AutoDL——终端训练神经网络模型(忽略本地问题)
发布时间:2024年01月20日
前言:
本人之前分享过一篇文章:使用pycharm连接远程GPU训练神经网络模型(超详细!),其中详细介绍了如何利用pycharm连接AutoDL算力云平台租用的GPU服务器训练神经模型。但有些小伙伴可能会因为一些原因而导致模型训练意外中止,这里博主说明一下如何在AutoDL终端进行模型训练,从而避免此类问题。
1、租用GPU服务器
2、资源的上传与下载
前两步在上一篇文章都详细介绍过,不清楚的小伙伴可查看一下。
3、终端训练神经网络模型
租用GPU并完成相关资源的上传后,大家进入控制台的容器实例界面,在快捷工具中点击进入JupyterLab,如下图所示。
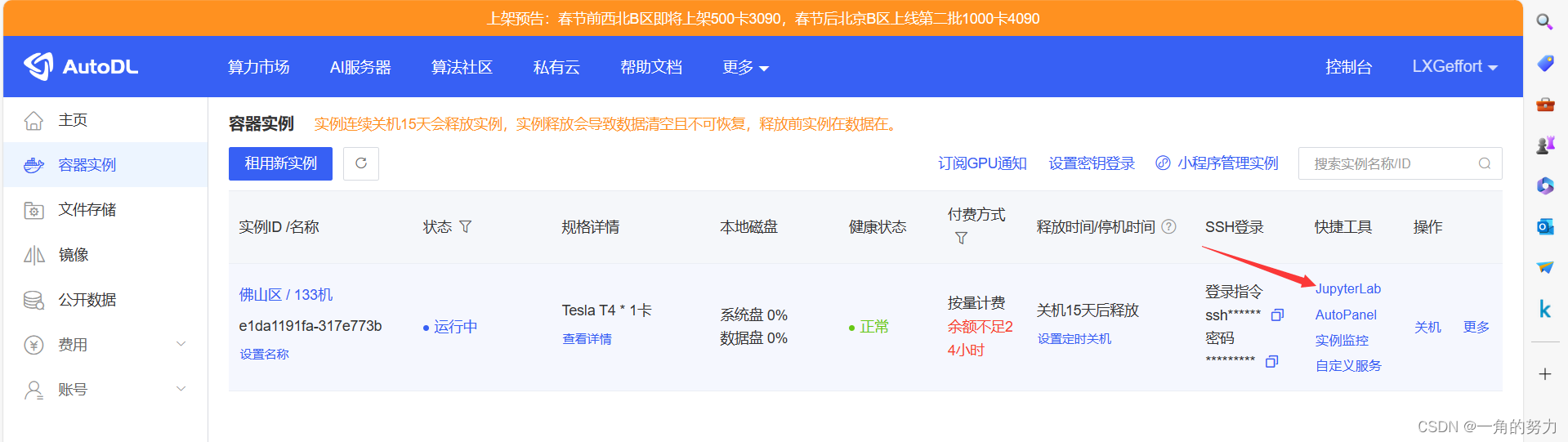
点击进入终端,如下所示。
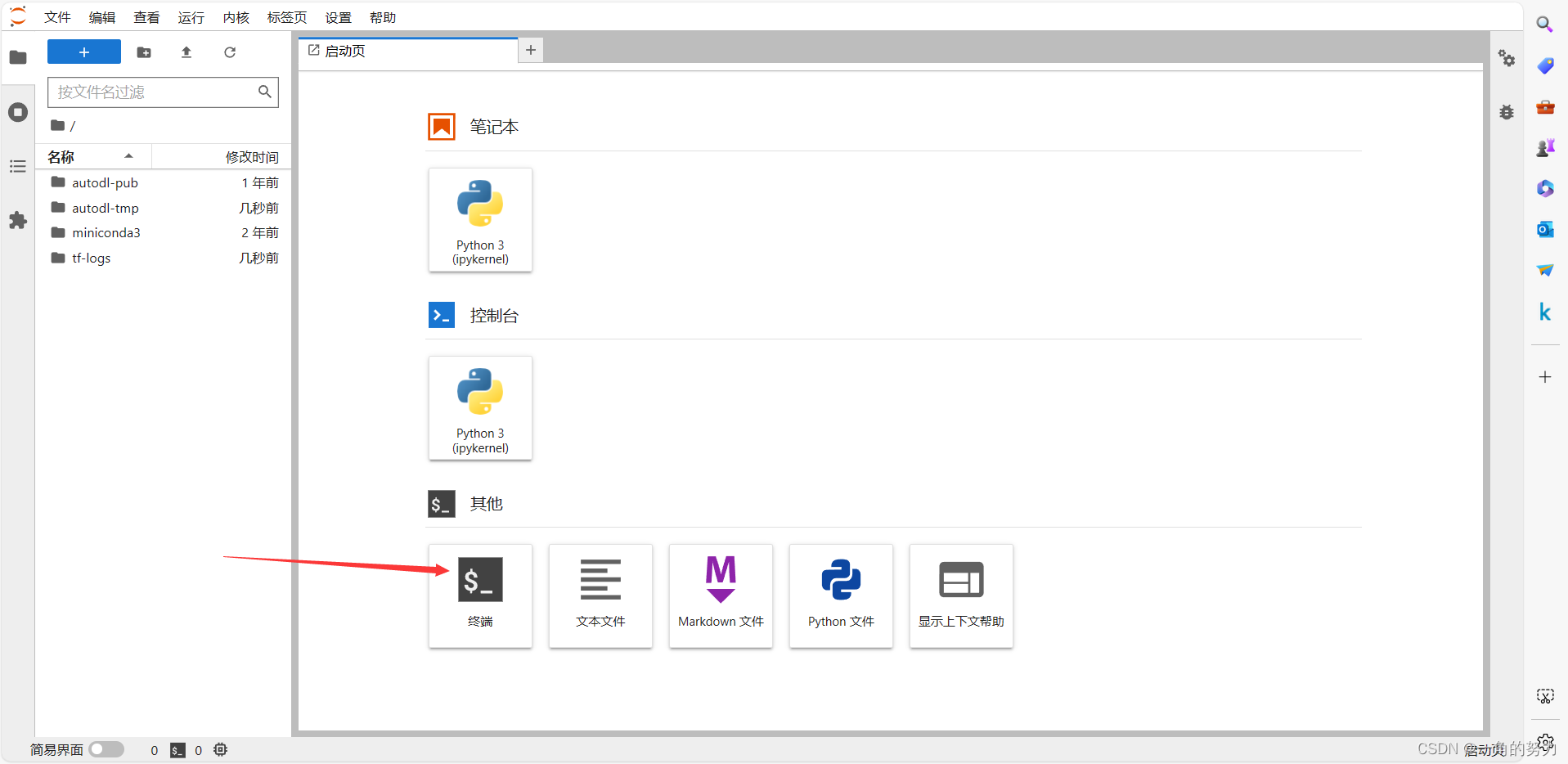
在终端输入相关命令:
(1)通过 'cd' 命令跳转到GPU服务器中已经上传的代码文件的目录(资源的上传与其相关目录上一篇文章已详细介绍);
(2)通过命令:python 训练文件.py进行模型的训练。
如下所示:
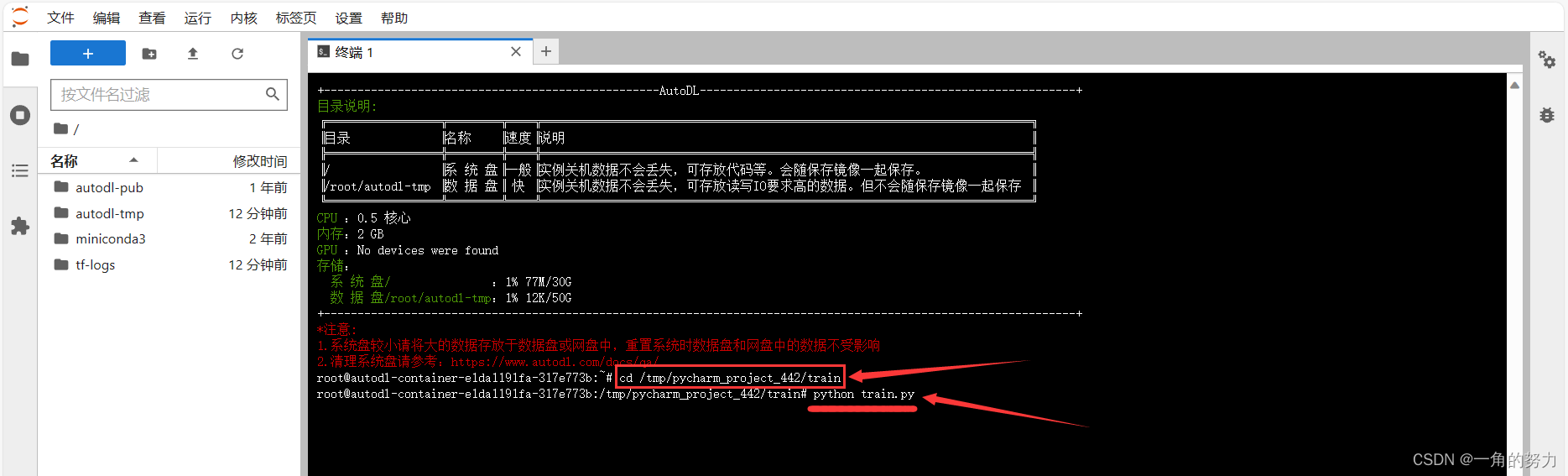
注意:跳转的资源文件目录随大家自己的情况进行更改
此方法无需pycharm连接GPU服务器,且可避免因网络、电脑本身等原因而导致的训练意外中止的问题(即训练开始后本地问题都可忽略)。建议大家使用pycharm连接GPU服务器时用于调试代码,而训练在终端进行。
