C++内存管理和模板初阶
C/C++内存分布
请看代码:
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
char char2[] = "abcd";
const char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}
请看题目
选项 : A.栈 B.堆 C.数据段(静态区) D.代码段(常量区)
globalVar在哪里?__C__ staticGlobalVar在哪里?__C__
staticVar在哪里?__C__ localVar在哪里?__A__
num1 在哪里?__A__
char2在哪里?__A__ * char2在哪里?__A_
pChar3在哪里?__A__ * pChar3在哪里?__A__
ptr1在哪里?__A__ * ptr1在哪里?__B__
通过之前C语言的学习我们可以知道,内存区域主要分为几个区:
从上至下分别是栈,堆,静态区,常量区
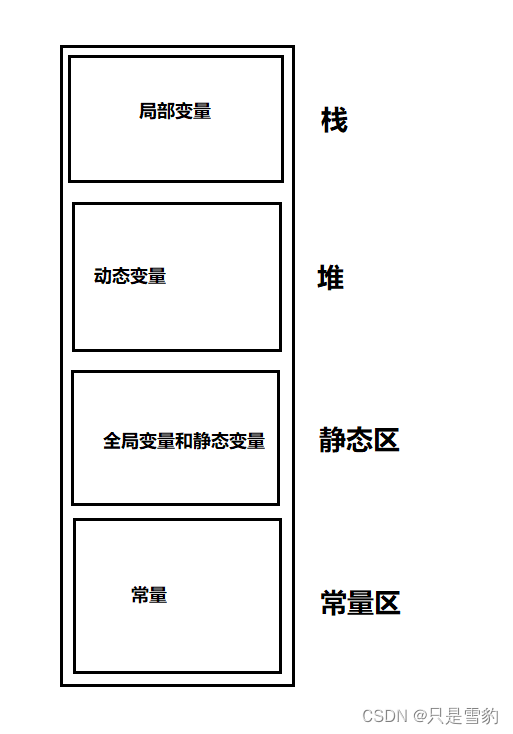
const修饰的变量就是常量,放在常量区。局部变量放在栈,它是由编译器自动分配释放的。堆区主要存放动态变量,需要用户自我管理和分配。静态区就是主要存放全局变量和静态变量的。
在C++中的内存也是相似的:
下面给出一个对比:
数据段就是我们所说的静态区
代码段就是常量区

这里给出说明:
- 栈又叫堆栈–非静态局部变量/函数参数/返回值等等,栈是向下增长的。
- 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。
- 堆用于程序运行时动态内存分配,堆是可以上增长的。
- 数据段–存储全局数据和静态数据。
- 代码段–可执行的代码/只读常量。
向上增长就是说由低地址指向高地址,而向下增长则相反
C语言中动态内存管理方式:malloc/calloc/realloc/free
我们知道,在C语言中我们分别用malloc/calloc/realloc来开辟动态空间
我们想再来回忆一下三者的区别:
malloc只是开辟空间,不会初始化
calloc开辟空间并且初始化
realloc在可以在原本的空间上扩容,也可以重新开辟新的空间
下面我们看一段代码:
void Test()
{
int* p1 = (int*)malloc(sizeof(int));
free(p1);
int* p2 = (int*)calloc(4, sizeof(int));
int* p3 = (int*)realloc(p2, sizeof(int) * 10);
free(p2);
free(p3);
}
运行代码你就会发现:
代码会发生异常
因为扩容10个int类型的空间在原本的空间上足够了,所以是在本地扩容,不需要free这里原本开辟好的空间p2,但是如果把这里realloc的10改成100,就是异地扩容了,就需要free p2,防止内存泄漏
C++内存管理方式
我们通常说到,C++是兼容C的,那么C语言中的内存管理方式可以用到C++中吗?
答案是肯定的!
C语言内存管理方式在C++中可以继续使用,但有些地方就无能为力,而且使用起来比较麻烦,因此C++又提出了自己的内存管理方式:通过new和delete操作符进行动态内存管理。
new/delete操作内置类型
相比较C语言的内存管理方式,这里有很大的区别,并且这里设计的本意是为自定义类型而生的!
