浅析内存一致性:内存屏障
文章目录
概述
内存屏障,是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以执行此点之后的操作。内存屏障的产生是为了解决程序在运行过程中所产生的内存乱序访问问题。
内存乱序访问
若程序在执行时的实际内存访问顺序和程序代码编写的访问顺序不一致,这就是内存乱序访问。内存乱序访问的出现是为了提升程序执行时的效率,主要发生在两个阶段:
- 编译时,编译器优化导致内存乱序访问(指令重排);
- 运行时,多CPU交互引起内存乱序访问,通常是硬件层面的优化所导致,主要包括以下两个方面:
- 现代CPU采用指令并行技术,引入指令执行级别的乱序优化,如流水线、乱序执行、分支预测等造成的乱序;
- 现代CPU采用内部缓存技术,导致数据的变化不能及时反映到内存中,如硬件级别Cache一致性优化引入的Store Buffer和Invalidate Queue等组件造成的乱序。
Store Buffer和Invalidate Queue
MESI协议解决了缓存一致性问题, 但是其自身也存在一个性能弱点——处理器执行写内存操作时,必须等待其他所有处理器将其高速缓存中的相应副本数据删除并接收到这些处理器所回复的 Invalidate Acknowledge/Read Response消息之后才能将数据写入高速缓存。
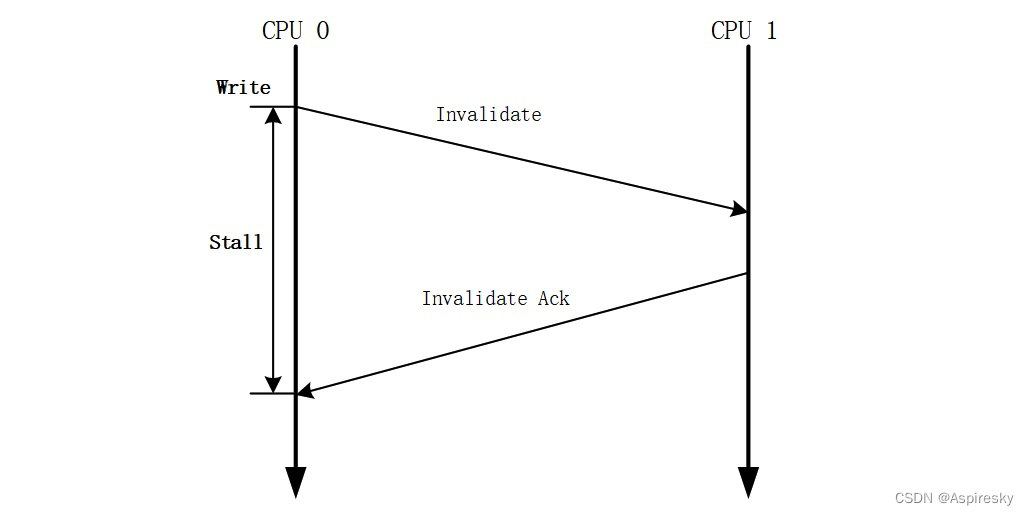
为了规避和减少这种等待造成的写操作的延迟 (Latency),硬件设计者引入了Store Buffer和Invalidate Queue,用于优化缓存一致性协议的性能,与此同时,也导致了一些内存乱序的问题。
Store Buffer
Store Buffer是处理器内部的一个容量比Cache还小的私有高速存储部件,每个处理器都有其Store Buffer,并且一个处理器无法读取另外一个处理器上的Store Buffer中的内容。

