数据结构OJ实验14-哈希查找
A. DS哈希查找—线性探测再散列
题目描述
定义哈希函数为H(key) = key%11,输入表长(大于、等于11)。输入关键字集合,用线性探测再散列构建哈希表,并查找给定关键字。
输入
测试次数t
每组测试数据为:
哈希表长m、关键字个数n
n个关键字
查找次数k
k个待查关键字
输出
对每组测试数据,输出以下信息:
构造的哈希表信息,数组中没有关键字的位置输出NULL
对k个待查关键字,分别输出:0或1(0—不成功,1—成功)、比较次数、查找成功的位置(从1开始)
样例查看模式?
正常显示查看格式
输入样例1?
1\n
12?10\n
22?19?21?8?9?30?33?4?15?14\n
4\n
22\n
56\n
30\n
17\n
输出样例1
22?30?33?14?4?15?NULL?NULL?19?8?21?9\n
1?1?1\n
0?6\n
1?6?2\n
0?1\n
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=1e5;
int n,m;
int h[N];
int k;
void hasht(int x)
{
int x1=x%11;//初始
for(int i=0;i<m;i++)
{
int temp=(x1+i)%m;//再线性探测
if(h[temp]==-1)
{
h[temp]=x;
break;
}
}
}
void find(int x)
{
int cnt=0;
int idx=-1;
bool ok=0;
int x1=x%11;
for(int i=0;i<m;i++)
{
cnt++;//查找次数
int temp=(x1+i)%m;
if(h[temp]==-1)
{
break;//找不到这个元素
}
if(h[temp]==x)
{
ok=1;
idx=temp;
break;
}
}
if (ok)
cout << ok << " " << cnt << " " << idx + 1 << endl;
else
cout << ok << " " << cnt << endl;
}
int main()
{
int t;
cin>>t;
while(t--)
{
memset(h,-1,sizeof(h));//初始h
cin>>m>>n;
for(int i=0;i<n;i++)
{
int x;
cin>>x;
hasht(x);
}
for(int i=0;i<m;i++)
{
if(h[i]!=-1)
{
cout<<h[i];
}
else cout<<"NULL";
if(i!=m-1)cout<<" ";
else cout<<endl;
}
cin>>k;
while(k--)
{
int x;
cin>>x;
find(x);
}
}
return 0;
}B. DS哈希查找—二次探测再散列
题目描述
定义哈希函数为H(key) = key%11。输入表长(大于、等于11),输入关键字集合,用二次探测再散列构建哈希表,并查找给定关键字。
输入
测试次数t
每组测试数据格式如下:
哈希表长m、关键字个数n
n个关键字
查找次数k
k个待查关键字
输出
对每组测试数据,输出以下信息:
构造的哈希表信息,数组中没有关键字的位置输出NULL
对k个待查关键字,分别输出:
0或1(0—不成功,1—成功)、比较次数、查找成功的位置(从1开始)
样例查看模式?
正常显示查看格式
输入样例1?
1\n
12?10\n
22?19?21?8?9?30?33?4?41?13\n
4\n
22\n
15\n
30\n
41\n
输出样例1
22?9?13?NULL?4?41?NULL?30?19?8?21?33\n
1?1?1\n
0?3\n
1?3?8\n
1?6?6\n
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=1e5;
int m,n,t,k;
int h[N];
int d[N];
void init()
{
d[0]=0;
memset(d,0,sizeof(d));
for(int i=1;i<m;i++)
{
if(i%2)
{
d[i]=pow((i+1)/2,2);
}
else
{
d[i]=-d[i-1];
}
}
}
void hasht(int x)
{
int x1=x%11;
for(int i=0;i<m;i++)
{
int temp=(x1+d[i]+m)%m;
if(h[temp]==-1)
{
h[temp]=x;
break;
}
}
}
void find(int x)
{
int cnt=0;
int idx=-1;
bool ok=0;
int x1=x%11;
for(int i=0;i<m;i++)
{
cnt++;
int temp=(x1+d[i]+m)%m;
if(h[temp]==-1)break;
if(h[temp]==x)
{
ok=1;
idx=temp;
break;
}
}
if (ok)
cout << ok << " " << cnt << " " << idx + 1 << endl;
else
cout << ok << " " << cnt << endl;
}
int main()
{
cin>>t;
while(t--)
{
cin>>m>>n;
init();
memset(h,-1,sizeof(h));
for(int i=0;i<n;i++)
{
int x;
cin>>x;
hasht(x);
}
for(int i=0;i<m;i++)
{
if(h[i]!=-1)
{
cout<<h[i];
}
else cout<<"NULL";
if(i!=m-1)cout<<" ";
else cout<<endl;
}
cin>>k;
while(k--)
{
int x;
cin>>x;
find(x);
}
}
return 0;
}C. DS哈希查找--链地址法(表头插入)
题目描述
给出一个数据序列,建立哈希表,采用求余法作为哈希函数,模数为11,哈希冲突用链地址法和表头插入
如果首次查找失败,就把数据插入到相应的位置中
实现哈希查找功能
输入
第一行输入n,表示有n个数据
第二行输入n个数据,都是自然数且互不相同,数据之间用空格隔开
第三行输入t,表示要查找t个数据
从第四行起,每行输入一个要查找的数据,都是正整数
输出
每行输出对应数据的查找结果
样例查看模式?
