MatrixOne 1.1.0 Release

我们非常高兴地宣布:
MatrixOne内核1.1.0版本
正式发布啦!
项目文档网站

MatrixOne是一款分布式超融合异构数据库,MatrixOne旨在提供一个云原生、高性能、高弹性、高度兼容MySQL的HSTAP数据库,让用户面对事务、分析、时序、流计算等混合负载时,通过MatrixOne一站式的完成整个数据处理过程。
重点关注 MatrixOne 1.1.0
MatrixOne在本迭代增加了多个重要功能,在整体HTAP的基础上增强了向量,流和时序方面的能力,进一步丰富了能力象限和适用范围。
向量数据类型
做为2023年AI与大模型热潮的数据基座能力,向量类型已经成为通用数据库的标配。本迭代MatrixOne支持了vecf32及vecf64的向量类型,分别对应float32和float64数据类型,同时支持了基本的算子和操作符,以及向量常见的求和,L1范数,L2范数,内积,余弦相似度等计算函数。用户使用的时候配合AI算法模型可以快速搭建一个AI应用。比如基于大语言模型LLM的RAG应用,如下图所示,用户仅需将自己的知识库调用OpenAI的Embedding接口生成向量数据存入MatrixOne中,再通过余弦相似度函数计算搜索最相似答案,再将答案通过OpenAI的Prompt接口交给LLM优化回答即可。
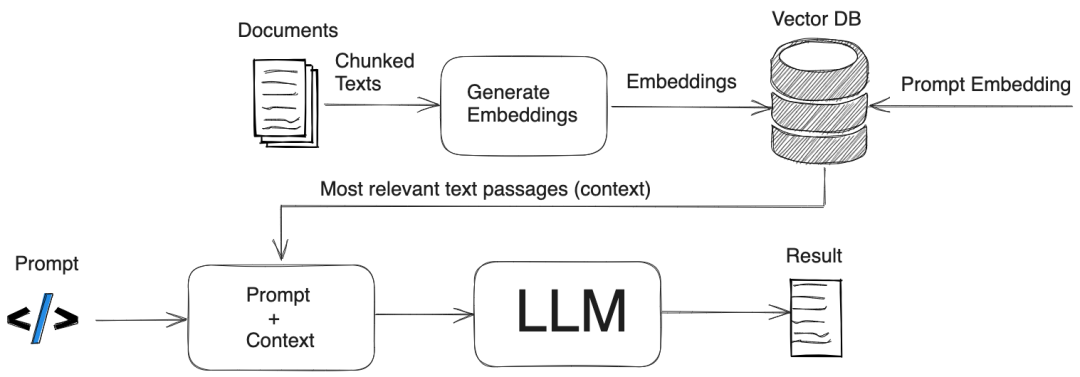
与专用的向量数据库不同的是,MatrixOne是一个高度兼容MySQL的通用数据库,用户几乎不需要额外的学习门槛即可快速上手,同时在构建AI应用的时候也可以将结构化数据与向量数据的处理合二为一。
时序能力
为了更好的处理数据快速流入的各类IoT场景,本迭代MatrixOne在时序方案的能力也大幅加强,具体体现在以下几点:
- 比INSERT INTO性能大幅提升的流式写入能力LOAD INTO INLINE。
- 支持建立按时间戳作为主键的专用时序表,并支持任意的维度/指标列。
- 增加在时序表上的滑动窗口能力,可以按不同的时间进行降采样查询。
- 支持针对空值的插值能力,并提供不同策略的插值方法。
Kafka Connector(beta)
本迭代在基础流计算的框架基础上实现了Kafka connector。用户可以通过CREATE DYNAMIC TABLE创建流式动态表,此类型的表是Append Only的表,同时用户可以通过CREATE SOURCE的方式配置外部数据源,本迭代已适配Kafka作为数据源,可以接入Kafka的Topic(JSON类型或者protobuf协议类型),接入后MatrixOne会自动将Kafka的Message写入到动态表中,用户可以对流式表进行窗口查询,或者与其他表一起进行关联查询。
自定义函数 UDF(beta)
本迭代MatrixOne开始支持用户编写自定义函数,目前第一个版本仅支持Python语言。在很多场景中数据库系统提供的系统函数并无法满足用户的业务需求,通过UDF的方式用户可以将业务的逻辑包装在Python文件中,并将其封装成SQL的函数,实现在SQL中直接调用。基于Python的UDF,用户可以非常方便的使用numpy和scikit-learn等Python的流行库,大幅度的提高MatrixOne在数据科学,机器学习及AI等领域的适用性。
其他新功能
1 DDL
- 支持insert on duplicate key ignore
- 支持create or replace view
- 支持alter sequence
- 支持Key, hash的分区裁剪能力 (beta)
- 支持List/List column, Range/Range Columns partition分区存储能力(beta)
2 索引与约束
- 完整实现次级索引secondary index,可实现动态查询加速
