图像分割deeplab系列
DeepLab系列是谷歌团队提出的一系列语义分割算法。DeepLab v1于2014年推出,并在PASCAL VOC2012数据集上取得了分割任务第二名的成绩,随后2017到2018年又相继推出了DeepLab v2,DeepLab v3以及DeepLab v3+。DeepLab v1的两个创新点是空洞卷积(Atros Convolution)和基于全连接条件随机场(Fully Connected CRF)。DeepLab v2的不同之处是提出了空洞空间金字塔池化(Atros Spatial Pyramid Pooling,ASPP)。DeepLab v3则是对ASPP进行了进一步的优化包括添加?1×1?卷积,BN操作等。DeepLab v3+则是仿照U-Net的结构添加了一个向上采样的解码器模块,用来优化边缘的精度。下面我们依次介绍这四个算法。
1. DeepLab v1
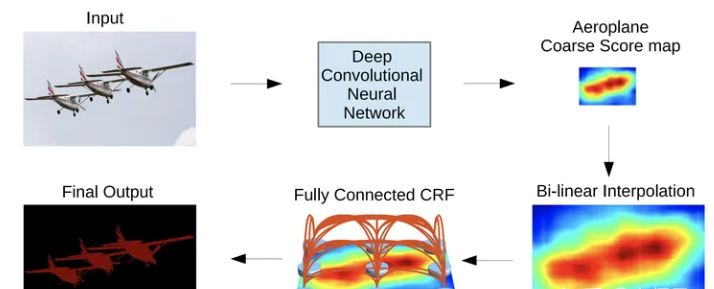
DeepLab v1有两个核心点,即:空洞卷积和CRF。它首先将VGG的普通卷积替换为空洞卷积得到分隔图,在通过CRF将得到的分割图进行后处理优化,如图1所示。
1.1 空洞卷积
在全卷积网络中,Feature Map上像素点的感受野取决于卷积和池化操作。普通卷积的感受野每次只能增加两个像素,增长速度过于缓慢。传统卷积网络的感受野的增大一般采用池化操作来完成,但是池化操作在增大感受野的同时会降低图像的分辨率,从而丢失一些信息。而且对池化之后的图像在进行上采样会使很多细节信息无法还原,最终限制了分割的精度。
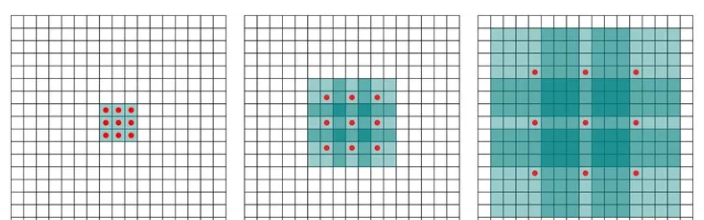
那么如何在不使用池化的情况下扩大感受野呢?空洞卷积应运而生。顾名思义,空洞卷积就是往卷积操作中加入“空洞”(值为0的点)来增加感受野。空洞卷积引入了扩张率(dilated ration)这个超参来制定空洞卷积上两个有效值之间的距离:扩张率为 r的空洞卷积,两个有效值之间有 r?1?个空洞,如图2所示。其中红色的点为有效值,绿色的放个为空洞。如图2.(a)所示,$r=1$是空洞卷积变为普通卷积。
扩张率为?�?的空洞卷积可以标识为式(1)。
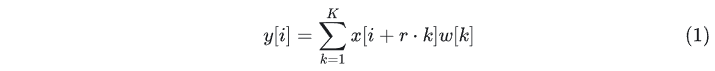
如图2的(b)和(c)所示, r=1?和 r=3?的空洞卷积的感受野分别是?7×7?和?15×15?,但是它们的参数数量依旧是?9?个。目前的深度学习框架对空洞卷积都支持的非常好,仅设置扩张率一个超参即可。
1.2 全连接条件随机场


1.3 DeepLab v1的网络结构