训练效果如下所示:
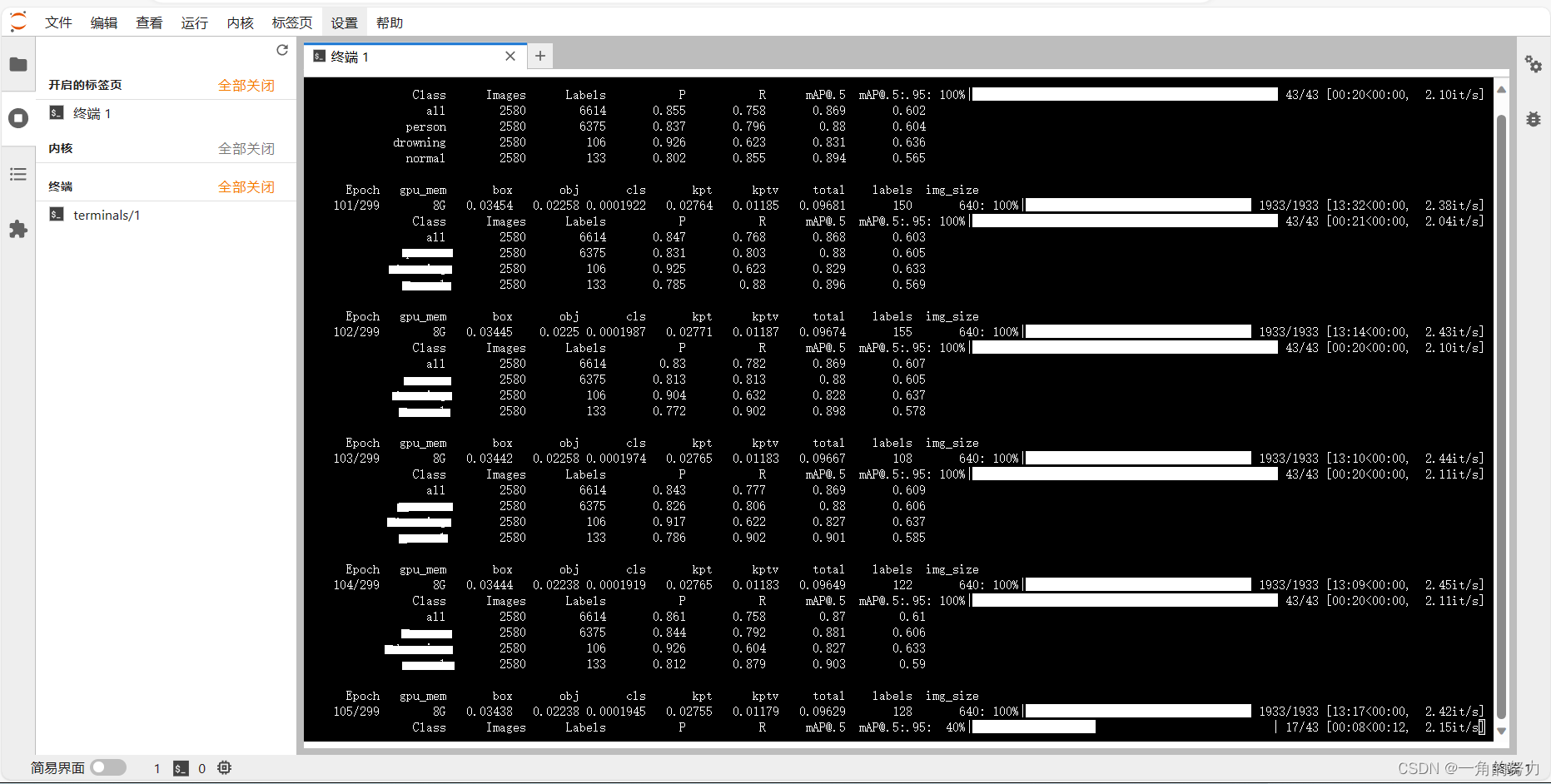
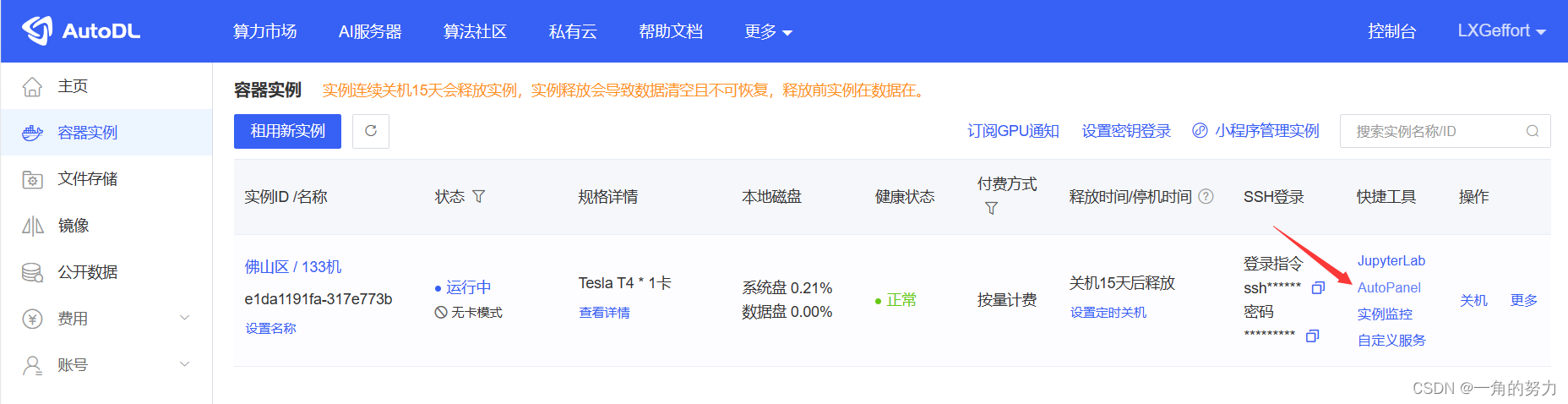
(3)大家可开启第二个终端界面,输入命令:nvidia-smi 查看GPU监控信息,不过这种方法得到的GPU训练数据不直观,大家可直接在容器实例中进入AutoPanel,里面可以很直观地查看GPU训练时的相关信息。
OK,以上就是本次文章的全部内容,有任何疑问大家可在评论区进行留言讨论,感谢大家的阅读!
文章来源:https://blog.csdn.net/weixin_64388392/article/details/135683697
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《Linux C编程实战》笔记:Linux信号介绍
- CRM管理系统是怎样分析客户行为的?CRM客户管理功能解析
- 《ORANGE’S:一个操作系统的实现》读书笔记(二十七)文件系统(二)
- MySQL中常用的用户授权操作
- 频率域滤波图像复原之带阻滤波器的python实现——数字图像处理
- P2089 烤鸡
- 多切片联合构建3D生物空间图谱
- 计算机网络——应用层(3)
- Pandas实战100例 | 案例 44: 添加新列
- 计算机专业大学生毕业论文中的文献综述该怎么写呢?