python爬虫实例3(使用selenium自动化完成猫眼电影数据爬取)
一.爬虫前的准备工作
首先我们要下载本次爬虫所用到的最重要的python第三方模块——selenium,下面为大家简单介绍一下此模块的用途
1.?什么是selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
2.selenium功能
1、框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
2、使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
3、使用简单,可使用Java,Python等多种语言编写用例脚本。
3 selenium的特点
1、可根据指令操控浏览器
2、只是工具,必须与第三方浏览器结合使用
4.selenium安装与环境配置
pip install selenium==3.0.2? ? ?(建议不要更改版本)
注意:需要下载谷歌驱动包与selenium一起使用,驱动包的版本要接近自己电脑谷歌浏览器的版本就行,下载完驱动包之后解压放在python版本号/Scripts文件夹下就行
5、Selenium常用函数
1.浏览器对象

2.定位节点
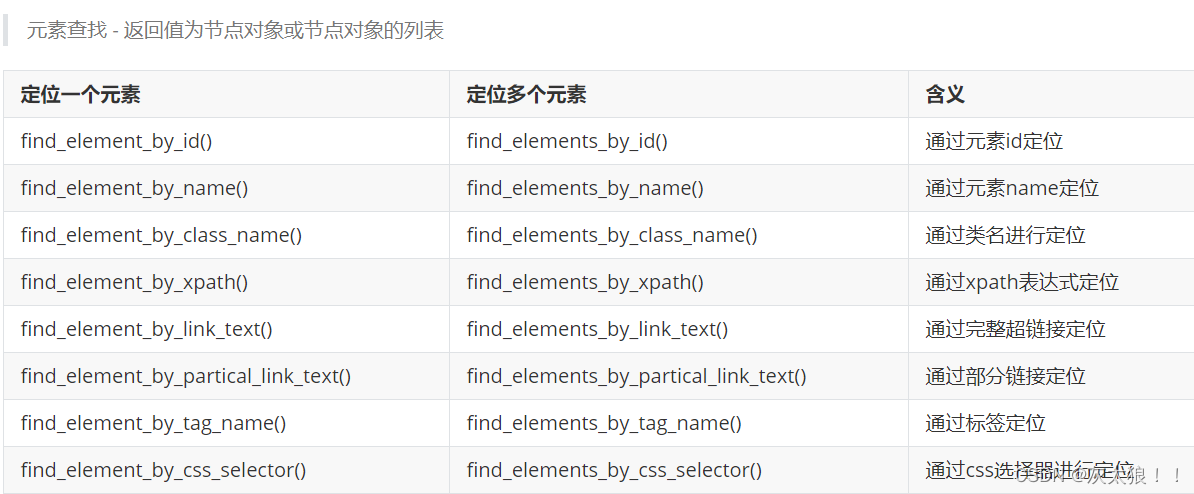
3 节点对象方法

二.开始爬虫
我们以猫眼top100榜数据的爬取为例(https://www.maoyan.com/board/4)
此次爬取我们还用到了python中的time库以及pandas库,其中time中的sleep方法使爬取数据更加完整,pandas库可以将爬取来的数据封装成DataFrame类型写入文件中,下面进行代码展示
?
import time
from selenium import webdriver
import pandas as pd
# 爬取一页数据
def get_one_data(drive, rank_list, name_list, actor_list, time_list, score_list):
time.sleep(1) # 给页面加载时间防止爬取不完全
# //div[@id="app"]/div/div/div[1]/dl/dd
dd_list = drive.find_elements_by_xpath('//div[@id="app"]/div/div/div[1]/dl/dd')
# print(dd_list, type(dd_list))
for dd in dd_list:
infos = str(dd.text).split('\n')
print(infos)
rank_list.append(infos[0])
name_list.append(infos[1])
actor_list.append(infos[2])
time_list.append(infos[3])
score_list.append(infos[4])
#
def quit_drive(drive):
time.sleep(5)
drive.quit()
if __name__ == '__main__':
drive = webdriver.Chrome()
