计算机体系结构期末复习流程大纲
1.存储器和cache
存储器的容量、速度与价格之间的要求是相互矛盾的,速度越快,没bit位价格越高,容量越大,速度越慢,目前主存一般有DRAM构成。
处理器CPU访问存储器的指标:
- 延迟时间(Latency)——单次存储器的访问时间:存储器访问时间>> 处理器时钟周期;
- 带宽 (Bandwidth)——单位时间对存储器的访问次数:如果每条指令的执行需要m次访存操作,总计每条指令需要m+1次存储器访问(包括1次取指令),如果CPI = 1,则每个指令周期需要访存m+1;
- 能耗 (Energy) -单次存储器访问消耗的能量 (nJ)

存储系统的设计目标:针对典型应用,使访存时间最短,通过优化存储系统组织架构,进行多级分层:M1速度最快,容量最小;
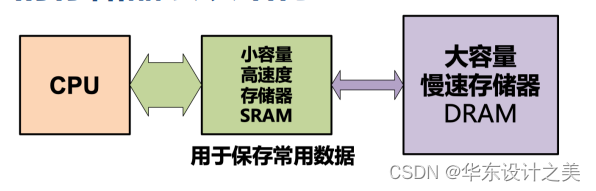
size(容量):?Register << SRAM << DRA;
Latency(延迟时间): Register << SRAM << DRAM;
Bandwidth(带宽): on-chip >> off-chip
多级存储的目的是通过合理组织和层次化存储系统,提高计算机系统的 性能、效率和容量,以满足不同应用场景下的需求
策略(Strategy):使用小容量、高速存储器作为Cache,来降低平均访存延迟;
缓存(Cache):是一种减少访存延迟的机制,它基于经验观察,即处理器进行的 内存访问模式通常是高度可预测的。
存储器访问有两种可预测的模式:
- 时间局部性( Temporal Locality ):如果一个地址被访问过,在不久的 将来很可能还会被访问。保持最近访问的数据项最接近微处理器;
- 空间局部性( Spatial Locality ):如果一个地址被访问过,在不久的将来 该地址的临近地址很可能会被访问到。以由地址连续的若干个字构成的块为单位,从低层复制到上一层。
2.一致性问题
如何正确有序访问共享存储系统:
- 存储一致性(Consistency):不同处理器发出的所有存储器操作的顺序问题(即针对不同存储单元或相同存储 单元) ;所有存储器访问的全序问题;
- Cache一致性(Coherence) :不同处理器访问相同存储单元时的访问顺序问题;访问每个Cache块的局部序问题。
Cache一致性的问题:多个处理器或核心之间共享数据时,由于Cache的存在,可能导致不同处理器对同一块内存数据的缓存内容不一致的情况。
Cache一致性协议的关键在于:跟踪共享数据块的状态。
跟踪共享数据块状态的cache协议有两种:
- Snooping-based protocols (基于监听的协议) : 每个Cache除了包含物理存储器中块的数据拷贝之外,也保存着各个块的共享状态信息。
- Directory-based protocols (基于目录的协议): 物理存储器中共享数据块的状态及相关信息均被保存在一个称为目录的地方。
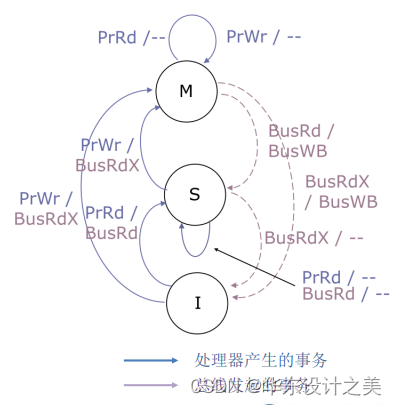
MSI(Modified/Shared/Invalid)协议有三种状态:Modified:只有该数据块的备份是最新的,主存和其他处理器中的数据是陈旧的; Shared:该数据块在此处理器中未被修改过,主存中的内容是最新的;Invalid:该数据块是无效块。
基于监听的Cache一致性局限性:
- 监听协议需要通过总线广播请求:共享总线存在竞争使用问题;在由大量处理器构成的多处理器系统中,监听带宽会成为瓶颈;总线上能够连接的处理器数目有限,难扩展到处理器规模较大的系统;
- 监听协议只适用于可伸缩性差的共享总线结构;
- 如何不采用广播方式而保持缓存一致性:使用目录 (directory) 记录每个Cache块的状态;只有包含该数据块的缓存才会收到请求。
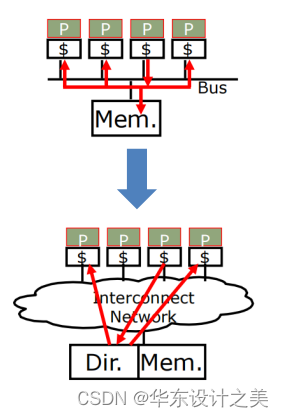
基于目录的Cache一致性:
- 目录协议对监听协议的改进

