【c++】入门2
函数重载
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型
不同的问题。
c++区分重载函数是根据参数的不同,个数的不同,类型的不同,顺序的不同。
1.参数的类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
2.参数的个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
3.参数的顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
注意:同类型的参数不属于函数重载
void f(int a, int b)
{
cout << "f(int a,int b)" << endl;
}
void f(int b, int a)
{
cout << "f(int b, int a)" << endl;
}
上述代码不属于函数重载
不同的命名空间不算重载
#include <iostream>
using namespace std;
namespace zjw
{
int add(int a, int b)
{
return a + b;
}
}
namespace ggw
{
double add(double a, double b)
{
return a + b;
}
}
int main()
{
zjw::add(1, 2);
ggw::add(1.1, 2.2);
}
上述不属于函数重载。
那么c++在处理重载函数的时候,会不会变慢,因为要区分重载函数?
不会,处理重载函数是在编译时候完成,而速度是运行决定的。
编译识别函数
在vs中编译识别重载函数有些复杂
当只有声明,没有定义时,会出现报错。

==我们可以在linux下来验证是否会修饰重载函数。==由于vim有些地方需要配置,所以这里以后再加。
步骤1.vim test.c (test.c是创建好的)
步骤2. gcc -o tc test.c(使用gcc编译器编译test.c),会生成一个tc的文件
步骤3.objdump -S tc (查看对应的汇编指令)
同理:1.g++ -o tcpp test.c (会编译生成一个tcpp的文件)
2.objdump -S tcpp (查看对应的汇编指令)
同名函数的区分
修饰以后的函数名,windows和linux修饰规则不一样。
比方说下面这个函数在linux下
void add(int a,int b)
修饰后
_Z3addii()
3代表函数名长度,add为函数名,i,i 分别是两个变量的类型简写
返回值不同无法构成重载,不是因为修饰规则中没有,而是在调用处无法区分。调用处一般不写返回类型。
引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空
间,它和它引用的变量共用同一块内存空间。
int main()
{
int a = 7;
int& b = a;
printf("0x%x\n", &a);
printf("0x%x\n", &b);
}
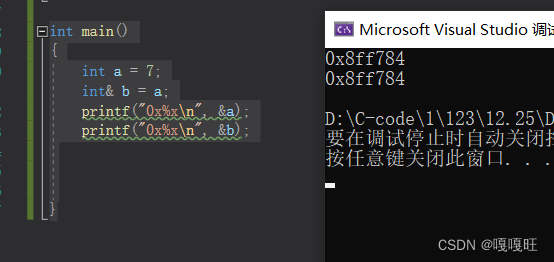
地址相同说明共用一个内存空间。
举个例子
void swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 4;
int b = 5;
swap(a, b);
}
上述代码只能将实参的值拷贝给形参,当swap()完成后形参被销毁,不能完成主函数中的a,b的交换。我们学习c语言之后我们会传地址过去,用指针接收完成主函数a,b的交换。
