高翔博士Faster-LIO论文和算法解析
说明
题目:Faster-LIO:快速激光IMU里程计
参考链接:
Faster-LIO:快速激光IMU里程计
iVox (Faster-Lio): 智行者高博团队开源的增量式稀疏体素结构
Faster-Lio是高翔博士在Fast系列的新作,对标基线是Fast-LIO2,核心是提出一种新的"数据结构"ivox,类似于Fast-LIO2中的ikd-tree,用于点云配准搜索和地图的增量更新。效果上整个LIO系统的用时相比Fast-LIO2有较大幅度的下降,精度上评估了每百米的APE和RPE,从结果上看有好有差。近年来的作品精度上似乎都大差不差,如LIO-SAM,FAST-LIO系列,更多的都是在卷实时性。
对于本文来说需要重点理解增量稀疏体素结构ivox和ivox-PHC,对于整个系统的流程可以参考FAST-LIO2。
摘要
本文提出了一种基于增量体素的激光惯性里程计(LIO)方法,用于快速跟踪机械式和固态激光雷达扫描。为了达到较高的跟踪速度,我们既没有使用复杂的基于树的结构来划分空间点云,也没有使用严格的k近邻(K-NN)查询来计算点匹配。相反,我们使用增量体素(iVox)作为我们的点云空间数据结构,它是在传统体素的基础上修改的,支持增量插入和并行近似k-NN查询。我们提出了线性iVox和PHC(伪希尔伯特曲线)iVox作为我们算法中的两个备选底层结构。实验表明,ivox的扫描速度在固态激光雷达中达到1000-2000Hz/秒,在32线旋转激光雷达中仅使用现代CPU扫描速度超过200hz,同时仍保持相同的精度水平。
一、简介
论文的出发点在于提高点云配准时的处理效率,在Fast-Lio2中使用了ikd-tree来提高点云的搜索效率,但kd-tree的维护以及挨个节点的遍历同样需要消耗一定的时间,因此提出一种基于稀疏体素的近邻结构iVox(incremental voxels),该方法可以有效的降低点云配准时的耗时,也不会影响LIO的精度表现,iVox是本文的核心内容。
相比与八叉树体素结构的完全体素化,iVox提供一种稀疏的体素表达,即只在空间点存在的地方建立和维护体素结构,因为空间点的位置是唯一的,可以使用一个哈系表来统一构建和维护体素结构,将空间点的坐标作为Key,将坐标带入哈系函数生成的唯一索引作为value。对于少量点匹配提出线性iVox结构,对于大量点的配准提出iVox-PHC,以便快速地查找任意近邻。
高速点云配准和三维重建是许多项目产品的关键模块——从高清地图(HD maps)[1] -[3]到自动驾驶汽车[4],[5]。最常见的实时激光雷达跟踪方法,如LOAM[6]、LeGO-LOAM[7]和balm[8],每次迭代大约需要100毫秒来处理一次激光雷达扫描。大多数传统的旋转激光雷达在这个速度下提供多线扫描。随着光学技术的发展,Livox和Cepton等现代固态激光雷达传感器可以提供100 Hz甚至更高频率的密集点云扫描[9],[10]。因此,寻找一种高效的激光雷达跟踪方法已成为近年来重要的研究课题[11],[12]。对于许多真实的机器人或车辆来说,LIO并不是系统中运行的唯一算法。所有活动模块必须共享计算资源。如果我们有一个更快、更轻的LIO,这个系统会更坚固。此外,还可以使用更快的LIO方法作为离线地图系统的前端,以帮助减少计算时间。
