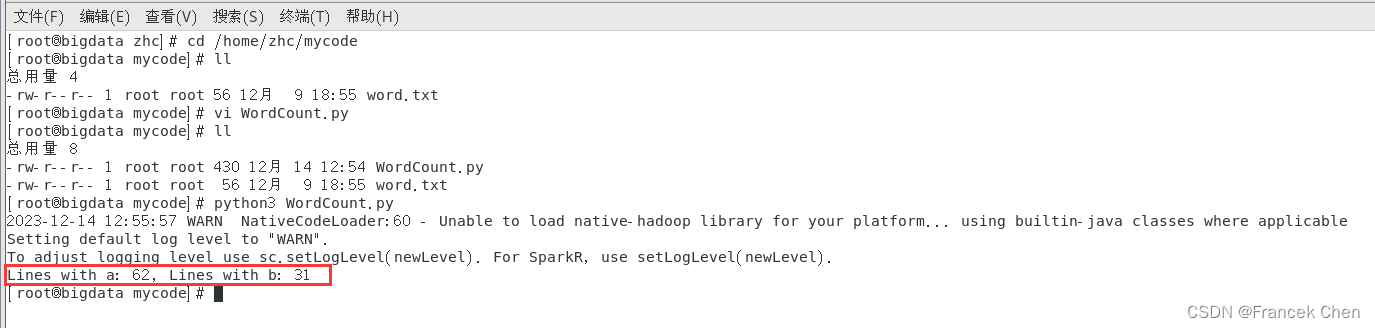
[root@bigdata zhc]# cd /home/zhc/mycode
[root@bigdata mycode]# vi WordCount.py
[root@bigdata mycode]# ll
总用量 8
-rw-r--r-- 1 root root 430 12月 14 12:54 WordCount.py
-rw-r--r-- 1 root root 56 12月 9 18:55 word.txt
[root@bigdata mycode]# python3 WordCount.py执行该命令以后,可以得到如下结果:
(二)通过spark-submit运行程序?
可以通过spark-submit提交应用程序,该命令的格式如下:
spark-submit ?
????????--master <master-url> ?
????????--deploy-mode <deploy-mode> ? #部署模式 ?
????????... #其他参数 ?
????????<application-file> ?#Python代码文件 ?
????????[application-arguments] ?#传递给主类的主方法的参数
可以执行“spark-submit ?--help”命令,获取完整的选项列表,具体如下:
$ cd /usr/local/spark
$ ./bin/spark-submit --help以通过 spark-submit 提交到 Spark 中运行,命令如下:
注意要在 /home/zhc/mycode/ 路径下执行spark-submit,否则要使用绝对路径。
[root@bigdata mycode]# spark-submit WordCount.py[root@bigdata zhc]# spark-submit /home/zhc/mycode/WordCount.py #绝对路径运行结果如图所示:?

此时我们发现有大量的INFO信息,这些信息属于干扰信息,对于我们有用的只有“Lines with a: 62, Lines with b: 30”这一行。为了避免其他多余信息对运行结果的干扰,可以修改log4j的日志信息显示级别,具体方法如下:
[root@bigdata spark]# cd /usr/local/spark/conf
[root@bigdata conf]# ll
总用量 44