DeepLab v1采用了VGG-16作为基础架构,不同的是DeepLab将降采样的倍数从32?倍下降至?8?倍,它是通过将最后两个block的步长为?2?的max-pooling替换为步长为?1?的max-pooling(另一种说法是将max-pooling去掉)。
在DeepLab v1的论文中共提出了4个不同的网络结构,它们的的参数,准确率以及速度如表1。其中卷积的操作是指添加到网络中最后一层(fc6)的空洞卷积的超参。 从表中我们可以看出,DeepLab-CRF-LargeFOV(Field of View)无论是速度还是精度都表现比较优秀,因此也是被业内广泛采用的网络结构。

2. DeepLab v2
对比DeepLab v1,DeepLab v2依旧保持了图1的流程,即以空洞卷积和CRF为核心。DeepLab v2的改进点之一是将VGG-16替换成了残差网络。另外一个核心点便是引入了空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)。
2.1 ASPP
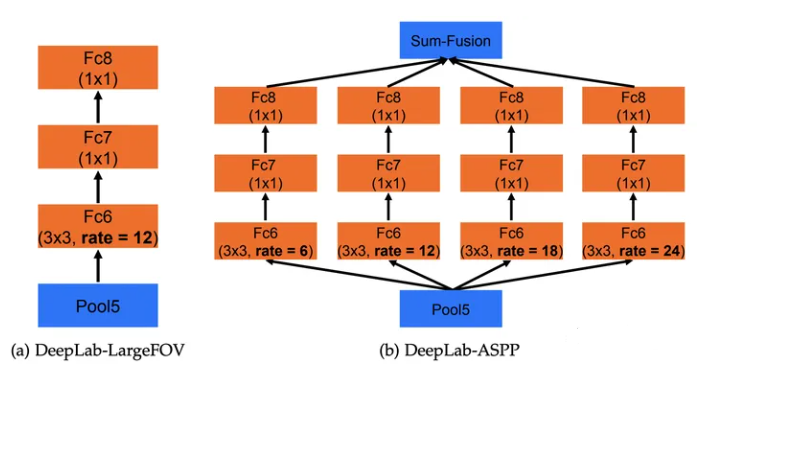
空间金字塔池化是在目标检测的经典算法SPP-Net[6]中提出的思想,它的核心思想是聚集不用尺度的感受野,ASPP的提出也是用于解决不同分割目标不同尺度的问题。它的网络结构如图3所示。

ASPP共提出了ASPP-S和ASPP-L两个不同尺度的ASPP,它们的不同点在扩张率的不同,两个ASPP的扩张率分别是?{2,4,8,12}?和?{6,12,18,24}?。在进行完空洞卷积后再增加两个?1×1?卷积进行特征融合,最后通过单位加得到最终的输出结果,如图4所示。在DeepLab v2中,Pool5之后的空洞卷积被替换为ASPP。
3. DeepLab v3
CRF在DeepLab v3中被移除,而这些都要得益于在网络层部分得到的优异表现,那么为什么DeepLab v3仅凭卷积网络就能达到由于DeepLab v2的效果呢,这得得益于它下面几点改进:
- 引入了Multi-Grid策略,即多次使用空洞卷积核而不像在v1和v2中仅使用一次空洞卷积;
- 优化ASPP的结构,包括加入BN等。
3.1 Multi-Grid策略
DeepLab v3的Multi-Grid策略参考了[7]的HDC(hybrid dilated convolution )的思想,它的思想是在一个block中连续使用多个不同扩张率的空洞卷积。HDC的的提出是为了解决空洞卷积可能会产生的gridding问题(图5)。这是因为空洞卷积在高层使用的扩张率变大时,它对输入的采样会变得很稀疏,进而导致丢失一些局部信息。而且会丢失一些局部相关性反而捕获了长距离一些语义上不相关的信息。