基于激光雷达或视觉的SLAM系统通常包括用于点云跟踪的实时前端和用于状态优化的后端[13]-[15]。在现实世界的激光雷达里程计系统中,人们还将以松耦合或紧耦合的形式将惯性和GPS测量融合到状态估计器中,以使系统对短时传感器故障更具鲁棒性[16],[17]。从理论上分析整个复杂SLAM系统的计算成本并不容易。然而,一般来说,对于前端部分(LO/LIO模块),计算时间成本主要来自以下几个方面:
(1)所选的空间数据结构
由于传统的配准方法通常依赖于点云中的k近邻(k-NN)搜索,因此可以通过利用更快的k-NN数据结构来提高配准效率[19]。一些为不变空间数据库设计的数据结构(如R*-tree[20]、B*-tree[21])不适合实时LIO,因为LIO需要快速构建和查询速度。此外,由于点云是按顺序处理的,因此增量更新结构会更好。因此,体素和k-d树(及其变体)[22]、[23]是LO/LIO系统的更好选择。当然,体素和k-d树仍然有其局限性。体素几乎在恒定时间内易于构建和删除,但不能进行严格的k-NN搜索或范围搜索。k-d树可以提供严格的k-NN搜索和范围搜索结果,但需要额外的努力来摆动和平衡树。
*(2)状态估计器的创建
姿态估计器也会影响LIO模块的计算成本。在现代VIO或LIO系统中,人们倾向于在传统的单帧卡尔曼滤波器和全姿态图优化/BA之间选择折衷解决方案,如滑动窗口滤波器(SWF)[24]、多状态约束卡尔曼滤波器(MSCKF)[25]或迭代扩展卡尔曼滤波器(IEKF)[26]。它们都具有像滤波器一样的小计算成本和像优化方法一样的相对足够的精度的优点。
(3)匹配的残差度量
匹配点云的残差度量也会影响激光雷达系统的效率。在自动驾驶数据集中,点对平面和点对线模型通常比点对点模型表现更好,因为激光雷达点云是稀疏的,并且同一点并不总是可观测的。此外,对于[27]、[28]等基于特征的系统,将首先将点分类为几个语义类(地板、杆、平面),以加快匹配过程。这些特征减少了注册点的数量,但在这样的系统中,额外的特征提取时间是不可避免的。
这篇论文提出了一种基于稀疏、增量体素的LIO算法,称为Faster-LIO,它基本上是从FastLIO2[18]发展而来的。在LIO中使用稀疏体素代替k-d树(及其变体)的想法受到以下方面的启发:
1)严格的k-NN搜索和范围搜索对于残差计算是不必要的,特别是对于LIO系统,其中IMU测量可以获得大致准确的初始猜测。k-d树的主要优点是它能够通过用超平面有条件地划分高维空间来提供严格的k-NN和范围/框搜索结果。然而,在最坏的情况下,搜索算法可能会深入到非常遥远的分支中,以寻找潜在存在的最近邻居,这不太可能对局部平面系数估计有用。相反,基于体素的算法中的搜索范围被限制为预设值,使得丢弃这样的邻居不会影响大多数残差。
2)k-d树节点的构建、迭代、平衡、移除会影响LIO的效率,而体素不存在这些问题。我们在体素中使用保守的插入和被动删除策略,而不是在每个扫描处理阶段强制更新。
我们的贡献可以总结如下:
- 我们提出了稀疏增量体素(iVox)来组织点云,而不是树状结构。我们证明,与LIO中常用的ik-d树和其他数据结构相比,iVox可以实现更高的增量更新和k-NN搜索速度。
