竞赛保研 python的搜索引擎系统设计与实现
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 python的搜索引擎系统设计与实现
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:5分
- 创新点:3分
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题简介
随着互联网和宽带上网的普及, 搜索引擎在中国异军突起, 并日益渗透到人们的日常生活中, 在互联网普及之前,
人们查阅资料首先想到的是拥有大量书籍的资料的图书馆。 但是今天很多人都会选择一种更方便、 快捷、 全面、 准确的查阅方式–互联网。
而帮助我们在整个互联网上快速地查找到目标信息的就是越来越被重视的搜索引擎。
今天学长来向大家介绍如何使用python写一个搜索引擎,该项目常用于毕业设计
2 系统设计实现
2.1 总体设计
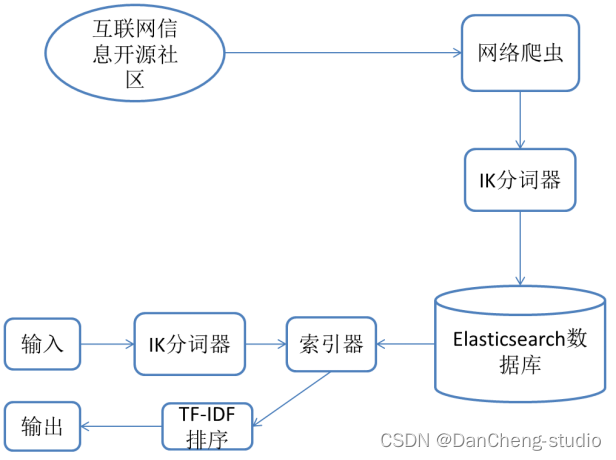
学长设计的系统采用的是非关系型数据库Elasticsearch,因此对于此数据库的查询等基本操作会加以图例的方式进行辅助阐述。在使用者开始进行査询时,系统不可能把使用者输入的关键词与所有本地数据进行匹配,这种检索方式即便建立索引,查询效率仍然较低,而且非常消耗服务器资源。
因此,Elasticsearch将获取到的数据分为两个阶段进行处理。第一阶段:采用合适的分词器,将获取到的数据按照分词器的标准进行分词,第二阶段:对每个关键词的频率以及出现的位置进行统计。
经过以上两个阶段,最后每个词语具体出现在哪些文章中,出现的位置和频次如何,都将会被保存到Elasticsearch数据库中,此过程即为构建倒排索引,需要花费的计算开销很大,但大大提高了后续检索的效率。其中,搜索引擎的索引过程流程图如图

2.2 搜索关键流程
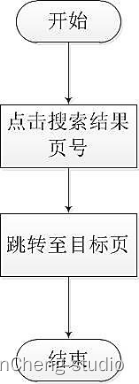
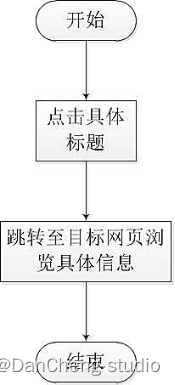
如图所示,每一位用户在搜索框中输入关键字后,点击搜索发起搜索请求,系统后台解析内容后,将搜索结果返回到查询结果页,用户可以直接点击查询结果的标题并跳转到详情页,也可以点击下一页查看其他页面的搜索结果,也可以选择重新在输入框中输入新的关键词,再次发起搜索。
跳转至不同结果页流程图:
浏览具体网页信息流程图:
搜索功能流程图:

2.3 推荐算法