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int main()
{
int a = 4;
int b = 5;
swap(&a, &b);
}
当我们学了引用之后,我们可以这样做
void swap(int& c, int& d)
{
int tmp = c;
c = d;
d= tmp;
}
int main()
{
int a = 4;
int b = 5;
swap(a, b);
}
这种相当于用了引用,引用相当于起别名,形参用自己的别名接收,实际上就是修改自己本身。
同时也可以给指针加引用
int main()
{
int i = 7;
int* p = &i;
int* &rp = p;
printf("0x%x\n", &p);
printf("0x%x", &rp);
}
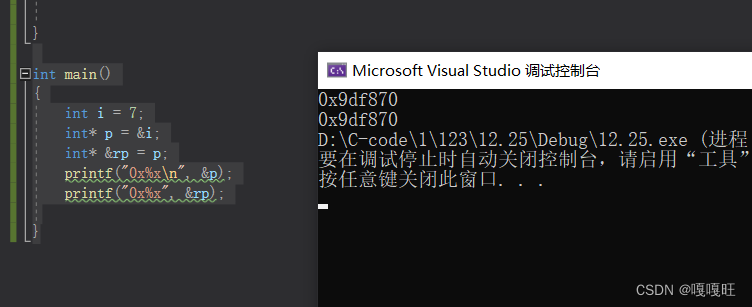
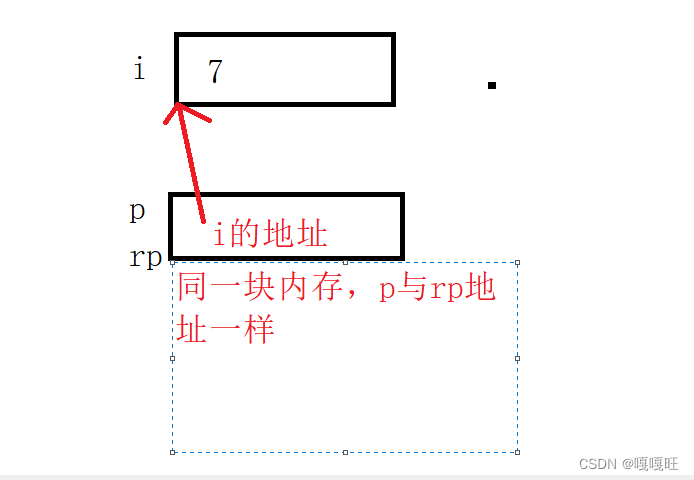
我们学完单链表,比方说单链表的尾插;
单链表的尾插代码
void pushback(info** pphead, int x)//尾插
{
info* newnode = BuySListNode(x);//将创建好的新结点的地址保存在newnode变量中
if (*pphead == NULL)//链表无结点
{
*pphead = newnode;// 将创建好的头节点的地址给给*pphead,作为新头节点的地址
}
else
{
info* tail = *pphead;//定义一个指针,先指向头结点的地址
while (tail->next != NULL)//循环遍历找尾结点
{
tail = tail->next;//指针指向下一个结点
}
tail->next = newnode;//找到尾结点,将尾结点的next存放新接结点的地址
}
}
当我们在主函数中定义了一个结点head,我们要实现在head后面实现尾插,要改变head->next,如果直接用一级指针接收的话,只是head结点数据的拷贝,尾插是给拷贝的结点尾插,况且puchback完会释放,所以我们传二级指针,为的就是尾插在head后面,当用二级指针时,我们会感到理解困难,当学了引用后
void pushback(info* &pphead, int x)//尾插
此时pphead就是head的别名,修改pphead就是修改head,方便多了
此外我们还可以连续起别名
int main()
{
int i = 7;
int& a = i;
int& b = a;
int& c = i;
printf("a=%d b=%d c=%d", a, b, c);
}
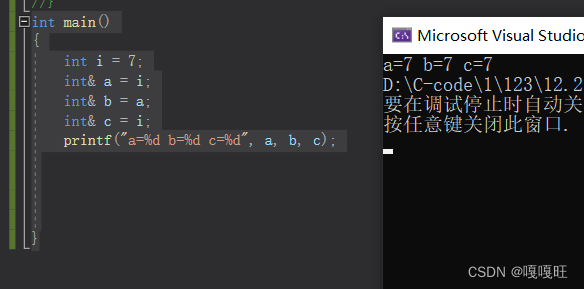
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 百度搜索创新大赛,一场2800人的技术狂欢
- LeetCode 28.找出字符串中第一个匹配项的下标
- 深入理解——面向对象和面向过程
- 在线电路仿真分析 : CircuitJS + EveryCircuit + 嘉立创EDA
- 【Java数据结构】复习笔记-4.8w字全
- DAY15
- 基于laravel、vue开发的医院手术麻醉管理系统源码,自主版权,二开快捷。
- 油烟净化器绿色低碳,引领餐饮“天空蓝”新时代
- 「HDLBits题解」Vector5
- Qt菜单工具栏和状态栏