- 我们在iVox中提出了两种可供选择的底层结构:线性iVox和iVox-PHC。实验表明,当我们在每个体素中有更多的点时,iVox-PHC具有更好的计算效率,而当数量较少时,线性iVox表现更好。
- 我们使用并行k-NN搜索来构建一个紧密耦合的LIO系统,固态激光雷达的速度超过1500Hz,旋转机械激光雷达数据的速度超过200Hz(见图1),算法已经在github上进行了开源。
二、相关工作
最近的几项研究集中在快速点云配准上,其中还融合了惯性测量以形成LIO系统。我们在这里简要回顾一下这些作品,并讨论一下我们之间的区别。
LiTAMIN[2]和LiTAMIN2[29]提出了一种通过减少配准点的数量并将对称KL散度引入传统ICP的快速配准方法。它们的灵感来自著名的无损检测方法,该方法首先将点划分为单独的体素,然后在每个体素中执行正态分布变换。这封信报告了使用64线旋转激光雷达的Kitti数据集中约500–1000 Hz的频率。速度令人印象深刻,但主要是通过减少相关点的数量而不是使用更紧凑的数据结构进行邻居搜索来实现的。此外,它们没有开源实现,报告的准确性略低于传统方法[30]。
FastLIO[18]和FastLIO2[26]是在大规模场景中实现近100Hz的LIO系统。增量k-d树显著减少了树的更新时间,这也在我们的实验中得到了验证。通过使用SMW等式来减小观测方程的维数,进一步改进了迭代EKF中的卡尔曼增益计算。尽管如此,我们表明iVox甚至比FastLIO2中的ik-d树更快,同时实现了相同的精度水平。
对于旋转激光雷达,也有低延迟方法(LoLa SLAM[31]、LLOL[32]),它们不等待完全扫描,而是使用部分扫描数据来执行配准。这种加速是通过将扫描分割成几个模式来实现的,并且配准点的数量也比处理完整扫描小得多。不幸的是,这种方法只适用于旋转激光雷达,很难扩展到固态激光雷达。
如果目标平台配备GPU,则深度学习注册方法[33]、[34]和GPU加速注册[30]是SLAM中广泛使用的选择。凭借GPU的并行计算能力,大多数SLAM过程,如特征检测、特征匹配,甚至整个地图,都可以存储在GPU内存中,并以非常高的速度加速。然而,由于基本基础设施不同,我们没有将我们的方法与GPU加速的方法进行比较。
对于一般的空间数据存储,体素哈希也是替换分层树状结构的常用方法。[35]在视觉SLAM系统中使用散列体素进行地图管理,[36]使用体素散列进行体积3D重建。此外,这篇论文表明,离散体素可以用于LIO系统的最近邻搜索和增量映射。
在以下章节中,我们首先介绍iVox及其PHC版本的数据结构和原理。然后,我们展示了我们的方法与最先进的LIO算法之间的比较实验。
三、iVox:增量稀疏体素结构
3.1 iVox的数据结构
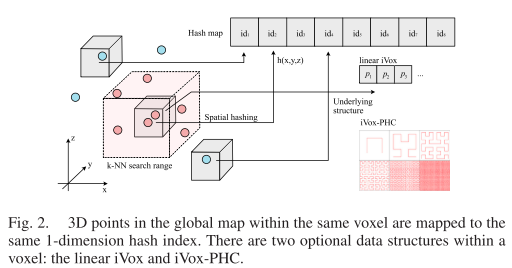
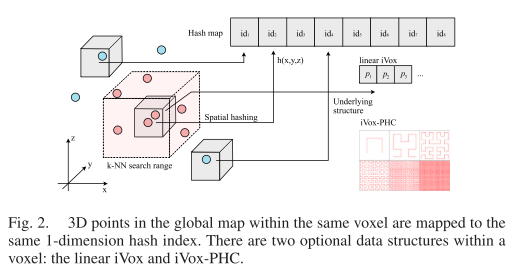
在iVox中,点云首先存储在稀疏体素中,其索引通过离散函数离散为unordered map(见图2)。由于激光雷达点云是稀疏的,我们不使用任何像TSDF[37]这样的体积表示,而是使用仅存储具有至少一个点的体素的稀疏哈希图。离散索引可以通过任何空离散算法(如[38])来计算,本篇论文使用以下离散函数:
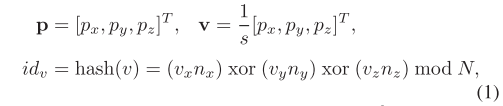