用户可在平台上了解到当下互联网领域中的热点内容,点击文章链接后即可进入到对应的详情页面中,浏览选中的信息的目标网页,详细了解其中的内容。丰富了本搜索平台提供信息的实时性,如图
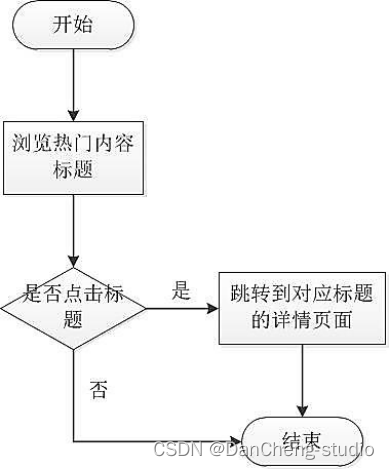
用户可在搜索引擎首页中浏览到系统推送的可能感兴趣的内容,同时用户可点击推送的标题进入具体网页进行浏览详细内容。流程图如图

2.4 数据流的实现
学长设计的系统的数据来源主要是从发布互联网专业领域信息的开源社区上爬虫得到。
再经过IK分词器对获取到的标题和摘要进行分词,再由Elasticsearch建立索引并将数据持久化。
用户通过输入关键词,点击检索,后台程序对获得的关键词再进行分词处理,再到数据库中进行查找,将满足条件的网页标题和摘要用超链接的方式在浏览器中显示出来。
3 实现细节
3.1 系统架构
搜索引擎有基本的五大模块,分别是:
- 信息采集模块
- 信息处理模块
- 建立索引模块
- 查询和 web 交互模块
学长设计的系统目的是在信息处理分析的基础上,建立一个完整的中文搜索引擎。
所以该系统主要由以下几个详细部分组成:
- 爬取数据
- 中文分词
- 相关度排序
- 建立web交互。
3.2 爬取大量网页数据
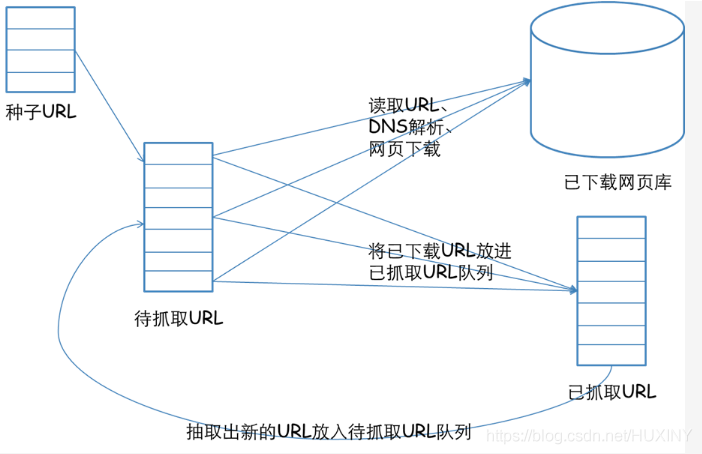
爬取数据,实际上用的就是爬虫。
我们平时在浏览网页的时候,在浏览器里输入一个网址,然后敲击回车,我们就会看到网站的一些页面,那么这个过程实际上就是这个浏览器请求了一些服务器然后获取到了一些服务器的网页资源,然后我们看到了这个网页。
请求呢就是用程序来实现上面的过程,就需要写代码来模拟这个浏览器向服务器发起请求,然后获取这些网页资源。那么一般来说实际上获取的这些网页资源是一串HTML代码,这里面包含HTML标签,还有一
我们写完程序之后呢就让它一直运行着,它就能代替我们浏览器来向服务器发送请求,然后一直不停的循环的运行进行批量的大量的获取数据了,这就是爬虫的一个基本的流程。
一个通用的网络爬虫的框架如图所示:
这里给出一段爬虫,爬取自己感兴趣的网站和内容,并按照固定格式保存起来:
? # encoding=utf-8
? # 导入爬虫包
? from selenium import webdriver
? # 睡眠时间
? import time
? import re
? import os
? import requests
? # 打开编码方式utf-8打开
?
# 睡眠时间 传入int为休息时间,页面加载和网速的原因 需要给网页加载页面元素的时间
def s(int):
time.sleep(int)
?