drive.get('https://www.maoyan.com/board/4')
time.sleep(5) # 留时间给用户操作,一般指验证,登录之类
# ['1', '我不是药神', '主演:徐峥,周一围,王传君', '上映时间:2018-07-05', '9.6']
rank_list = [] # 序号
name_list = [] # 电影名称
actor_list = [] # 主演
time_list = [] # 上映时间
score_list = [] # 评分
# 爬取第一页数据
page_num = 1
print(f'-------------------------正在爬取第{page_num}页数据------------------------------')
get_one_data(drive, rank_list, name_list, actor_list, time_list, score_list)
while True:
li = drive.find_element_by_xpath('//div[@id="app"]/div/div/div[2]/ul/li[last()]')
if str(li.text) == '下一页':
li.click()
page_num += 1
print(f'-------------------------正在爬取第{page_num}页数据------------------------------')
get_one_data(drive, rank_list, name_list, actor_list, time_list, score_list)
else:
print('爬取完毕')
break
quit_drive(drive)
#将爬取来的数据封装成DataFrame类型写入文件中
dict1 = {
'序号': rank_list,
'电影名称': name_list,
'主演': actor_list,
'上映时间': time_list,
'评分': score_list
}
df1 = pd.DataFrame(dict1)
df1.to_csv('data/猫眼TOP100榜单第一页数据.csv', index=False)
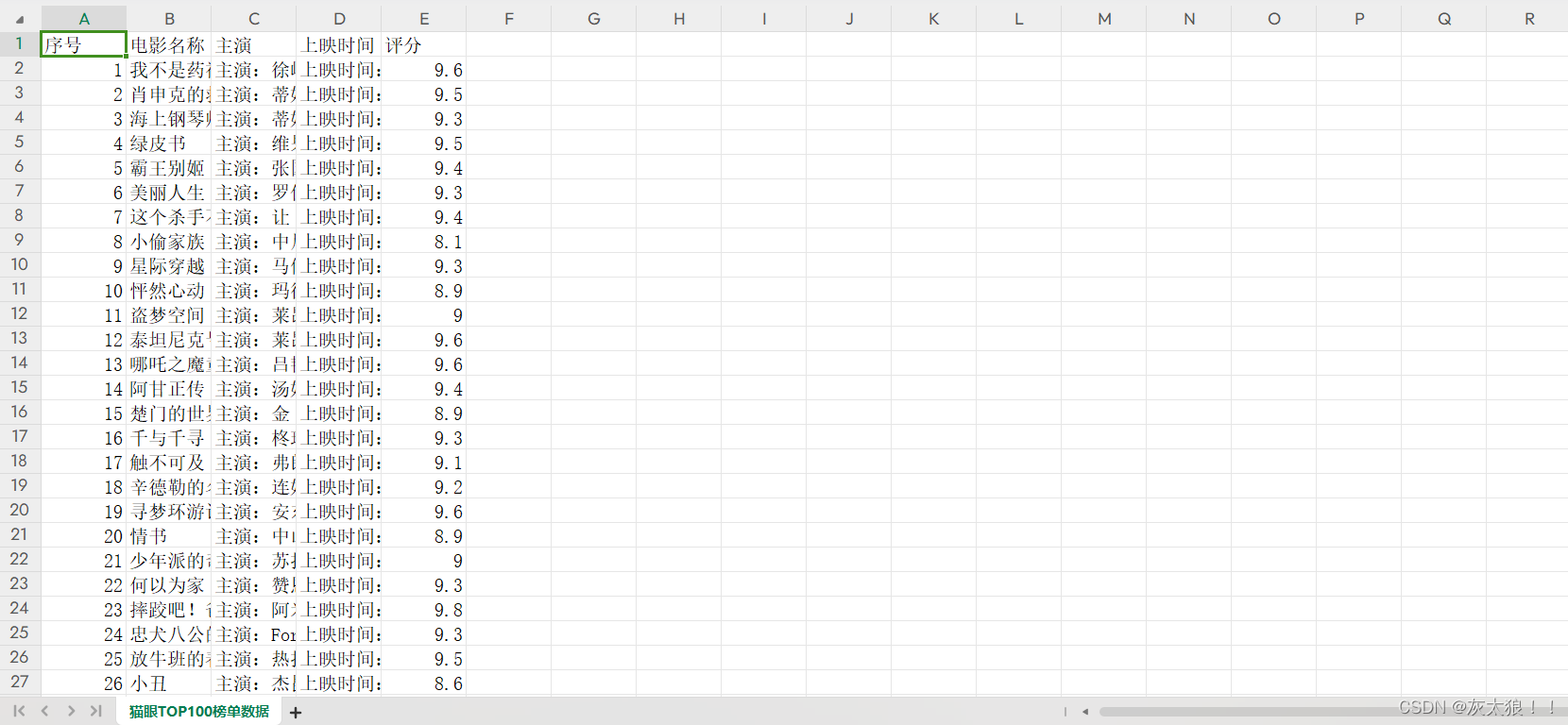
?成品展示:
关于代码中的Xpath语法,我会在爬虫常用实例专栏中的爬虫实例2中详细说明
由于作者的水平有限,若是文中有错还请诸位大佬不吝指教!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深圳市DDOS防护ddos高防ip大流量攻击防护教育行业DDoS防御解决方案
- Live800:客户体验策略是什么?企业如何制定客户体验策略?
- java静态代理动态代理理解和例子解析包含demo
- PHP数组定义和输出
- 2024.1.2hbase考试
- 更适合3D项目的UI、事件交互!纯国产数字孪生引擎持续升级中!!!
- git基础命令(小白适合看)
- 2024年华为OD机试真题-素数之积-Python-OD统一考试(C卷)
- 基于PHP的视频素材网
- macOS系统ISO镜像完整制作过程