大模型微调实战笔记
大模型三要素
1.算法:模型结构,训练方法
2.数据:数据和模型效果之间的关系,token分词方法
3.算力:英伟达GPU,模型量化
基于大模型对话的系统架构
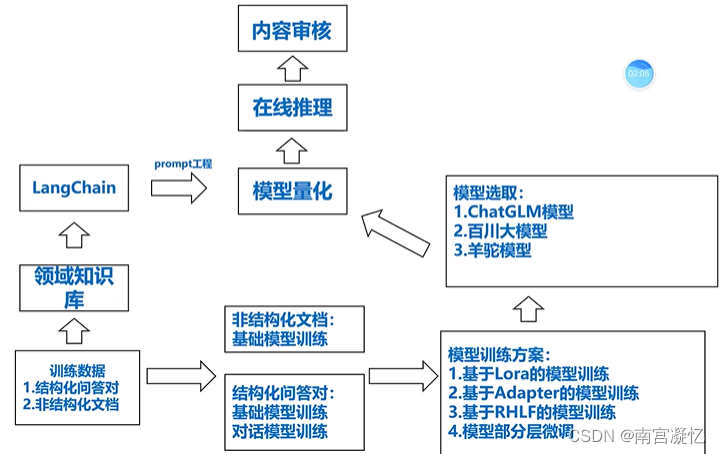
基于Lora的模型训练最好用,成本低好上手
提示学习:提示工程的支撑
写提示词,让模型完成各种任务。
使用提示(Prompt)工程来提高 LLMs 在各种常见和复杂任务(如问答和算术推理)上的能力。
优点:简单,易上手
缺点:上限有限,模型适配;投资人嫌薄;技术人嫌浅


基础prompt提示

高级prompt提示




大模型的内核:Transformer
主流大模型基于Transformer在这四个地方进行排列组合:
结构、位置编码、激活函数、layer norm
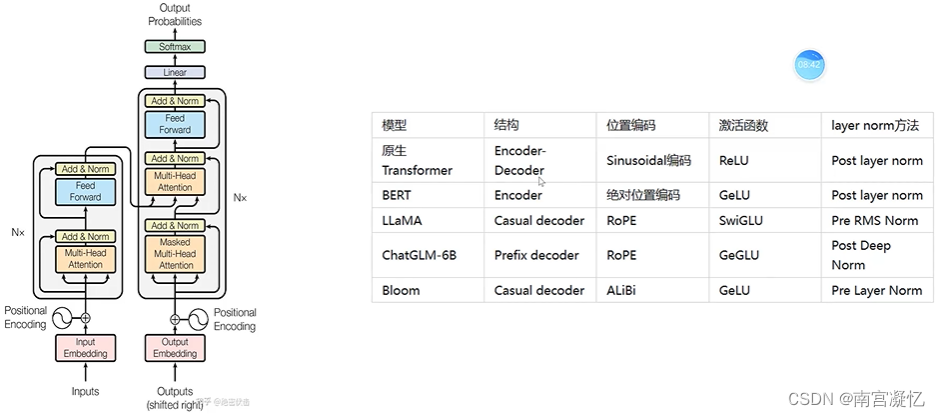
大模型的架构
Encoder-Decoder架构用的少了,因为要达到同样的效果,参数量翻倍。
主要是第二种和第三种在竞争。

为什么大模型很少直接微调?
1.参数多,内存不容易放下。
2.参数多,需要对应更大数据。
3.参数多,不容易收敛。
4.参数多,调参时间过长。
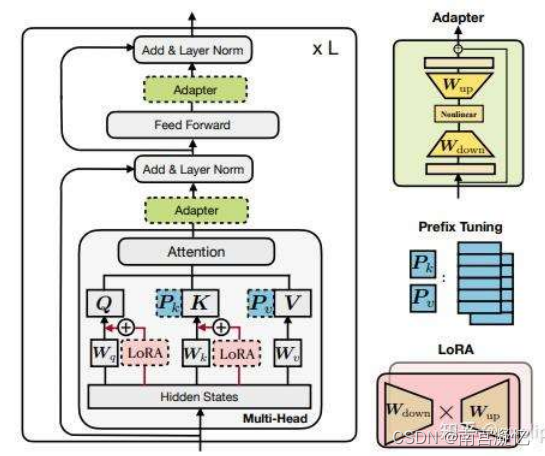
参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)
Prefix-Tuning / Prompt-Tuning:在模型的输入或隐层添加 k 个额外可训练的 前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练 这些前缀参数;提示词不是单词了,而是向量,直接去调向量。
Adapter-Tuning:将较小的神经网络层或模块插入预训练模型的每一层,这 些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这 些适配器参数;在Transformer结果中加了Pk和Pv两个外挂,只学这两个小外挂,需要学习的参数变得很少。
LoRA:通过学习小参数的低秩矩阵来近似模型权重矩阵 W的参数更新,训 练时只优化低秩矩阵参数。Adapter-Tuning是以串联的形式加外挂,LoRA是以并联的形式加外挂。(效果好易上手收敛快)
大数据类型
数据的分类:
? 网页数据(web data):量大。
? 专有数据(curated high-quality corpora):质高。
模型需要数据:
基座模型:GLM,GPT具备语言理解能力,但是不具备对话能力
使用数据:非结构化纯文本数据
对话模型:
ChatGLM,ChatGPT在基座模型的基础上,进行对话的专项训练
使用数据:结构化QA数据
PALM大模型数据来源