- 每个存储块对应一个目录项

MSI目录协议:
Cache状态:Modified(M)/ Shared(S)/ Invalid(I)
目录状态:Uncached(Un):所有处理器核心都没有数据副本;Shared(Sh):一个或多个处理器核具有读权限(S);Exclusive(Ex):只有一个处理器核具有读和写权限(M);

3.顺序一致性
顺序一致性(Sequential Consistency) : 该模型要求所有处理器的读、写和交换(swap)操作以某种序执行所形成的全局存储器次序,符合各处理器的原有程序次序。
即, 不论指令流如何交叠执行,全局序必须保持所有进程的程序:所有读写操作执行以某种顺序执行;每一个处理器看到的操作顺序是相同的。

完全存储定序模型(Total Store Order(TSO)):
完全存储定序模型规则:
- 全局顺序存储: store操作存在一个全局的顺序;
- Store缓冲: 允许处理器使用 Store buffer来缓存即将写入内存的数据,但必须确保缓冲中的数据在全局上有序提交;
- load同样按顺序执行,但可穿插到多个store执行过程中:若存在一组store->load操作,如果由同一处理器执行且地址相关,则TSO允许该load操作在store操作完成之前就执行;但如果由多个core执行且地址相关,那TSO要求load指令在store执行完成后才能执行。
4.并行计算
Level of Parallelism并行级别:
- 指令级并行 (ILP Instruction-level Parallelism):定义:在单个处理器上同时执行多条指令的能力;实现方式:通过在一个时钟周期内执行多个指令的部分,例如流水线处理、超标量处理和乱序执行等技术;
- 数据级并行 (DLP Data-level Parallelism):定义:同时处理多个数据元素的能力;实现方式: 通过向量处理器、SIMD (单指令多数据)架构等技术,在单个指令下并行处理多个数据元素;
- 线程级并行 ( TLP Thread-level Parallelism ):定义:任务被组织成多个线程,在多线程环境中同时执行多个线程的能力;实现方式:通过多核处理器、多处理器系统或者通过超线程技术,在不同的执行单元上并行执行多个线程。
如何使CPI<1,有两种基本方法:: Superscalar 、VLIW;
Superscalar:
- 特点:具有多个执行单元,能够在同一时钟周期内同时发射和执行多条指令;
- 硬件结构复杂:需要支持动态调度和处理指令之间的相关性;
- IBM PowerPC, Sun UltraSparc, DEC Alpha, HP 8000;
- 该方法对目前通用计算是最成功的方法。
Very Long Instruction Words (VLIW):
- 特点:每个时钟周期流出的指令数是固定的;
- 硬件结构简单:指令的执行顺序在编译时已知,处理器只需要静态调度逻辑。
多线程策略:保证一条流水线上的指令之间不存在数据依赖关系。
一种办法: 在相同的流水线中交叉执行来自不同线程的指令。

同步多线程 (Simultaneous Multithreading (SMT)):SMT 使用Oo0 Superscalar细粒度控制技术在相同时钟周期运行多个线程的指令,以更好的利用系统资源;
Alpha AXP 21464;Intel Pentium 4,Intel Nehalem i7 [超线程(Hyper-Threading)](Intel的超线程一直都是SMT2,一个物理核虚拟出两个逻辑核);IBM Power5。

评估指标 (算力指标)
Flop:浮点运算,通常为双精度;
Flop/s(Flops):每秒浮点运算次数;
Flops=【CPU核数】*【单核主频】*【CPU单个周期浮点计算能力】;
以Intel Xeon 6348 CPU为例;
28核,主频2.6GHz,支持AVX512指令集,且FMA系数=2;
CPU单周期单精度浮点计算能力=2(FMA数量)*2(同时加法和乘法)*512/32=64;
CPU单周期双精度浮点计算能力=2(FMA数量)*2(同时加法和乘法)*512/64=32;
6348的单精度算力=28x2.6x64=4659Gflops=4.6Tflops;
6348的双精度算力=28x2.6x32=2329Gflops=2.3Tflops。
5.SIMD和向量处理器
向量处理器具有更高层次的操作,一条向量指令可以同时处理N个或N 对操作数(处理对象是向量);
向量处理器的基本特性:
- 基本思想:两个向量的对应分量进行运算,产生一个结果向量;
- 简单的一条向量指今包含了多个操作 -> fewer instruction fetches;
- 每一条结果独立于前面的结果:?长流水线,编译器保证操作间没有相关性;硬件仅需检测两条向量指令间的相关性;较高的时钟频率;
- 向量指令以已知的模式访问存储器:可有效发挥多体交叉存储器的优势;不需要数据Cache (仅使用指令Cache);
- 在流水线控制中减少了控制Hazard:有效利用流水线并发执行指令。