Gridding产生的原因是因为连续的空洞卷积使用了相同的扩张率。在图6.(a)中,连续使用了三个 r=2?的空洞卷积,那么对中心点分类结果的影响则源自于周围分连续的像素点。HDC的原理是对连续的空洞卷积使用不同的扩张率,如图6.(b)中使用的扩张率依次是?(1,2,3)?,那么影响中心点类别的则是连续的一个区域,因此也更容易产生连续的分割效果。同时因为使用了HDC后感受野变得更大了,一定程度上也可以提升模型的分割效果。

在DeepLab v3中,multi-grid的策略是指每个block的三个扩张率由multi-grid参数和unit-rate参数计算而来,例如?Multi-Grid=(1,2,4)?,unit_rate=2?,那么这个block的三个空洞卷积的扩张率依次等于?2×(1,2,4)=(2,4,8)?。作者设计了一组对照实验来优化multi-gird的参数值,最终得到最优的结果是?(1,2,1)?。
3.2 DeepLab v3的ASPP
作者通过实验发现,随着空洞卷积的扩张率的增大,卷积核中有效的权重越来越少,因为随着扩张率的变大,会有越来越多的像素点的计算没法使用全部权重。当扩张率足够大时,只有中间的一个权重有作用,这时空洞卷积便退化成了?1×1?卷积。这里丢失权重的缺点还是其次,重要的丢失了图像全局的信息。
为了解决这个问题,DeepLab v3参考ParseNet[8]的思想,增加了一个由来提升图像的全局视野的分支。具体的说,它先使用GAP将Feature Map的分辨率压缩至?1×1?,再使用?1×1?卷积将通道数调整为?256?,最后再经过BN以及双线性插值上采样将图像的分辨率调整到目标分辨率。因为插值之前的尺寸是?1×1?,所以这里的双线性插值也就是简单的像素复制。
DeepLab v3的另外一个分支则是由1个?1×1?卷积核三个扩张率依次为?(6,12,18)?的?3×3?空洞卷积组成。最后两个分支通过拼接操作组合在一起,再通过一个?1×1?卷积将通道数调整为?256?,如图7所示。
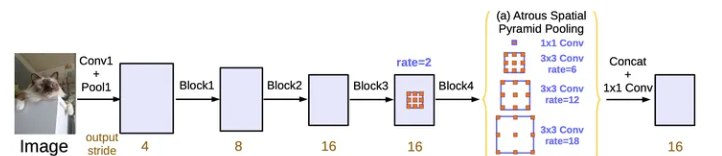
3.3 DeepLab v3的网络结构
DeepLab v3也是使用残差网络作为骨干网络,它的Block-1到Block-4直接复制的残差网络的原始结构,然后又把block4复制了3次,得到了block5-7,它们的不同是使用了不同的扩张率,如图8所示。
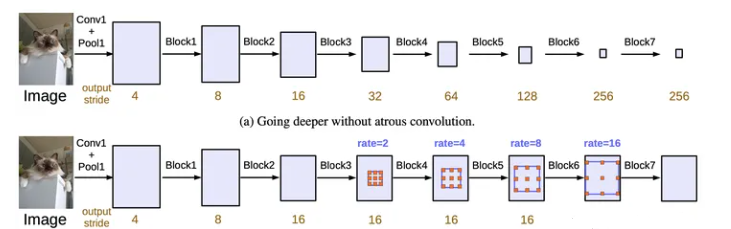
