公用表达式 Common Table Expressions - CTE
目录
在介绍CTE之前先介绍一下子查询、派生表、临时表。
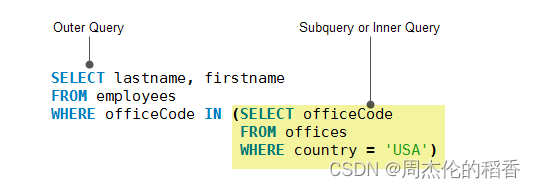
子查询
子查询是嵌套在另一个查询(如select、insert、update和delete)中的查询。子查询又称为内部查询,而包含子查询的查询称为外部查询。 子查询可以在使用表达式的任何地方使用,并且必须在括号中关闭。
派生表
派生表是从select语句返回的虚拟表。派生表类似于临时表,但是在SELECT语句中使用派生表比临时表简单得多,因为派生表没有创建临时表的步骤。派生表会在使用过后即时清除的,所以我们在简化复杂查询的时候可以考虑使用。
注意:派生表和子查询通常可以互换使用,但是与子查询不同的是,派生表必须具有别名。
派生表语法
SELECT column_list FROM
( SELECT column_list FROM table_1) derived_table_name --派生表
WHERE derived_table_name.c1 > 0;注意:派生表之间不可以相互引用。例如:SELECT ... FROM (SELECT ... FROM ...) AS d1, (SELECT ... FROM d1 ...) AS d2,第一个查询标记为d1,在第二个查询语句中使用d1是不允许的。
临时表
- 临时表是一种特殊类型的表,它允许您存储一个临时结果集,可以在单个会话中多次重用。
- 使用CREATE TEMPORARY TABLE语句创建临时表。请注意,在CREATE和TABLE关键字之间添加TEMPORARY关键字。
- 当会话结束或连接终止时,MySQL会自动删除临时表。当您不再使用临时表时,也可以使用DROP TABLE语句来显式删除临时表。
- 一个临时表只能由创建它的客户机访问。不同的客户端可以创建具有相同名称的临时表,而不会导致错误,因为只有创建临时表的客户端才能看到它。 但是,在同一个会话中,两个临时表不能共享相同的名称。
- 临时表可以与数据库中的普通表具有相同的名称。 不推荐使用相同名称。例如,如果在示例数据库(yiibaidb)中创建一个名为employees的临时表,则现有的employees表将变得无法访问。 对employees表发出的每个查询现在都是指employees临时表。 当删除您临时表时,永久employees表可以再次访问。
临时表语法
#创建临时表
CREATE TEMPORARY TABLE table_name (
name VARCHAR(10) NOT NULL,
value INTEGER NOT NULL
);
#删除临时表
drop temporary table table_name;什么是公用表达式
MySQL 从 8.0 开始支持 WITH 语法,即:Common Table Expressions - CTE,公用表表达式。官网:公用表达式
CTE(Common Table Expression,公共表表达式)是一个命名的临时结果集,它存在于单个语句的作用域中,以后可以在该语句中多次被引用。如下查询语句的with cte as (select 1 as one, 2 as two)
即为公共表表达式,它是一个命名的(名字叫cte)结果集,而且在该条语句中它可以被当做临时表来引用(最后的select语句引用了它)。初次接触CTE是不是感觉跟派生表子查询很像?没错!他们确实在某些方面很像,如它们都有名字、它们都在单条语句中生效。
CTE语法
CTE语法属于DML
with cte_name (column_list) as (
query
)
select * from cte_name;查询中的列数必须与 column_list 中的列数相同。 如果省略 column_list,CTE 将使用定义 CTE 的查询的列列表。
CTE示例
创建测试环境:
#创建department表
create table
department (
id bigint auto_increment comment '主键ID' primary key,
dept_name varchar(32) not null comment '部门名称',
parent_id bigint default 0 not null comment '父级id'
);
#插入数据
insert into
`department`
values
(null, '总部', 0),
(null, '研发部', 1),
(null, '测试部', 1),
(null, 'Java组', 2),
(null, 'Python组', 2),
(null, '前端组', 2),
(null, '供应链测试组', 3),
(null, '商城测试组', 3),
(null, '供应链产品组', 4),
(null, '商城产品组', 4),
(null, 'Java1组', 5),
(null, 'Java2组', 5);基本的CTE语法
with cte1 as (select * from `department` where id in (1, 2)),
cte2 as (select * from `department` where id in (2, 3))
select
*
from
cte1
join cte2
where
cte1.id = cte2.id;
一个CTE引用另一个CTE
with cte1 as (select * from `department` where id = 1),
cte2 as (select * from cte1)
select *
from cte2;
递归CTE
什么是递归CTE
RCTE(Recursive Common Table Expressions,递归公共表表达式)是一种会引用自身的CTE,一般用于生成序列、遍历层次数据结构。下面看一个生成1至10的序列样例。RCTE有如下几个特点:
- 必须使用with recursive定义,否则报错ERROR 1146 (42S02): Table '[db_name].[cte_name]' doesn't exist
- as后面定义的语句必须用小括号括起来
- 小括号中的查询语句包含两个select子句,两个select子句使用union all或者union distinct连接。第一个select的查询结果集作为初始数据集;第二个select是循环迭代部分
RCTE语法
with recursive cte_name as (
initial_query -- anchor member