引入Store Buffer后,处理在执行写操作时的行为如下:
| 缓存状态 | 操作 |
|---|---|
| Exclusive/Modified | 处理器可能会直接将数据写入相应的缓存行而无需发送任何消息(取决于具体处理器的实现) |
| Shared | 处理器会先将写操作的相关数据存入Store Buffer中,并发送Read Invalidate消息 |
| Invalid | 处理器的高速缓存不含有待操作的数据,遇到了写未命中(Write Miss),处理器会先将写操作的相关数据写入Store Buffer,并发送Read Invalidate消息,此后处理器继续运行 |
在写数据之前我们先要得到缓存行的独占权,如果当前CPU没有独占权,要先让系统中别的CPU上缓存的同一段数据都变成无效状态。为了提高性能,可以引入一个叫做Store Buffer的模块,将其放置在每个CPU和它的缓存之间。当前CPU发起写操作,如果发现没有独占权,可以先将要写入的数据放在存储缓冲中,并继续运行,仿佛独占权瞬间就得到了一样。当然,存储缓冲中的数据最后还是会被同步到缓存中的,但就相当于是异步执行了,不会让CPU等了。并且,当前CPU在读取数据的时候应该首先检查其是否存在于存储缓冲中。
Store Forwarding
允许处理器直接从Store Buffer中读取数据来实现内存读操作的技术被称为存储转发(Store Forwarding)。 存储转发使得写操作的执行处理器能够在不影响该处理器执行读操作的情况下将写操作的结果存入写缓冲器。
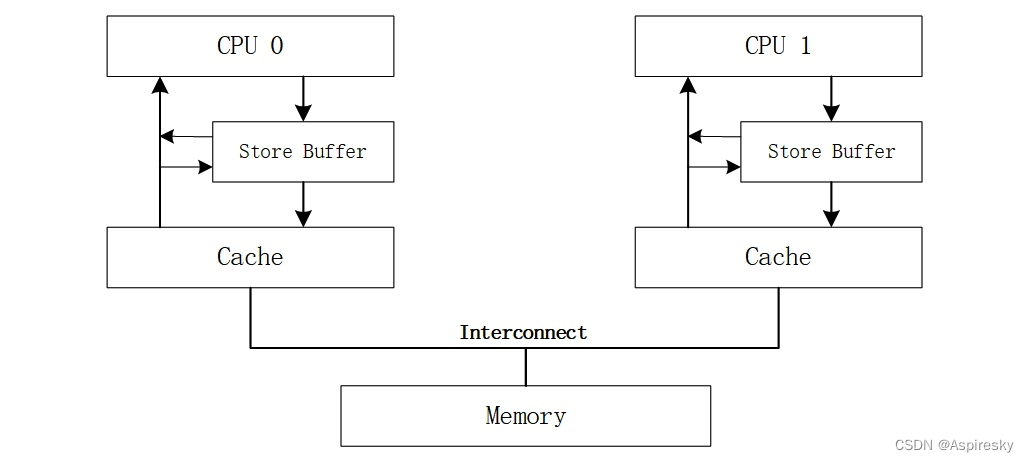
Store Buffer与内存屏障

Invalidate Queue
如果当前CPU上收到一条消息,要使某个缓存段失效,但是此时缓存正在处理其它事情,那这个消息可能无法在当前的指令周期中得到处理,而会将其放入所谓的Invalidation Queue中,同时立即发送使无效应答消息。那个待处理的使无效消息将保存在队列中,直到缓存有空为止。

Invalidate Queue与内存屏障

内存屏障分类
内存屏障允许软件开发者使用硬件提供的特殊指令控制编译器和CPU的行为,在可能存在并发访问问题的点禁止编译器指令重排和CPU对指令乱序执行。为了解决上述的内存访问乱序问题,系统提供了两种类型的内存屏障:编译器屏障和CPU内存屏障。
编译器屏障
编译器屏障用于阻止编译器进行指令重排,保证其在编译程序时,在优化屏障之前的指令不会在优化屏障之后执行。编译器提供了barrier() 宏实现编译器屏障:
#define barrier() __asm__ __volatile__("": : :"memory")
需要注意的一点是,barrier()只会约束编译时的指令重排行为,不约束CPU运行时的行为,CPU仍然可以乱序执行程序。
CPU内存屏障
CPU内存屏障用于防止CPU运行时指令之间的重排序行为,并保证数据对其它CPU的可见性。CPU内存屏障通常可分为三类:
- 通用屏障,保证读写操作有序;
- 读操作屏障,仅保证读操作有序;
- 写操作屏障,仅保证写操作有序。
相关参考
- 《Memory Barriers: a Hardware View for Software Hackers?》
- 《A Primer on Memory Consistency and Cache Coherence》
- 多种内存一致性模型的特性分析
- 第五章:乱序执行
- 计算机体系结构-重排序缓存ROB
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《EnlightenGAN: Deep Light Enhancement withoutPaired Supervision》论文超详细解读(翻译+精读)
- antd+vue:tree组件:父级节点禁止选择并不展示选择框——基础积累
- 索引不是银弹
- Matlab论文插图绘制模板第135期—隐函数曲面图(fimplicit3)
- 计算机组成原理之计算机的性能指标和数制与编码
- PG DBA培训24:PostgreSQL性能优化之分区表
- 5214手持式千兆网络质量测试仪
- 使用 JSON 文件保存标签对应的索引是为了方便数据的加载和处理
- Angular系列教程之路由守卫
- 5g消息-5G时代短信升级-富媒体智能交互-互联网新入口