? # html/body/div[1]/table/tbody/tr[2]/td[1]/input
? # http://dmfy.emindsoft.com.cn/common/toDoubleexamp.do
?
if __name__ == '__main__':
#查询的文件位置
# fR = open('D:\\test.txt','r',encoding = 'utf-8')
# 模拟浏览器,使用谷歌浏览器,将chromedriver.exe复制到谷歌浏览器的文件夹内
chromedriver = r"C:\\Users\\zhaofahu\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe"
# 设置浏览器
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
# 最大化窗口 用不用都行
browser.maximize_window()
# header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
# 要爬取的网页
neirongs = [] # 网页内容
response = [] # 网页数据
travel_urls = []
urls = []
titles = []
writefile = open("docs.txt", 'w', encoding='UTF-8')
url = 'http://travel.yunnan.cn/yjgl/index.shtml'
# 第一页
browser.get(url)
response.append(browser.page_source)
# 休息时间
s(3)
# 第二页的网页数据
#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()
#s(3)
#response.append(browser.page_source)
#s(3)
# 第三页的网页数据
#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()
#s(3)
#response.append(browser.page_source)
?
? # 3.用正则表达式来删选数据
? reg = r'href="(//travel.yunnan.cn/system.*?)"'
? # 从数据里爬取data。。。
? # 。travel_urls 旅游信息网址
? for i in range(len(response)):
? travel_urls = re.findall(reg, response[i])
?
# 打印出来放在一个列表里
for i in range(len(travel_urls)):
url1 = 'http:' + travel_urls[i]
urls.append(url1)
browser.get(url1)
content = browser.find_element_by_xpath('/html/body/div[7]/div[1]/div[3]').text
# 获取标题作为文件名
b = browser.page_source
travel_name = browser.find_element_by_xpath('//*[@id="layer213"]').text
titles.append(travel_name)
print(titles)
print(urls)
for j in range(len(titles)):
writefile.write(str(j) + '\t\t' + titles[j] + '\t\t' + str(urls[j])+'\n')
s(1)
browser.close()
##
3.3 中文分词
中文分词使用jieba库即可
jieba 是一个基于Python的中文分词工具对于一长段文字,其分词原理大体可分为三步:
1.首先用正则表达式将中文段落粗略的分成一个个句子。
2.将每个句子构造成有向无环图,之后寻找最佳切分方案。
3.最后对于连续的单字,采用HMM模型将其再次划分。
jieba分词分为“默认模式”(cut_all=False),“全模式”(cut_all=True)以及搜索引擎模式。对于“默认模式”,又可以选择是否使用
HMM 模型(HMM=True,HMM=False)。
3.4 相关度排序
上面已经根据用户的输入获取到了相关的网址数据。
获取到的数据中rows的形式如下
[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3…),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3…)]
列表的每个元素是一个元组,每个元素的内容是urlid和每个关键词在该文档中的位置。
wordids形式为[wordid1, wordid2, wordid3…],即每个关键词所对应的单词id
我们将会介绍几种排名算法,所谓排名也就是根据各自的规则为每个链接评分,评分越好。并且最终我们会将几种排名算法综合利用起来,给出最终的排名。既然要综合利用,那么我们就要先实现每种算法。在综合利用时会遇到几个问题。
1、每种排名算法评分机制不同,给出的评分尺度和含义也不尽相同
2、如何综合利用,要考虑每种算法的效果。为效果好的给与较大的权重。
我们先来考虑第一个问题,如何消除每种评分算法所给出的评分尺度和含义不相同的问题。
第2个问题,等研究完所有的算法以后再来考虑。
简单,使用归一化,将每个评分值缩放到0-1上,1代表最高,0代表最低。
对爬去到的数据进行排序, 有好几种排序算法:
第1个排名算法:根据单词位置进行评分的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的位置越靠前越好。比如我们往往习惯在文章的前面添加一些摘要性、概括性的描述。
# 根据单词位置进行评分的函数.
# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]
? def locationscore(self,rows):
? locations=dict([(row[0],1000000) for row in rows])
? for row in rows:
? loc=sum(row[1:]) #计算每个链接的单词位置总和,越小说明越靠前
? if loc<locations[row[0]]: #记录每个链接最小的一种位置组合
? locations[row[0]]=loc
?