关于他们的特征我们稍后进行讲解
我们用代码来看会更加地的清晰:
可以看到,new在不用进行强制的类型转换
void Test()
{
// 动态申请一个int类型的空间
int* ptr4 = new int;
// 动态申请一个int类型的空间并初始化为10
int* ptr5 = new int(10);
// 动态申请10个int类型的空间
int* ptr6 = new int[3];
delete ptr4;
delete ptr5;
delete[] ptr6;
}
给出一个图,大家就可以更好地理解:
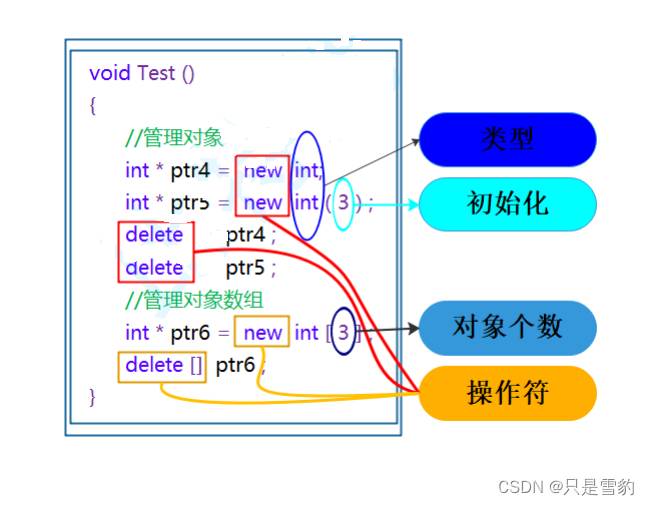
总结下来就是:
申请和释放单个元素的空间,使用new和delete操作符,申请和释放连续的空间,使用new[]和delete[],注意:匹配起来使用。
new/delete操作内置类型
请看代码:
class A
{
public:
A(int a = 0)
: _a(a)
{
cout << "A():" << this << endl;
}
~A()
{
cout << "~A():" << this << endl;
}
private:
int _a;
};
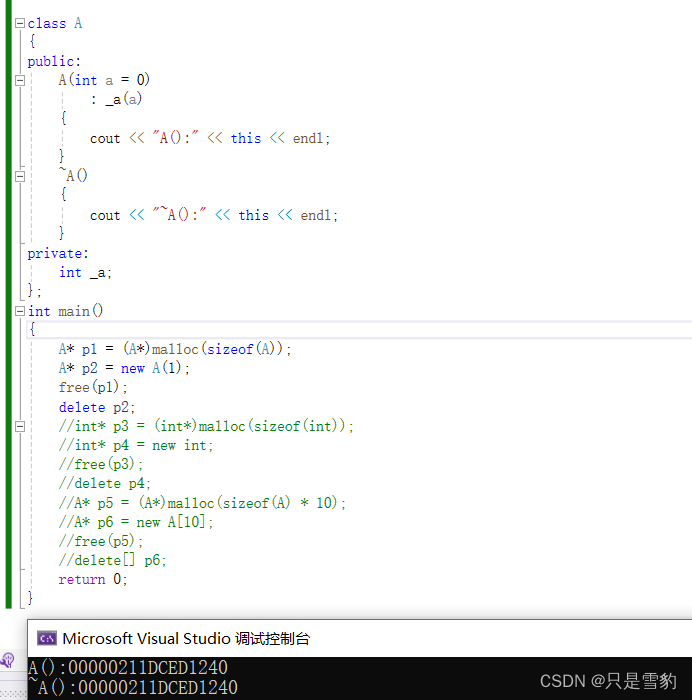
int main()
{
A* p1 = (A*)malloc(sizeof(A));
A* p2 = new A(1);
free(p1);
delete p2;
int* p3 = (int*)malloc(sizeof(int));
int* p4 = new int;
free(p3);
delete p4;
return 0;
}
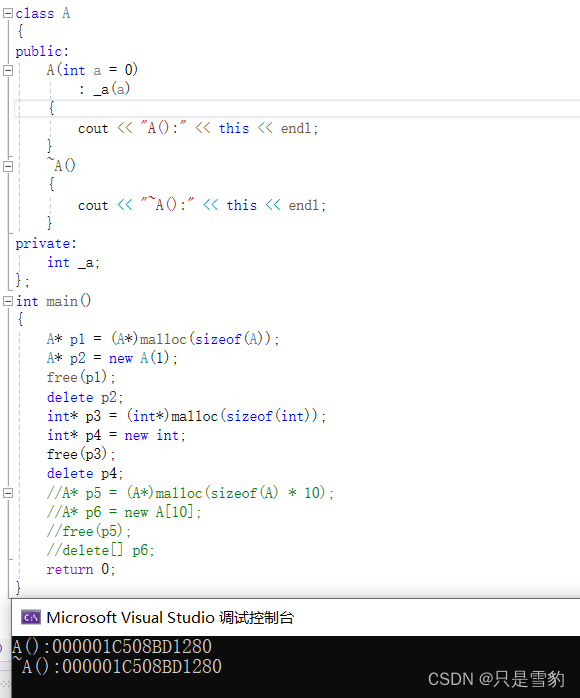
