MATLAB聚类工具箱
本文借鉴了数学建模清风老师的课件与思路,可以点击查看链接查看清风老师视频讲解:【1】MATLAB聚类工具箱:提前预览工具箱的核心功能_哔哩哔哩_bilibili
关于工具箱的获取,在数学建模学习交流公众号里发送:?567891
%% 本工具箱对MATLAB的要求:
% (1)MATLAB版本为2021a及以上版本
% (2)只支持windows系统,不支持苹果电脑的MAC系统
% (3)MATLAB APP中有统计和机器学习工具箱(Statistics and Machine Learning Toolbox)
%% 使用下面的代码加载Kmeans工具箱(精简版,无使用期限)
% 不要在压缩包中直接打开文件,先解压后再打开,MATLAB的当前文件夹也记得更改
%【Matlab新手经常遇到的一些问题】 https://b23.tv/EopJrWI
P_mainfunction_KmeansCluster_Simple_Version
%% (1)示例1:鸢尾花数据集
% 工具箱中附带了鸢尾花的数据集,这是MATLAB内置的数据集
% 你可以看到在MATLAB的工作区有一个名为meas的矩阵(大小是150*4)
% 这表示数据集中有150个样本,4个指标:
% 花萼长 花萼宽 花瓣长 花瓣宽(单位都是cm)
meas= [5.1 3.5 1.4 0.2;4.9 3 1.4 0.2;4.7 3.2 1.3 0.2;4.6 3.1 1.5 0.2;5 3.6 1.4 0.2;5.4 3.9 1.7 0.4;4.6 3.4 1.4 0.3;5 3.4 1.5 0.2;4.4 2.9 1.4 0.2;4.9 3.1 1.5 0.1;5.4 3.7 1.5 0.2;4.8 3.4 1.6 0.2;4.8 3 1.4 0.1;4.3 3 1.1 0.1;5.8 4 1.2 0.2;5.7 4.4 1.5 0.4;5.4 3.9 1.3 0.4;5.1 3.5 1.4 0.3;5.7 3.8 1.7 0.3;5.1 3.8 1.5 0.3;5.4 3.4 1.7 0.2;5.1 3.7 1.5 0.4;4.6 3.6 1 0.2;5.1 3.3 1.7 0.5;4.8 3.4 1.9 0.2;5 3 1.6 0.2;5 3.4 1.6 0.4;5.2 3.5 1.5 0.2;5.2 3.4 1.4 0.2;4.7 3.2 1.6 0.2;4.8 3.1 1.6 0.2;5.4 3.4 1.5 0.4;5.2 4.1 1.5 0.1;5.5 4.2 1.4 0.2;4.9 3.1 1.5 0.2;5 3.2 1.2 0.2;5.5 3.5 1.3 0.2;4.9 3.6 1.4 0.1;4.4 3 1.3 0.2;5.1 3.4 1.5 0.2;5 3.5 1.3 0.3;4.5 2.3 1.3 0.3;4.4 3.2 1.3 0.2;5 3.5 1.6 0.6;5.1 3.8 1.9 0.4;4.8 3 1.4 0.3;5.1 3.8 1.6 0.2;4.6 3.2 1.4 0.2;5.3 3.7 1.5 0.2;5 3.3 1.4 0.2;7 3.2 4.7 1.4;6.4 3.2 4.5 1.5;6.9 3.1 4.9 1.5;5.5 2.3 4 1.3;6.5 2.8 4.6 1.5;5.7 2.8 4.5 1.3;6.3 3.3 4.7 1.6;4.9 2.4 3.3 1;6.6 2.9 4.6 1.3;5.2 2.7 3.9 1.4;5 2 3.5 1;5.9 3 4.2 1.5;6 2.2 4 