3 函数
- 自定义函数UDF:支持用户创建Python语言的自定义函数UDF (beta)
- 增加SAMPLE采样函数
- 增加CONVERT_TZ转换时区函数
- 增加SHA2加密函数
- 增加Encode/Decode编解码函数
4 安全与权限
- 支持通过创建Stage对select into的路径权限进行管理
5 周边工具
modump工具(逻辑备份)
- 新增支持单独导出DDL语句
- 支持导出多个数据库、多个表
mo_backup工具?
- 支持物理备份
- 支持文件系统、对象存储作为备份和还原的存储介质
mo_ctl(单机)工具?
- 支持自动数据备份
- 支持自动日志表数据清理
- 支持数据文件从csv格式转换为insert或load data inline格式
- 支持docker镜像自动构建
- 支持docker模式
单机部署mo_ctl(分布式)工具?
- 支持install一键部署分布式集群
- 支持destroy一键销毁分布式集群
mo_ctl 分布式部署运维工具?
- 支持install一键部署分布式集群
- 支持destroy一键销毁分布式集群
- 支持matrixone集群的起动/停止,升级/回滚操作
- 支持在客户k8s集群中安装matrixone集群
mo_operator工具?
- 支持配置自定义的S3证书
- 支持通过 API 进行 matrixone 集群的备份恢复和备份数据管理
- 支持自动为 matrixone 集群设置更优化的 Go GC 策略
- 支持为 matrixone 集群启用 Python UDF
- 支持 Kubernetes 上的 matrixone 与 Prometheus 集成
MySQL兼容性
- 大幅减少与MySQL不兼容的保留关键字
Known Issues
- 次级索引对于IN类型的查询没有加速作用
- Kafka连接器仅在单机版本中运行
- 高并发负载下偶现系统会卡住
- 大数据量查询偶现内存溢出OOM问题
文档更新
- 新增时序整体能力描述
- 新增流式导入, 时序表,滑动窗口相关文档
- 新增向量类型及函数文档
- 新增流计算相关文档
- 新增partition实现及加速相关文档
- 新增SQL语句,系统函数的参考手册
- 更新整体功能列表
- 更新MySQL兼容性列表
了解更多详情,您可以访问我们的文档网站(https://docs.matrixorigin.cn)。您可以在该网站找到详细的架构说明、安装指南和开发教程,帮助您探索MatrixOne的能力。此外,我们的Github网站也可以用于提问、讨论或反馈。
MatrixOrigin 官网:新一代超融合异构开源数据库-矩阵起源(深圳)信息科技有限公司 MatrixOne
Github 仓库:GitHub - matrixorigin/matrixone: Hyperconverged cloud-edge native database
关键词:超融合数据库、多模数据库、云原生数据库、国产数据库。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux最常用的几个系统管理命令
- 微电网优化MATLAB:火鹰优化算法(Fire Hawk Optimizer,FHO)求解微电网优化(提供MATLAB代码)
- SpringCloud 之HttpClient、HttpURLConnection、OkHttpClient切换源码
- linux第五章(系统维护)
- CompletableFuture的thenCombine结果组合用法实例
- 8个创新性的对外贸易新闻媒体发稿营销推广策略,助推企业出航出海
- 在不确定的时代,程序员如何更好的经营家庭
- 【OSG案例详细分析与讲解】之一:【参数分析】
- 【Python】练习题
- 20-多线程