运行结果:
这就说明new在为自定义类型申请空间的时候调用了类的构造函数,而delete在清理空间时调用了析构函数
而我们再加两行代码:
class A
{
public:
A(int a = 0)
: _a(a)
{
cout << "A():" << this << endl;
}
~A()
{
cout << "~A():" << this << endl;
}
private:
int _a;
};
int main()
{
A* p1 = (A*)malloc(sizeof(A));
A* p2 = new A(1);
free(p1);
delete p2;
int* p3 = (int*)malloc(sizeof(int));
int* p4 = new int;
free(p3);
delete p4;
return 0;
}
运行结果如下:
这就说明了对于内置类型,new和delete和malloc和free没有差别,这就验证了我之前提到的:
new和delete是为自定义类型而生的!
下面我们看多个元素开辟和释放:
可以看到,我们开辟十个的话就会调用十次构造函数和析构函数
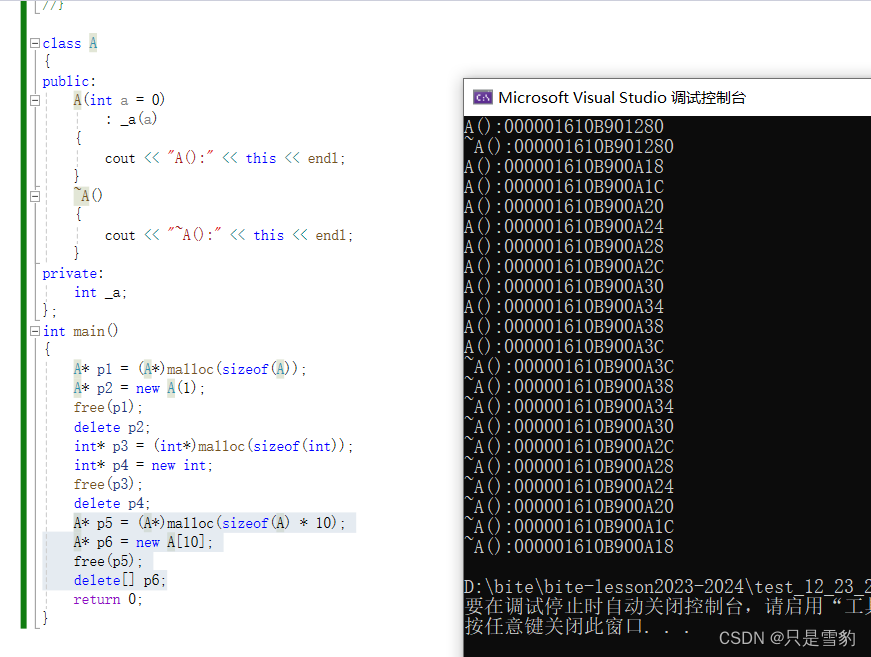
这就是一个需要注意的点:
在申请自定义类型的空间时,new会调用构造函数,delete会调用析构函数,而malloc与free不会。new和delete是两个操作符,而malloc和free是两个函数
operator new与operator delete函数
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间。
也就是说,new和delete这两个操作符的实习实际上是靠这两个函数的调用所实现的!