向量处理器单元结构:采用多流水线lane设计,lane:包含向量寄存器堆的一部分和来自每个向量功能单元的一个执行流水线。
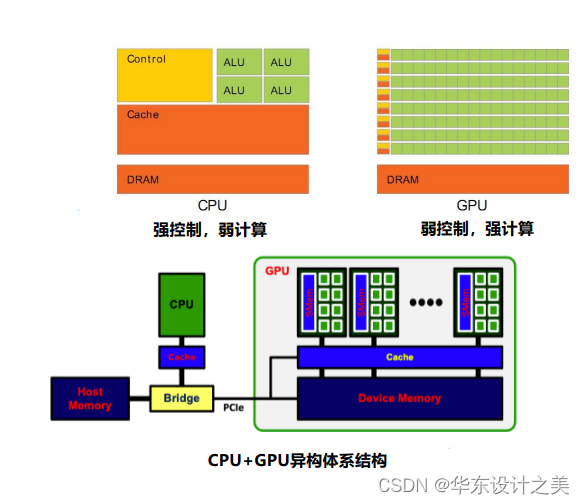
6.GPU体系结构
GPU计算系统
CPU+GPU异构体系结构:推动异构计算的发展;针对每个任务选择合适的处理器和存储器;
通用CPU 适合执行一些串行的线程:串行执行快;带有cache,访问存储器延时低;
GPU适合执行大量并行线程:可扩展的并行执行;高带宽的并行存取。
7.硬件加速器
(领域专用体系结构)加速器
加速器是面向特定领域、针对有限算法定制设计的专用计算架构其目的是提升特定计算的性能或减少功耗需求,可分为:机器学习加速器;图计算加速器;同态加密加速器。
8.微码和超长指令字VLIW处理器
微码技术并不会被淘汰:
- 现代微处理器中微程序控制扮演辅助的角色;
- 芯片bug的漏洞修复(基于微码的修复和升级)。
超长指令字VLIW定义:
- 提高指令级并行 (ILP) 的有效方法:流水线,多处理器,超标量处理器,超长指令字VLIW;
- 定义: VLIW指的是一种被设计为可以利用指今级并行 (ILP) 优势的CPU体系结构,由于在一条指今中封装了多个并行操作,其指令的长度比RISC或CISC的指令要长,因此起名为超长指令集;
- VS.超标量处理器:相同:一次发射并完成多个操作,提高ILP;不同:超标量:要复杂逻辑发现指令之间的数据依赖关系,以及乱序执行逻辑和超标量架构来实现多指令的并行发射;VLIW: 通过编译器对并发操作进行了编码,这种显式编码极大地降低了硬件的复杂性。
VLIW: Very Long Instruction Word
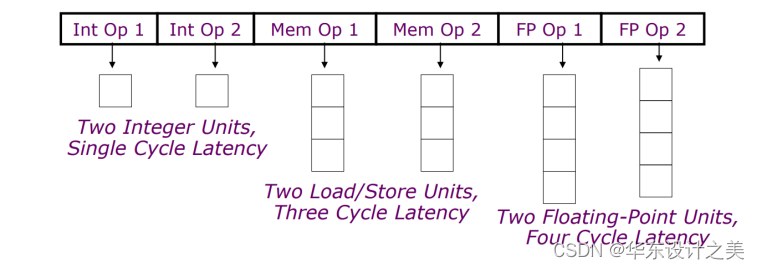
- 定长指令,将多个相互无依赖关系的指令封装到一条超长的指令字中;
- 每个操作槽 (slot) 均用于固定的功能;
- 每个功能单元的operation都声明了固定的延迟。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【2024全网最火最全性能教程】一文搞懂性能测试!
- 【智安网络|升级企业安全标准与运维效能:解析堡垒机与云堡垒机的关键作用
- U盘数据恢复软件,高效恢复数据记好这2款!
- JavaScript基础--布尔类型,空型和未定义
- CentOS 防火墙管理及使用的redis基本常用命令
- “纯血版”鸿蒙有未来吗?程序员的“暖冬”
- 外包干了3个月,技术退步明显。。。
- STM32WL用户手册学习
- 开源投票微信小程序源码系统+超强的盈利模式+礼物道具刷不停+完整的代码包 附带安装部署教程
- (十八)Kubernetes系列之存储(网络存储卷)