return self.normalizescores(locations,smallIsBetter=1)
####
第2个排名算法:根据单词频度进行评价的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的次数越多越好。比如我们在指定主题的文章中会反复提到这个主题。
# 根据单词频度进行评价的函数
# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]
def frequencyscore(self,rows):
counts=dict([(row[0],0) for row in rows])
for row in rows:
counts[row[0]]+=1 #统计每个链接出现的组合数目。 每个链接只要有一种位置组合就会保存一个元组。所以链接所拥有的组合数,能一定程度上表示单词出现的多少。
return self.normalizescores(counts)
第3个排名算法:根据单词距离进行评价的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的越紧凑越好。这是因为我们更希望所有单词出现在一句话中,而不是不同的关键词出现在不同段落或语句中。
? # 根据单词距离进行评价的函数。
? # rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]
? def distancescore(self,rows):
? # 如果仅查询了一个单词,则得分都一样
? if len(rows[0])<=2: return dict([(row[0],1.0) for row in rows])
?
# 初始化字典,并填入一个很大的值
mindistance=dict([(row[0],1000000) for row in rows])
for row in rows:
dist=sum([abs(row[i]-row[i-1]) for i in range(2,len(row))]) # 计算每种组合中每个单词之间的距离
if dist<mindistance[row[0]]: # 计算每个链接所有组合的距离。并为每个链接记录最小的距离
mindistance[row[0]]=dist
return self.normalizescores(mindistance,smallIsBetter=1)
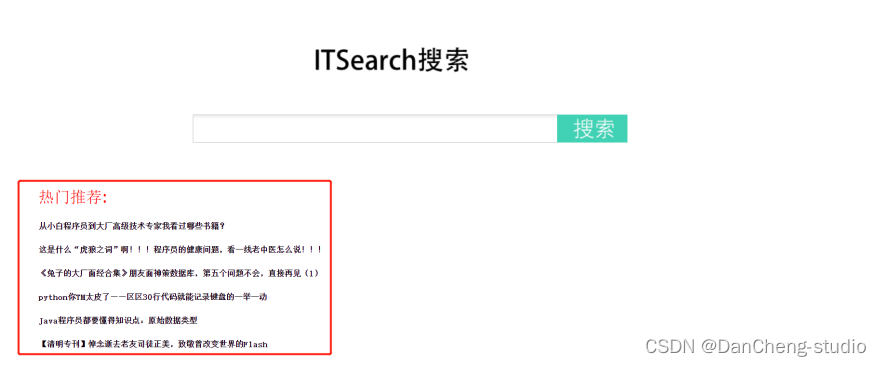
4 实现效果
热门主题推荐实现
搜索界面的实现

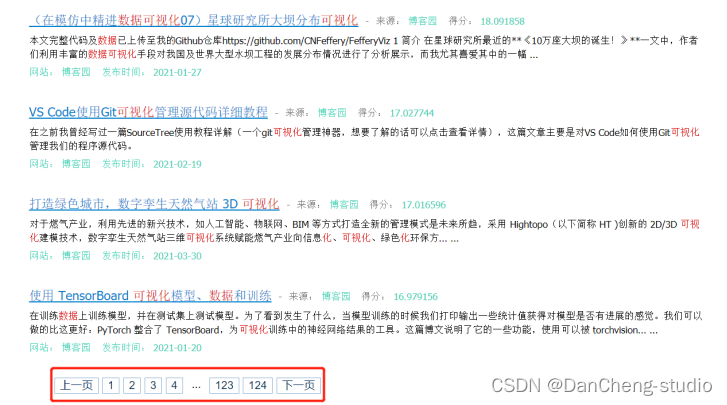
查询结果页面显示
查询结果分页显示
查询结果关键字高亮标记显示
4 最后
🧿 更多资料, 项目分享:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 蓝桥杯省赛无忧 课件31 离散化
- 数据仓库开发规范示例
- 揭秘华为的退休真相,各种待遇细节曝光...
- 静态网页设计——奥迪官网(HTML+CSS+JavaScript)
- 【Spring源码分析】执行流程之非懒加载单例Bean的实例化逻辑
- CNN——LeNet
- Spring Boot快速搭建一个简易商城项目三,【加入购物车篇】
- 设计模式--工厂方法模式
- yolov5模型Detection输出内容与源码详细解读
- 【C++】IO流