1;6.1 2.9 4.7 1.4;5.6 2.9 3.6 1.3;6.7 3.1 4.4 1.4;5.6 3 4.5 1.5;5.8 2.7 4.1 1;6.2 2.2 4.5 1.5;5.6 2.5 3.9 1.1;5.9 3.2 4.8 1.8;6.1 2.8 4 1.3;6.3 2.5 4.9 1.5;6.1 2.8 4.7 1.2;6.4 2.9 4.3 1.3;6.6 3 4.4 1.4;6.8 2.8 4.8 1.4;6.7 3 5 1.7;6 2.9 4.5 1.5;5.7 2.6 3.5 1;5.5 2.4 3.8 1.1;5.5 2.4 3.7 1;5.8 2.7 3.9 1.2;6 2.7 5.1 1.6;5.4 3 4.5 1.5;6 3.4 4.5 1.6;6.7 3.1 4.7 1.5;6.3 2.3 4.4 1.3;5.6 3 4.1 1.3;5.5 2.5 4 1.3;5.5 2.6 4.4 1.2;6.1 3 4.6 1.4;5.8 2.6 4 1.2;5 2.3 3.3 1;5.6 2.7 4.2 1.3;5.7 3 4.2 1.2;5.7 2.9 4.2 1.3;6.2 2.9 4.3 1.3;5.1 2.5 3 1.1;5.7 2.8 4.1 1.3;6.3 3.3 6 2.5;5.8 2.7 5.1 1.9;7.1 3 5.9 2.1;6.3 2.9 5.6 1.8;6.5 3 5.8 2.2;7.6 3 6.6 2.1;4.9 2.5 4.5 1.7;7.3 2.9 6.3 1.8;6.7 2.5 5.8 1.8;7.2 3.6 6.1 2.5;6.5 3.2 5.1 2;6.4 2.7 5.3 1.9;6.8 3 5.5 2.1;5.7 2.5 5 2;5.8 2.8 5.1 2.4;6.4 3.2 5.3 2.3;6.5 3 5.5 1.8;7.7 3.8 6.7 2.2;7.7 2.6 6.9 2.3;6 2.2 5 1.5;6.9 3.2 5.7 2.3;5.6 2.8 4.9 2;7.7 2.8 6.7 2;6.3 2.7 4.9 1.8;6.7 3.3 5.7 2.1;7.2 3.2 6 1.8;6.2 2.8 4.8 1.8;6.1 3 4.9 1.8;6.4 2.8 5.6 2.1;7.2 3 5.8 1.6;7.4 2.8 6.1 1.9;7.9 3.8 6.4 2;6.4 2.8 5.6 2.2;6.3 2.8 5.1 1.5;6.1 2.6 5.6 1.4;7.7 3 6.1 2.3;6.3 3.4 5.6 2.4;6.4 3.1 5.5 1.8;6 3 4.8 1.8;6.9 3.1 5.4 2.1;6.7 3.1 5.6 2.4;6.9 3.1 5.1 2.3;5.8 2.7 5.1 1.9;6.8 3.2 5.9 2.3;6.7 3.3 5.7 2.5;6.7 3 5.2 2.3;6.3 2.5 5 1.9;6.5 3 5.2 2;6.2 3.4 5.4 2.3;5.9 3 5.1 1.8];
%% (2)森林、草原资源数据集
% 有21个国家的数据,每个国家3项指标
% 森林覆盖率(%) 林木蓄积量(亿立方米) 草原面积(万公顷)
load data_forest.mat
%% (3)1999年全国31个省份城镇居民家庭平均每人全年消费性支出数据
% 数据来源:嵩天Python机器学习算法课程案例
% 31个样本、8个指标
% 食品 衣着 家庭设备 医疗 交通 娱乐 居住 杂项
load data_expenditure.mat