p为三维点,v为体素网络,s为体素大小,id是它的哈希键值,xor表示异或,N表示哈系表容量
函数的意义为:
(1)体素的空间坐标 = 空间物理坐标 × 体素边长,即v=1/s * p,体素空间坐标为哈系表的key
(2)对v的各个维度各乘以一个很大的整数再作异或位运算,得到的结果再对哈系表的容量N取余,得到体素的index–
i
d
v
id_v
idv?,该index作为哈系表的value
每个体素内的点要么存储为向量,要么存储为底层内部结构,如PHC(见第四节),我们相应地将其称为线性iVox和iVox-PHC。使用线性iVox或iVox-PHC,每个体素内的k-NN搜索复杂度为O(n)或O(k),其中n是体素内点的数量,k是离散PHC曲线的阶数。然而,我们将防止在LIO中的增量映射步骤中将过多的点插入到同一体素中,因此不会有太大区别。
3.2 iVox的k-NN搜索
iVox的k-NN搜索被限制在预定义的范围内,然后被分为三个步骤。给定iVox结构V和查询点P,我们将:
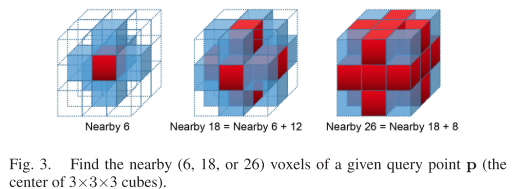
1)找到体素索引和附近的体素(在我们的实现中,从6、18、26个体素,见图3),表示为S。
2)遍历S中的每个体素,并在每个体素中搜索最多K个邻居(地图点)。
3)合并搜索结果并选择最佳的K个邻居。
注意,对于每个体素,步骤2可以被并行化。然而,由于该算法已经在点云级别上被并行化,因此没有必要在这里对每个体素执行并行搜索。iVox中的k-NN搜索简单、有效,但与树状算法相比并不严格,但足以用于LIO应用。
3.3 iVox的增量映射
iVox的增量映射有两个方面:增量添加和删除。
增量添加非常简单,可通过在体素中插入新点和创建新体素来完成。为了避免在一个体素中积累过多的点,我们以与FastLIO2相同的方式,通过类似VoxelGrid的滤波器省去了不必要的点插入。由于我们已经计算了最近邻居的体素指数,如果其任何邻居比其自身更靠近体素网格的中心,我们将不插入当前点。滤波器的leaf size是调整精度和速度之间权衡的关键参数。较大的leaf size以k-NN精度为代价防止过多的插入到一个体素中。根据我们的经验,0.5米的leaf size在大多数数据集中通常都能很好地工作。
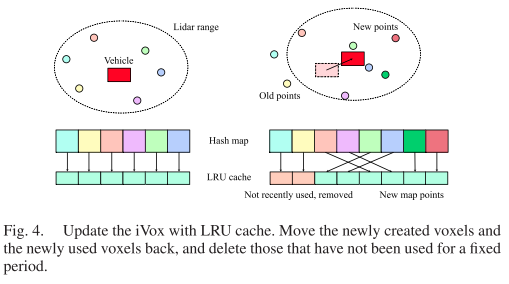
增量删除与k-d树结构不同,因为遍历整个体素哈希图时间代价太昂贵。因此,我们不是在空间窗口中主动删除当前视野之外的点,而是在时间窗口中使用最近最少使用的缓存(LRU缓存)策略来维护局部映射(见图4)。除了体素哈希图,我们还记录最近访问的体素队列,并建立最大尺寸(maximum)。如果体素的数量超过最大值,我们将消除内存中的旧体素,因为插入和删除在哈希图中是O(1),并且对于实时LIO算法来说计算非常便宜。
在进行近邻搜索时,记录哪些体素是最近使用过的,那么不怎么使用的体素自然被移动到队尾。我们会设置一个局部地图的最大容量,超过最大容量时,就删除那些很久未使用的体素。
四、iVox-PHC
4.1 iVox-PHC的基本结构