正常显示查看格式
输入样例1?
6\n
11?23?39?48?75?62\n
6\n
39\n
52\n
52\n
63\n
63\n
52\n
输出样例1
6?1\n
error\n
8?1\n
error\n
8?1\n
8?2\n
AC代码
#include<bits/stdc++.h>
using namespace std;
list<int>l[11];
map<int,int>mp;
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++)
{
int x;
cin>>x;
l[x%11].push_front(x);
mp[x]=1;
}
int k;
cin>>k;
while(k--)
{
int x;
cin>>x;
int d=x%11;
if(mp[x]==0)
{
l[d].push_front(x);
mp[x]=1;
cout<<"error"<<endl;
}
else
{
cout<<d<<" ";
int idx=0;
for(auto t:l[d])
{
idx++;
if(t==x)
{
break;
}
}
cout<<idx<<endl;
}
}
return 0;
}D. DS哈希查找与增补(表尾插入)
题目描述
给出一个数据序列,建立哈希表,采用求余法作为哈希函数,模数为11,哈希冲突用链地址法和表尾插入
如果首次查找失败,就把数据插入到相应的位置中
实现哈希查找与增补功能
输入
第一行输入n,表示有n个数据
第二行输入n个数据,都是自然数且互不相同,数据之间用空格隔开
第三行输入t,表示要查找t个数据
从第四行起,每行输入一个要查找的数据,都是正整数
输出
每行输出对应数据的查找结果,每个结果表示为数据所在位置[0,11)和查找次数,中间用空格分开
样例查看模式?
正常显示查看格式
输入样例1?
6\n
11?23?39?48?75?62\n
6\n
39\n
52\n
52\n
63\n
63\n
52
输出样例1
6?1\n
error\n
8?1\n
error\n
8?2\n
8?1
AC代码
#include<bits/stdc++.h>
using namespace std;
map<int,int>mp;
list<int>l[11];
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++)
{
int x;
cin>>x;
mp[x]=1;
l[x%11].push_back(x);
}
int k;
cin>>k;
while(k--)
{
int x;
cin>>x;
int d=x%11;
if(mp[x]==0)
{
mp[x]=1;
l[d].push_back(x);
cout<<"error"<<endl;
}
else
{
int idx=0;
cout<<d<<" ";
for(auto t:l[d])
{
idx++;
if(t==x)
{
break;
}
}
cout<<idx<<endl;
}
}
return 0;
}E. DS哈希查找--Trie树
题目描述
Trie树又称单词查找树,是一种树形结构,如下图所示。
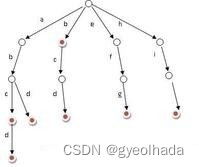
它是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来节约存储空间,最大限度地减少无谓的字符串比较,查询效率比哈希表高。
输入的一组单词,创建Trie树。输入字符串,计算以该字符串为公共前缀的单词数。
(提示:树结点有26个指针,指向单词的下一字母结点。)
输入
测试数据有多组
每组测试数据格式为:
第一行:一行单词,单词全小写字母,且单词不会重复,单词的长度不超过10
第二行:测试公共前缀字符串数量t
后跟t行,每行一个字符串
输出
每组测试数据输出格式为:
第一行:创建的Trie树的层次遍历结果
第2~t+1行:对每行字符串,输出树中以该字符串为公共前缀的单词数。
样例查看模式?