% 本工具箱系列由清风老师和出版社合作开发,还未正式发布,目前相关合作还在洽谈阶段,仅给大家测试使用。
% 使用者不得进行任何商用行为,以免未来有版权纠纷。
% 因作者水平有限,本工具箱得到的结果不一定完全正确,请大家自行核对结果的正确性。
一、加载数据、去量纲以及缺失值
打开工具箱,运行:
P_mainfunction_KmeansCluster_Simple_Version
点击左上角“点我加载”会工作区里所有的二维数据加载到工具箱里;然后选择需要聚类的变量,点击点此确定,就会将这个变量里的所有指标导入进来,接着会提示是否需要去除量纲,根据自己需求选择即可,在左下角有两种去量纲的方法,如下图:

自己随便选择一种即可,选择了之后点击“点此确定”即可成功去除量纲,
去除量纲之后的变量会自动生成在工作区中,新的变量名叫:原变量名_qclg。
当数据中有缺失值时,会提示有缺失值,此时需要自己填补缺失值,填补的方法:缺失值和异常值的处理
点击指标名字可以修改指标名,也可批量修改。
二、聚类参数的设置、聚类结果的含义

簇的个数:可以手动设置,也可以自动寻找最优。当为自动寻优时,是通过寻找轮廓系数(越大越好)、间隔统计量等等这些评价指标最优时候的K值。这些评价指标详细过程可参考旁边的参考文档。也可以绘制肘部图来看,在哪里变化幅度开始减小时,K值就是谁。
计算距离的公式:一般时平方欧几里得聚类。
聚类中心的初始化方法:推荐K_Means++算法。
单次聚类允许的最大迭代数:一般不会超过1000。
使用不用的初始聚类中心重复聚类的次数:设置成几次,就会聚几次,然后将最好的结果返回,电脑性能好的话,可以设置的大一点。
固定随机数种子:设置随机数种子,可以将结果固定下来。因为每次都是随机的,不固定住的,结果可能会不一样。
点击开始聚类,即可生成聚类结果。
注:没完成一个操作,在任务栏就会生成这次操作的代码,运行这部分代码和操作工具箱得到的结果是一样的。
三、计算统计量解释聚类结果
 自行选择数据源,然后点击“计算不同簇的统计量”,可以从数据特征中找到这3类的特点。
自行选择数据源,然后点击“计算不同簇的统计量”,可以从数据特征中找到这3类的特点。

比如,第一类的特点就是花萼长和花瓣长最小,花萼宽最大;第二类特点花萼长最大和花瓣长最大。
四、二维和三维散点图

得到的散点图更加直观。
聚类中心的位置就是每一个簇的中心位置
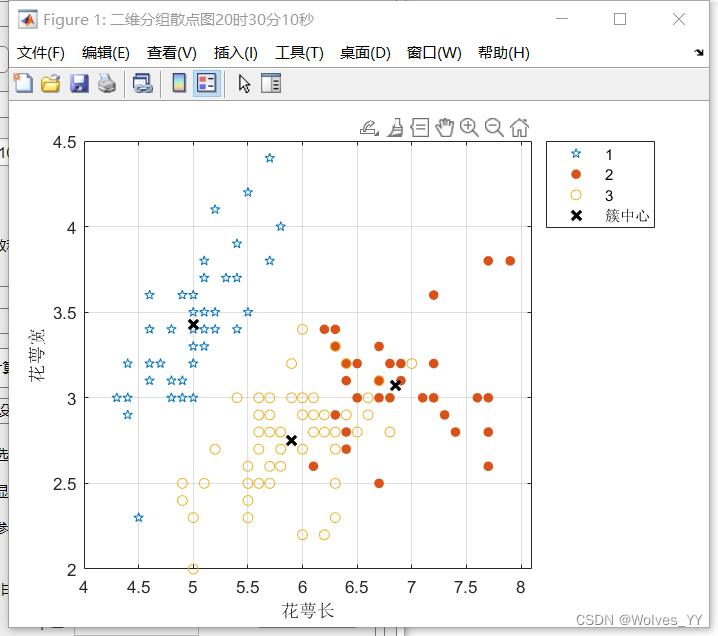
?上面这个图第一类和第二类,一个靠近y州上面,一个靠近x轴右边,说明这俩类一个花萼宽更大,一个花萼长更大,第二类则位于中间。
鉴于后面的绘图都需要完整版,目前完整版又用不起,就没看后面的视频了。
五、区域图
六、平行坐标图
七、箱线图
八、主成分分析图
九、分组散点图矩阵
十、对聚类结果假设检验
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于STM32单片机直流电压电流检测仪表系统ACD712芯片毕业设计4
- C++力扣题目40--组合总和II
- UDP网络编程
- 【常见问题】在Tkinter中使用Listbox.curselection()获取列表索引,为什么第一次返回为空元组
- FastAPI 并发请求详解:提升性能的关键特性
- 区间合并(pair,auto的用法)
- 【Proteus仿真】【51单片机】光照强度检测系统
- 使用Python检测并删除离群值
- ant-design-vue的table组件的自定义表头和表格内容
- 改变this指向的三种方式