4. DeepLab v3+
到目前为止,DeepLab系列都是在降采样8倍的尺度上进行预测的,导致了边界效果不甚理想。考虑到卷积网络的特征,DeepLab v3的网络的特征并没有包含过多的浅层特征,为了解决这个问题,DeepLab v3+借鉴了FPN等网络的encoder-decoder架构,实现了Feature Map跨block的融合。DeepLab v3+的另一个改进点在于使用了分组卷积来加速。下面我们详细介绍这两个改进
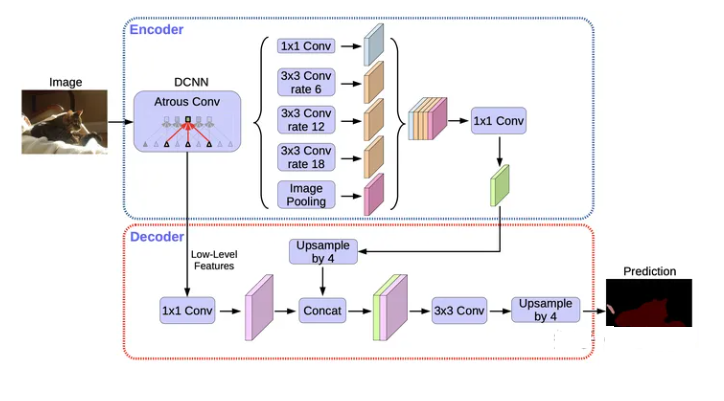
4.1 Encoder-Decoder架构
DeepLab v3+使用DeepLab v3作为Encoder,我们重点关注它的解码器模块。它分成7步:
- 首先我们先通过编码器将输入图像的尺寸减小16倍;
- 使用?1×1?卷积将通道数减小为?256?,后再接一个BN,ReLU激活函数和Dropout;
- 使用双线性插值对对齐进行上采样?4?倍;
- 将缩放$4$倍处的浅层的特征依次经过?1×1?卷积将通道数减小为?48?,BN,ReLU;
- 拼接3和4的Feature Map;
- 经过两组?3×3?卷积,BN,ReLU,Dropout;
- 上采样4倍得到最终的结果。
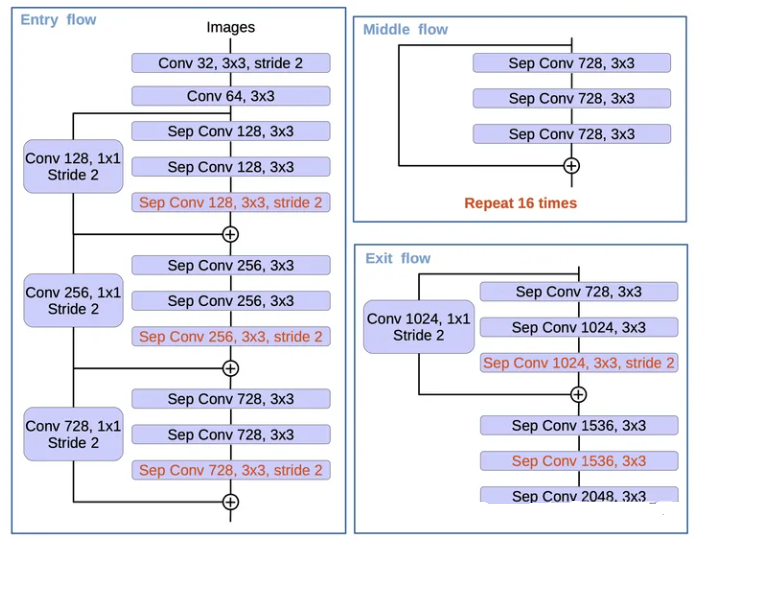
4.2 DeepLab v3+的Xception
这一部分的工作则是受到了可变形卷积[11]的影响,它们提出的基于Xception[10]的改进的网络结构叫做Aligned Xception(图10),DeepLab v3+的改进如下:
- Entry flow保持不变,但是增加了更多的Middle flow;
- 将步长为2的max-pooling替换为深度可分离卷积,这样也便于随时替换为空洞卷积;
- 在深度可分离卷积之后增加了BN和ReLU。
DeepLab v3+的Xception结构如图11所示。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 本地修改暂存 git stash 常见用法
- 【华为OD机试真题2023C&D卷 JAVA&JS】螺旋数字矩阵
- 什么是Maven?
- ArrayDeque阅读记录
- 【nowcoder】链表的回文结构
- 代码随想录打卡第二天| 977.有序数组的平方 209.长度最小的子数组 59.螺旋矩阵Ⅱ
- 设计模式入门
- uniapp上传文件时用到的api是什么?格式是什么?
- java工作流详解
- Opencv(C++)学习之cv::calcHist 任意bin数量进行直方图计算