正常显示查看格式
输入样例1?
abcd?abd?bcd?efg?hig\n
3\n
ab\n
bc\n
abcde
输出样例1
abehbcficddggd\n
2\n
1\n
0
AC代码
#include<bits/stdc++.h>
using namespace std;
int sum=0;
int n;
class tri
{
public:
bool flag=0;
tri* next[26]={nullptr};
void insertt(string s)
{
tri* node=this;
for(int i=0;i<s.size();i++)
{
char c=s[i];
if(node->next[c-'a']==nullptr)
{
node->next[c-'a']=new tri();
}
node=node->next[c-'a'];
}
node->flag=1;
}
int find(string pre)
{
tri* node=this;
sum=0;
for(int i=0;i<pre.size();i++)
{
char c=pre[i];
if(node->next[c-'a']==nullptr)return 0;
node=node->next[c-'a'];
}
dfs(node);
return sum;
}
void dfs(tri* node)
{
tri* tr=new tri();
tr=node;
int tt=0;
for(int i=0;i<26;i++)
{
if(tr->next[i])
{
dfs(tr->next[i]);
tt=1;
}
}
if(tt==0)
{
sum++;
return;
}
}
void bfs()
{
tri *node=new tri();
node=this;
queue<tri*>q;
q.push(node);
while(!q.empty())
{
tri *t=q.front();
q.pop();
for(int i=0;i<26;i++)
{
if(t->next[i])
{
cout<<char('a'+i);
q.push(t->next[i]);
}
}
}
}
};
int main()
{
tri *tree=new tri();
string s;
getline(cin,s);
string k="";
for(int i=0;i<s.size();i++)
{
if(s[i]!=' ')
{
k+=s[i];
if(i==s.size()-1)
{
tree->insertt(k);
k.clear();
}
}
else
{
tree->insertt(k);
k.clear();
}
}
tree->bfs();
cout<<endl;
cin>>n;
while(n--)
{
string rr;
cin>>rr;
cout<<tree->find(rr)<<endl;
}
return 0;
}F. 逆散列问题
题目描述
给定长度为?N?的散列表,处理整数最常用的散列映射是?H(x)=x%N。如果我们决定用线性探测解决冲突问题,则给定一个顺序输入的整数序列后,我们可以很容易得到这些整数在散列表中的分布。例如我们将 1、2、3 顺序插入长度为 3 的散列表HT[]后,将得到HT[0]=3,HT[1]=1,HT[2]=2的结果。
但是现在要求解决的是“逆散列问题”,即给定整数在散列表中的分布,问这些整数是按什么顺序插入的?
输入
输入的第一行是正整数 N(≤1000),为散列表的长度。第二行给出了 N 个整数,其间用空格分隔,每个整数在序列中的位置(第一个数位置为0)即是其在散列表中的位置,其中负数表示表中该位置没有元素。题目保证表中的非负整数是各不相同的。
输出
按照插入的顺序输出这些整数,其间用空格分隔,行首尾不能有多余的空格。注意:对应同一种分布结果,插入顺序有可能不唯一。例如按照顺序 3、2、1 插入长度为 3 的散列表,我们会得到跟 1、2、3 顺序插入一样的结果。在此规定:当前的插入有多种选择时,必须选择最小的数字,这样就保证了最终输出结果的唯一性。
样例查看模式?
正常显示查看格式
输入样例1
11\n
33?1?13?12?34?38?27?22?32?-1?21
输出样例1
1?13?12?21?33?34?38?27?22?32
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=1e5;
struct key
{
int data;
int fact;
int suppose;
key(){}
key(int d,int i,int n)
{
data=d;
fact=i;
suppose=d%n;
}
};
int h[N];
key kk[N];
int st[N];
bool cmp(key a,key b)
{
return a.data<b.data;
}
int main(){
int n;
cin>>n;
int m=0;
for(int i=0;i<n;i++)
{
cin>>h[i];
if(h[i]==-1) st[i]=1;
else
{
kk[m]=key(h[i],i,n);
m++;
}
}
sort(kk,kk+m,cmp);
while(1)
{
int flag=0;
for(int i=0;i<m;i++)
{
if(kk[i].fact==kk[i].suppose&&st[kk[i].fact]==0){
cout<<kk[i].data<<" ";
st[kk[i].fact]=1;
break;
}
int tag=1;
int d=kk[i].fact-kk[i].suppose;
if(d<0) d=d+n;
for(int j=kk[i].suppose,k=0;k<d;j++,k++)
{
if(st[j%n]==0)
{
tag=0;
}
}
if(tag==1&&st[kk[i].fact]==0)
{
cout<<kk[i].data<<" ";
st[kk[i].fact]=1;
break;
}
}
for(int i=0;i<n;i++){
if(st[i]==0){
flag=1;
}
}
if(flag==0) break;
}
return 0;
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(二)
- Java数据结构与算法:动态规划之斐波那契数列
- 入门实战丨Python小游戏经典案例
- 每日算法打卡:移动距离 day 23
- 使用Robot Framework实现多平台自动化测试
- 【JavaScript】 细说JS数据处理方法,让你的数据表现出色如画
- 标题:探索C语言中的While循环结构
- Dryad数据库学习
- AcWing算法进阶课-1.1.2Dinic/ISAP求最大流
- js 获取元素宽高的几种方法