iVox-PHC是IVox的另一种实现方式,它用伪希尔伯特曲线(PHC)取代了每个体素内部的线性布局(如图中的右侧部分)。尽管我们防止在LIO管道中的同一体素中插入过多的点,但随着点数量的增长,k-NN搜索的性能仍将线性下降。像PHC这样的空间填充曲线是从低维空间到高维空间的映射,同时保持局部性。因此,它们适用于在体素内部或整个点云中寻找近似的最近邻居[39],[40]。
在实现过程中,我们将体素拆分为 ( 2 k ) 3 (2^k)^3 (2k)3个较小的立方体,其中K是可配置的PHC序列。例如,在本文中令k=6,该值可以通过体素的物理大小确定。这些立方体根据其在PHC中的位置为其赋予0- ( 2 k ) 3 ? 1 (2^k)^3-1 (2k)3?1的索引。每个立方体存储立方体内所有点的质心。如果插入的点位于立方体的范围内,质心将更新。
-
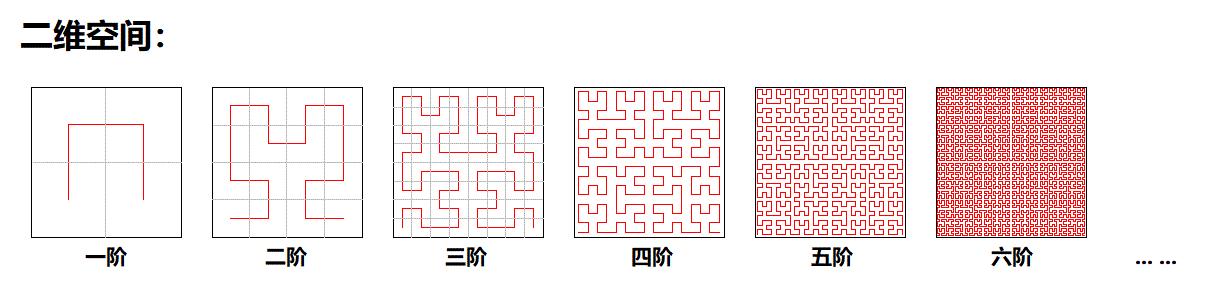
希尔伯特曲线: 全称希尔伯特空间填充曲线(Hilbert space-filling curve, or Hilbert curve),是空间填充曲线的一种。如下图所示,其基本原理是将空间分成一个个小单元,然后把这些单元的中心点用一条分段曲线(折线)连接起来,因为曲线是一维的(分段曲线拉直了不就是一维么),但被它连接起来的各个单元是位于高维空间的,这样,这个曲线就具有了将高维空间的元素映射到一维空间的能力,我们可以据此在一维空间中来索引高维空间的存在.
-
伪希尔伯特曲线: 在取极限状态下希尔伯特曲线可以将整个空间填充,对于本文的应用场景没有必要取极限的阶数(本文阶数为6),所以称为伪希尔伯特曲线。
4.2 基于iVox-PHC的k-NN搜索
两个元素在高维空间中是邻近的,那么它们在希尔伯特曲线上也是基本邻近的 ,利用希尔伯特曲线这一性质可以实现对PHC空间中点的搜索。
Vox-PHC的k-NN搜索与线性iVox略有不同,其中我们可以使用填充函数H来计算任何给定三维点的一维索引(见图5)。假设H函数及其逆函数为:
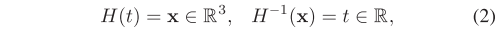
其中t是一维索引,x是点所在的对应立方体。然后,对于属于立方体x的给定点p的k-NN搜索,可以通过统计 H ? 1 ( x ) H^{-1}(x) H?1(x)前后的第k个立方体来近似求解。这些立方体的质心作为k个最近邻居返回。
如果我们想添加一个额外的范围条件,比如将搜索大小限制在
r
s
r_s
rs?内,那么PHC中的索引搜索范围ρ可以计算为:
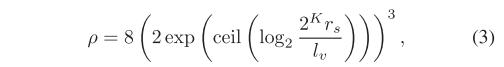
其中 l v l_v lv?是每个体素的物理尺寸,该尺寸由 m i n ( k , ρ ) min(k,\rho) min(k,ρ)确定。
请注意,PHC中的最近邻居也是近似的。对于两点A和B,考虑PHC中的长度
l
A
B
l_{AB}
lAB?和3D空间中的欧氏距离
d
A
B
d_{AB}
dAB?,我们得到:
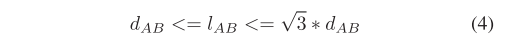
以一种非正式的方式,在足够大的空间内,我们通过PHC找到的最近的邻居的距离是预期的√3倍。尽管这种近似带来了不精确性,但它不会影响LIO中的配准,正如我们后来的实验所证明的那样。
4.3 iVox和iVox-PHC复杂度
时间复杂度来自两个方面:增量地图更新和k-NN搜索。