但是通过汇编语言来看:
operator new 实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete 最终是通过free来释放空间的。
new和delete的实现原理
内置类型
如果申请的是内置类型的空间,new和malloc,delete和free基本类似,不同的地方是:new/delete申请和释放的是单个元素的空间,new[]和delete[]申请的是连续空间,而且new在申请空间失败时会抛异常,malloc会返回NULL。
自定义类型
new的原理
- 调用operator new函数申请空间
- 在申请的空间上执行构造函数,完成对象的构造
delete的原理
- 在空间上执行析构函数,完成对象中资源的清理工作
- 调用operator delete函数释放对象的空间
new T[N]的原理
- 调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
- 在申请的空间上执行N次构造函数
delete[]的原理
- 在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
- 调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释
放空间
模板初阶
泛型编程
在之前的C语言学习中我们常常用到swap函数,但是我们的swap的类型不确定就可能需要用函数重载,或者选择方便的typedef关键字来简化代码:
例如:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
使用函数重载虽然可以实现,但是有一下几个不好的地方:
- 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函
数 - 代码的可维护性比较低,一个出错可能所有的重载均出错
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?
如果在C++中,也能够存在这样一个模具,通过给这个模具中填充不同材料(类型),来获得不同材料的铸件(即生成具体类型的代码),那将会节省许多头发。巧的是前人早已将树栽好,我们只需在此乘凉。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
这就是我们所说的模板:
模板分为两类,一类是函数模板,另一类则是类模板
函数模板
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
针对于上面的swap函数,函数模板格式如下:
template和typename均为关键字,
template<typename T>
void Swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
注意:
typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
其实啊,函数模板他并不是一个模板!
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器
而在调用函数时就是函数模板实例化了:
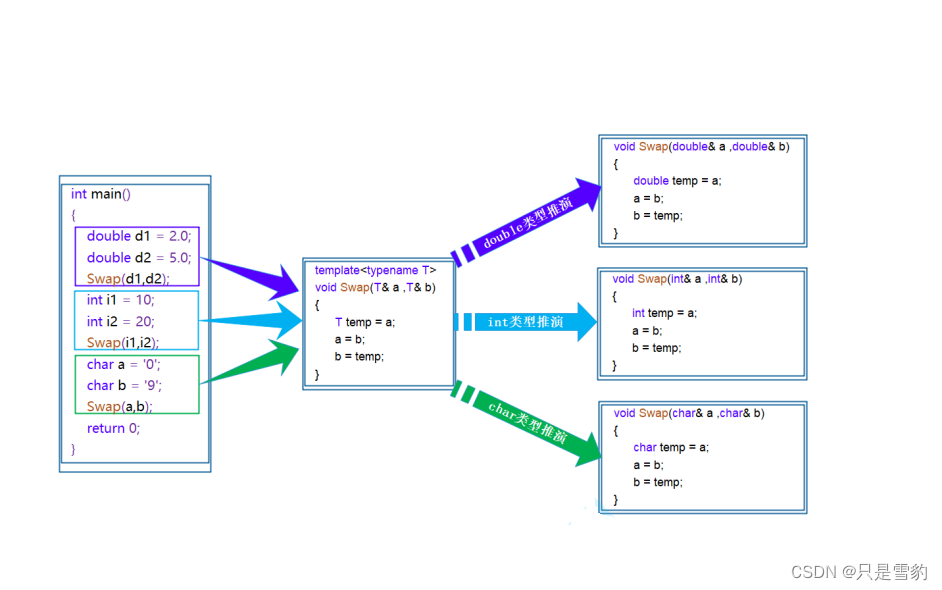
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。
也就是说编译器自行判断类型使用!
比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
函数模板的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。
模板参数实例化分为:隐式实例化和显式实例化。
- 隐式实例化:让编译器根据实参推演模板参数的实际类型
请看这段代码:
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,编译器无法确定此处到底该将T确定为int 或者 double类型而报错
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
return 0;
}
正确的应该这样:
将类型强制转换
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a, (int)d);
return 0;
}
同时我们也可以选择显式实例化:
- 显式实例化:在函数名后的<>中指定模板参数的实际类型
int main(void)
{
int a = 10;
double b = 20.0;
// 显式实例化
Add<int>(a, b);
return 0;
}
模板参数的匹配原则
- 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数这样就可以节省一点时间
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}
- 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}
- 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
类模板
类模板的格式如下:
template<class T1, class T2, ..., class Tn>
class 类模板名
{
// 类内成员定义
};
简单地讲一下类模板的实例化吧:
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类
例如:
//Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
// Vector类名,Vector<int> s1才是类
Vector<int> s1;
Vector<double> s2
好了,今天的分享到这里就结束了,谢谢大家的支持!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!