【部署LLaMa到自己的Linux服务器】
发布时间:2024年01月16日
部署LLaMa到自己的Linux服务器
1、Llama2 项目获取
方法1:有git可以直接克隆到本地
创建一个空文件夹然后鼠标右键,然后输入git clone https://github.com/facebookresearch/llama.git

方法2:直接下载
打开网站LLaMa git 官方,直接下载zip文件就行

2、LLama2 项目部署
这里在conda中创建一个虚拟环境conda create -n 环境名字 python=x.x
创建成功之后使用cd命令或者直接在LLaMa文件夹右键打开终端,输入
# 常规安装命令
pip install -e .
# 国内环境可以使用清华源加速
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
这一步目的是安装LLama2运行所需要的依赖
3、申请Llama2许可
要想使用Llama2,首先需要向meta公司申请使用许可,否则你将无法下载到Llama2的模型权重。填入对应信息(主要是邮箱)后,勾选页面最底部的 “I accept the terms and conditions”,点击 “Accept and Continue”,跳转到下图界面即可。
申请网站需要科学上网:Request access to the next version of Llama
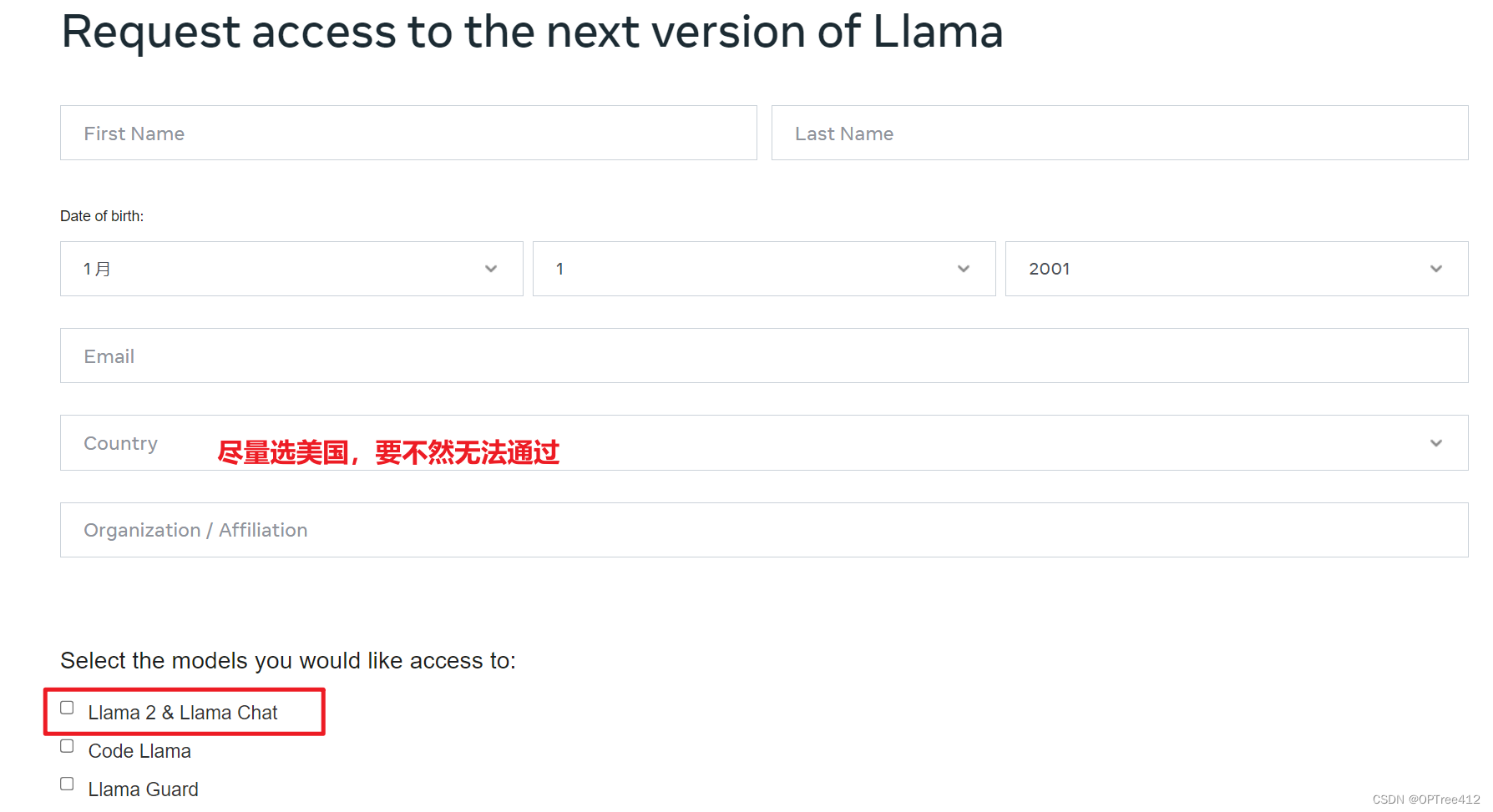
然后对应的邮箱得到验证的链接,这个https://download.llamameta.net/*? 开头的一大串链接即为下面下载模型时需要验证的内容。
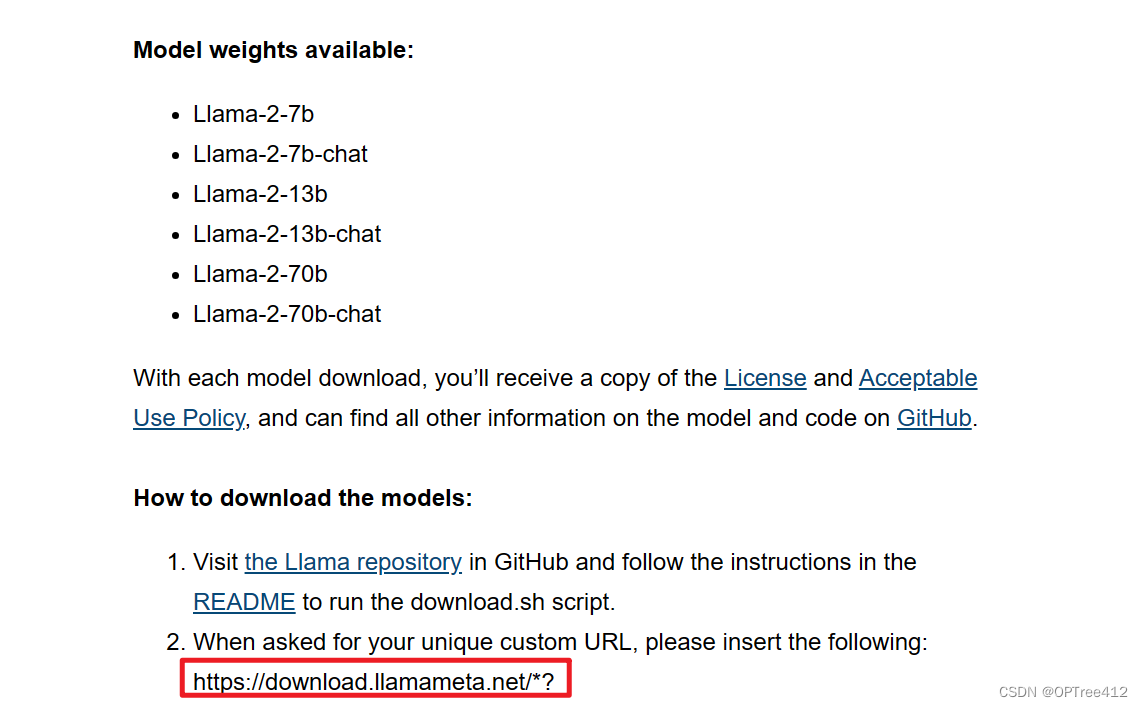
4、下载模型权重
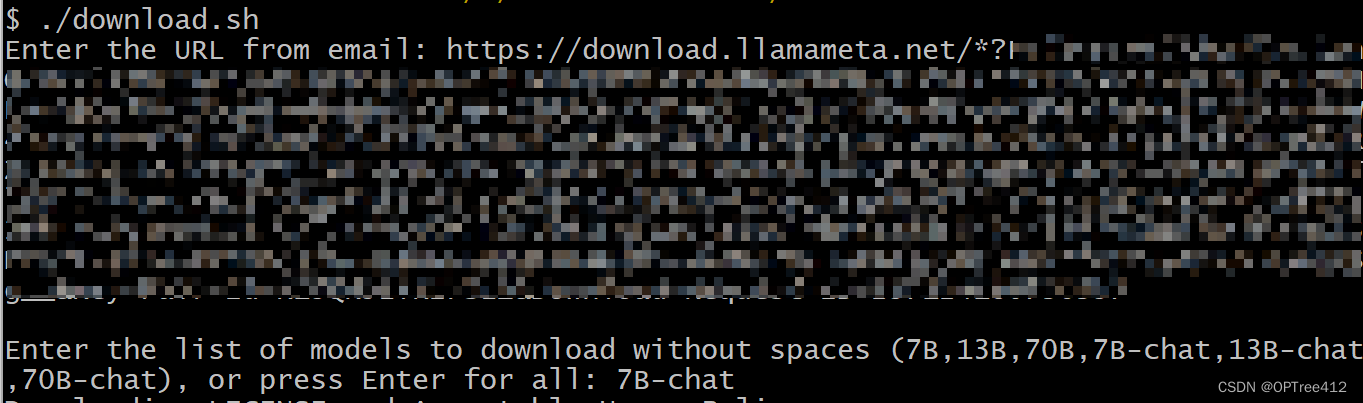
在LLaMa文件夹中打开终端,运行download.sh文件。./download.sh
第一个输入邮件中给你的超长链接,第二个输入你需要的模型。
我是选择7B和7B-chat