union all
recursive_query -- recursive member that references to the cte name
)
select * from cte_name;递归CTE由三个主要部分组成
- 形成 CTE 结构的基本结果集的初始查询(initial_query),初始查询部分被称为锚成员;
- 递归查询部分是引用 CTE 名称的查询,因此称为递归成员。递归成员由一个 union all 或 union distinct 运算符与锚成员相连;
- 终止条件是当递归成员没有返回任何行时,确保递归停止。
递归CTE执行顺序
- 首先,将成员分为两个:锚点和递归成员。
- 接下来,执行锚成员形成基本结果集(R0),并使用该基本结果集进行下一次迭代。
- 然后,将 Ri 结果集作为输入执行递归成员,并将 Ri + 1 作为输出。
- 之后,重复第三步,直到递归成员返回一个空结果集,换句话说,满足终止条件。
- 最后,使用 union all 运算符将结果集从 R0 到 Rn 组合。
递归成员限制
- 聚合函数,如 max、min、sum、avg、count 等。
- group by 子句
- order by 子句
- limit 子句
- distinct
上述约束不适用于锚点成员。 另外,只有在使用 union 运算符时,要禁止 distinct 才适用。 如果使用 union distinct 运算符,则允许使用 distinct。
递归CTE示例
with recursive cte_count (n)
as (
select 1
union all
select n + 1
from cte_count
where n < 3
)
select n from cte_count;select 1是作为基本结果集返回1的锚成员;
select n + 1 from cte_count where n < 3是递归成员,因为它引用了 cte_count 的 CTE 名称。递归成员中的表达式 < 3 是终止条件。当 n 等于 3,递归成员将返回一个空集合,将停止递归。
下图显示了上述CTE的元素:

递归CTE返回以下输出:
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
+------+示例执行步骤
- 首先,分离锚和递归成员;
- 接下来,锚定成员形成初始行 select 1,因此第一次迭代在 n = 1 时产生 1 + 1 = 2;
- 然后,第二次迭代对第一次迭代的输出 2 进行操作,并且在 n = 2 时产生 2 + 1 = 3;
- 之后,在第三次操作 n = 3 之前,满足终止条件 n <3 ,因此查询停止;
- 最后,使用 union all 运算符组合所有结果集 1,2 和 3。
使用RCTE遍历department表
#查询部门id=2的所有下级部门和本级
with recursive
cte_tab as (
select
id,
dept_name,
parent_id,
1 as level
from
department
where
id = 2
union all
select
d.id,
d.dept_name,
d.parent_id,
level + 1
from
cte_tab c
inner join department d on c.id = d.parent_id
)
select
*
from
cte_tab;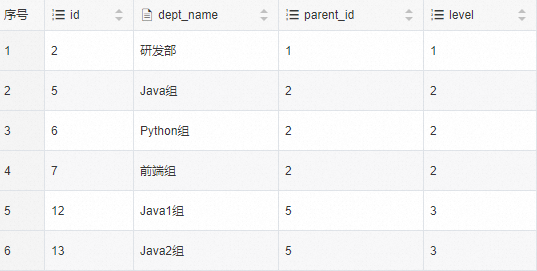
CTE&Derived Table
针对 from 子句里面的 subquery,MySQL 在不同版本中,是做过一系列的优化,接下来我们就来看看。
5.6版本中
MySQL 会对每一个 Derived Table 进行物化,生成一个临时表保存 Derived Table 的结果,然后利用临时表来完成父查询的操作,具体如下:
explain
select
*
from
(
select
*
from
department
where
id <= 1000
) t1
join (
select
*
from
department
where
id >= 990
) t2 on t1.id = t2.id;
5.7版本中
MySQL 引入了 Derived Merge 新特性,允许符合条件的 Derived Table 中的子表与父查询的表进行合并,具体如下:
explain
select
*
from
(
select
*
from
department
where
id <= 1000
) t1
join (
select
*
from
department
where
id >= 990
) t2 on t1.id = t2.id;
8.0版本
我们可以使用 CTE 实现,其执行计划也是和 Derived Table 一样
explain
with
t1 as (
select
*
from
department
where
id <= 1000
),
t2 as (
select
*
from
department
where
id >= 990
)
select
*
from
t1
join t2 on t1.id = t2.id;
从测试结果来看,CTE 似乎是 Derived Table 的一个替代品?其实不是的,虽然 CTE 内部优化流程与 Derived Table 类似,但是两者还是区别的,具体如下:
- 派生表在查询语句中只能引用一次,而CTE可以引用多次
- CTE可以引用自身(递归)
- CTE可以引用其他CTE
- CTE相比排查表可读性更高,CTE在语句开头定义临时结果集而不是像派生表一样嵌入到查询语句中
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鸿蒙开发笔记(七):应用状态管理,LocalStorage及AppStorage的使用
- 深度解析Android APP加固中的必备手段——代码混淆技术
- 微服务(8)
- 数据共享与隐私保护:如何取得平衡?
- 计算机Java项目|电影购票系统
- R语言piecewiseSEM结构方程模型在生态环境领域实践技术应用
- C语言程序设计 循环结构
- 勇哥带您手搓一个信息发布系统CMS(3)--thymeleaf使用中通用方法设计
- 从浮点数度分秒1.40000中无损精度提取1度40分00.0秒的方法
- java客户关系管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目