-rw-r--r-- 1 zhc zhc 996 10月 29 2018 docker.properties.template
-rw-r--r-- 1 zhc zhc 1105 10月 29 2018 fairscheduler.xml.template
-rw-r--r-- 1 zhc zhc 2025 10月 29 2018 log4j.properties.template
-rw-r--r-- 1 zhc zhc 7801 10月 29 2018 metrics.properties.template
-rw-r--r-- 1 zhc zhc 865 10月 29 2018 slaves.template
-rw-r--r-- 1 zhc zhc 1292 10月 29 2018 spark-defaults.conf.template
-rwxr-xr-x 1 root root 4300 12月 13 20:33 spark-env.sh
-rwxr-xr-x 1 zhc zhc 4221 10月 29 2018 spark-env.sh.template
[root@bigdata conf]# cp log4j.properties.template log4j.properties
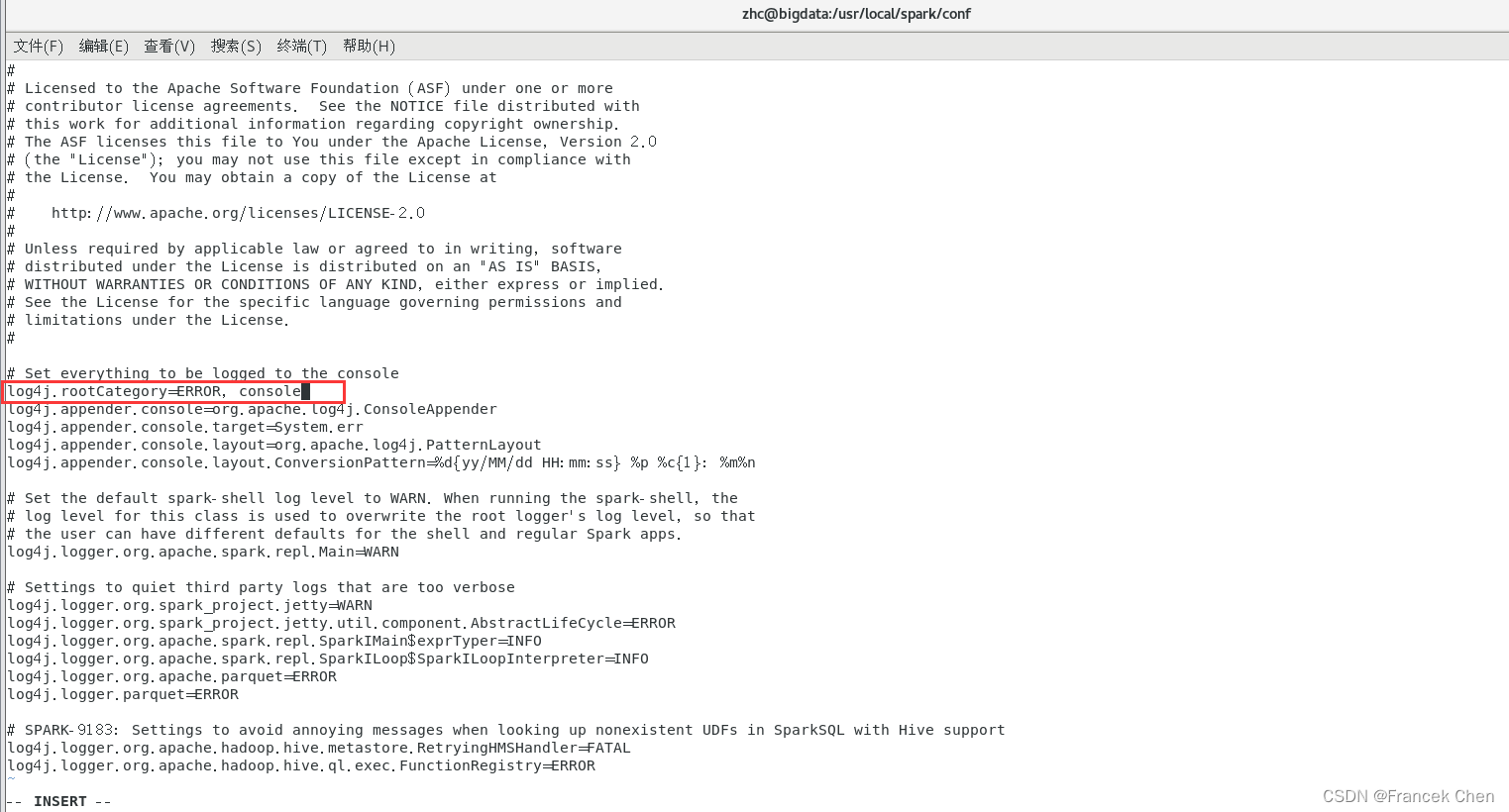
[root@bigdata conf]# vi log4j.properties打开?log4j.properties 文件后,可以发现包含如下一行信息:
log4j.rootCategory=INFO, console
将其修改为:?
log4j.rootCategory=ERROR, console
再次回到?/home/zhc/mycode/ 路径下执行spark-submit,就会发现没有INFO信息了。
[root@bigdata mycode]# spark-submit WordCount.py
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 力扣-367. 有效的完全平方数
- 【后端学前端】第四天 css动画 垂直轮播效果(css变量、位移缩放动画、动画延迟)
- 远端连接vscode
- 同为程序员,2023 年你还好吗?来看看我的这一年
- 卓越进行时 | 赛宁网安与中汽创智达成战略合作
- ChatGPT使用:一个发包机器人的提示词
- 全志V853 NPU开发之Demo使用说明
- java内存屏障
- 入站请求负载均衡解决方案 LVS 的介绍
- 武理多媒体信息共享平台的架构设计与实现