5、运行
下载完成之后,就可以使用啦
# 句子补全
torchrun --nproc_per_node 1 example_text_completion.py \ --ckpt_dir llama-2-7b/ \ --tokenizer_path tokenizer.model \ --max_seq_len 128 --max_batch_size 4
# 对话生成
torchrun --nproc_per_node 1 example_chat_completion.py \ --ckpt_dir llama-2-7b-chat/ \ --tokenizer_path tokenizer.model \ --max_seq_len 512 --max_batch_size 4
命令的含义是
torchrun是一个PyTorch提供的用于分布式训练的命令行工具--nproc_per_node 1这个选项指定在每个节点上使用1个GPU。意味着每个训练节点(可能是单个GPU或多个GPU)只使用一个GPU--ckpt_dir llama-2-7b/和--tokenizer_path tokenizer.model主要指定使用的模型和tokenizer的路径。这个可以在对应.py文件中写死入参避免重复指定。
文章来源:https://blog.csdn.net/CSTGYinZong/article/details/135626846
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 运动的解析:从机械运动到自由落体,探索物体运动的基本规律与数学描述
- 前端开发工程师面试总结
- 【软件测试】- 面试题之计算机网络篇2
- 数组模拟队列java
- 响应式Web开发项目教程(HTML5+CSS3+Bootstrap)第2版 例4-9 HTML5 表单验证
- iphone 5s的充电时序原理图纸,iPAD充电讲解
- 常见的 HTTP 状态码及其含义
- Python中函数的4种参数形式
- MyBatisX 基本使用
- 将python程序变成可执行程序 | 进阶篇