BLOOM大模型数据语言
常用数据集
常见英文数据集

常见中文数据集

幂律
Scaling Laws简单介绍就是:随着模型大小、数据集大小和训练强度,模型的性能 会提高。并且为了获得最佳性能,所有三个因素必须同时放大。当不受其他两个因 素的制约时,模型性能与每个单独的因素都有幂律关系

参数量和数据量之间的关系
当同时增加数据量和模型参数量时,模型表现会一直变好。当其中一个因素受限时,模型表现随另外一个因素增加变好,但是会逐渐衰减。
Test Loss:测试集损失函数越小说明模型效果越好。

数据、算力、参数量之间的关系

大模型的分词(token)
分词粒度:
1.单词分词法:英文(空格分词),中文(jieba分词 or 分字)。
2.单字分词法:英文(字母),中文(分字)。
3.子词分词法:BPE,WordPiece,Unigram。(大模型常用)
成对出现的当成一个子词,比如:葡和萄
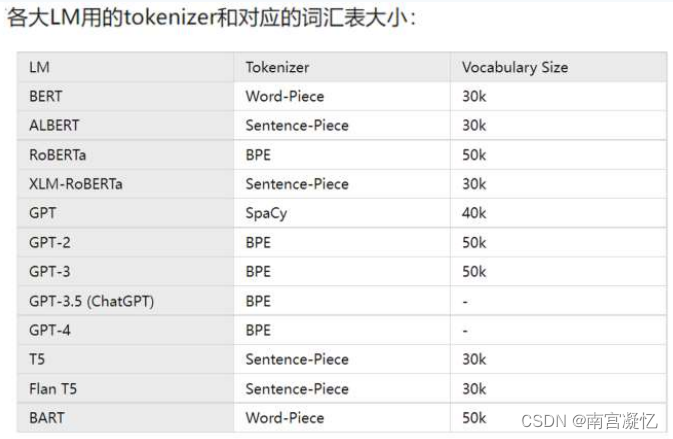
常见大模型的词表
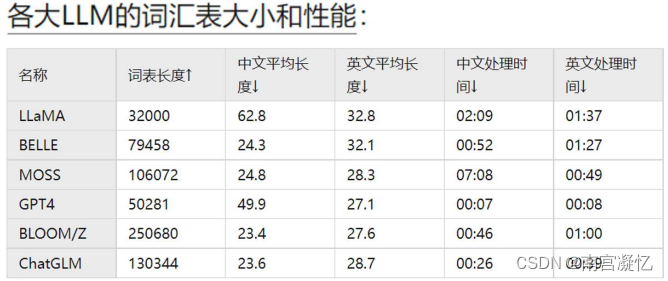
算法并行

模型压缩和加速
深度学习领域提出了一系列的模型压缩与加速方法:
?剪枝(Parameter pruning)
?低秩分解(Low-rank factorization)
?知识蒸馏(Knowledge distillation)
?量化(quantization):大模型时代常用
数据量化
用低精度数表示高精度数,整数表示浮点数。
精度损失对推理影响不大,对训练有影响。

量化的常见三种方法
方式一:对训好的模型进行量化,只量化权重,不能量化激活函数输出的值。
方式二:跑测试数据,能量化激活函数输出的值。
方式三:训练模型时直接量化,将量化嵌入到学习中。成本高,效果好。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AG16KDDF256 User Manual
- Maven配置多仓库
- 文华期货软件macd RSI 金叉信号多周期共振指标公式源码
- 记二开金蝶云星空动态表单艰辛历程
- 寄快递选哪个平台便宜?快递优惠券免费领取!
- 基于SpringBoot的校BA篮球网站--29210(免费领源码+数据库)可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案
- c语言作业
- 自动化网络故障管理
- MySQL之、CRUD、函数及union查询(实施必会)
- 【WSL2】在Windows和wsl2中互相网络访问的优雅做法,不用再手动写死IP了