(1)增量地图更新
增量地图更新涉及在LRU缓存中插入和删除体素以及在体素中插入点。由于LRU缓存是由内部双链表的unordered map实现的,因此节点插入和删除的时间复杂度为O(1)。iVox线性的点插入也是O(1),这只是链表中的元素插入。对于iVoxel-PHC,点存储在由PHC索引进行索引的地图中。因此,在有序数组中插入元素需要时间复杂度O(log(n)),其中n是体素中的平均点数。然而,n通常很小,因为点云是下采样的,这在实践中影响不大。
(2)k-NN 搜索
对于线性iVox,k-NN的时间复杂度为O(n),因为它计算从查询点到体素内每个点的距离。对于iVox-PHC,k-NN的时间复杂度为O(log(n)),因为我们只在一维有序数组中搜索PHC索引。此外,对于曲线阶数为κ的iVox-PHC,内部的最大点数为
(
2
k
)
3
(2^k)^3
(2k)3。在最坏的情况下,iVox-PHC中k-NN的时间复杂度为O(log(
(
2
k
)
3
(2^k)^3
(2k)3))=O(κ)。
请注意,这里讨论的复杂性是由每个体素内的点的数量定义的,而不是整个点云。通常,树状方法倾向于讨论整个云的搜索复杂度,因为树是建立在它之上的。然而,对于基于体素的方法,所有点的数量并不直接影响搜索效率,因为体素指数可以使用恒定的复杂度计算。
五、实验
实验部分主要包含仿真实验和数据集实验。
5.1 仿真实验
仿真实验是在一个随机生成的点云里进行K近邻查找以及新增地图点的实验。我们对比了Kdtree flann, ikd-tree, nanoflann R-tree, faiss-IVF, nmslib几个库。耗时与地图点数的关系图如下:

可以看到iVox在K近邻查找和新增的耗时都是很少的,但它们随地图点数的增长会更快,毕竟单个iVox里的点会变多。顺便说一句,PCL Kdtree的查询速度(这里写的flann)也是杠杠的,只是没有增量接口。
我们也比较了iVox的K近邻质量问题。大部分时候iVox的K近邻不是严格的,因为天然的有范围限制。我们把K近邻的结果与暴力搜索的结果进行比对,可以得到它的召回率(recall)。各算法的召回率与时间曲线如下:
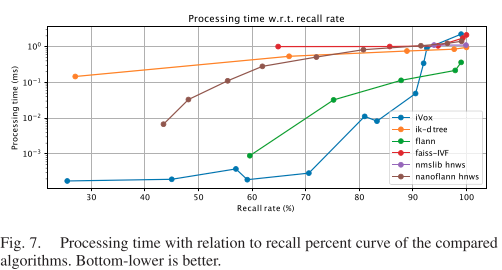
如果要求iVox有很高的召回,那就不得不设置很大的体素尺寸或者很大的搜索近邻,这时候iVox的查找时间会增长很快。不过LIO系统在70%左右的召回率下就能很好地工作,所以实际也没啥大不了的。
5.2 数据集实验
数据集实验主要比较整个LIO系统的耗时和计算精度。由于Faster-LIO框架与FastLIO2基本相同,我们时间上对标的也主要是FastLIO2,其他系统主要是用来做个参考。32线雷达的详细步骤算法耗时如下图所示:
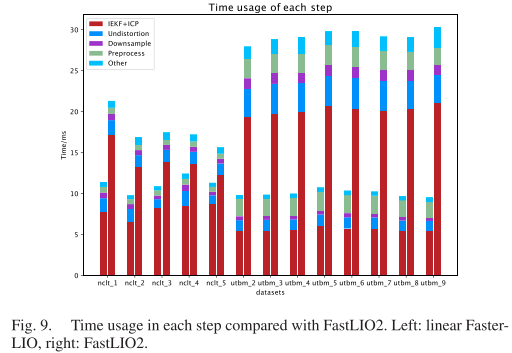
左侧为本文Faster-Lio用时,右侧为Fast-Lio2
可见主要的耗时在IEKF+ICP的迭代过程。使用iVox替代iKd-tree时,我们缩短的也主要是这个过程。UTBM数据集要明显一些,我们可以把差不多20ms的IEKF迭代降到5-8ms左右,整个流程可以从30ms左右降到10ms左右,实现明显的效率提升。
我们也绘制了时间轴上的耗时曲线,如下:
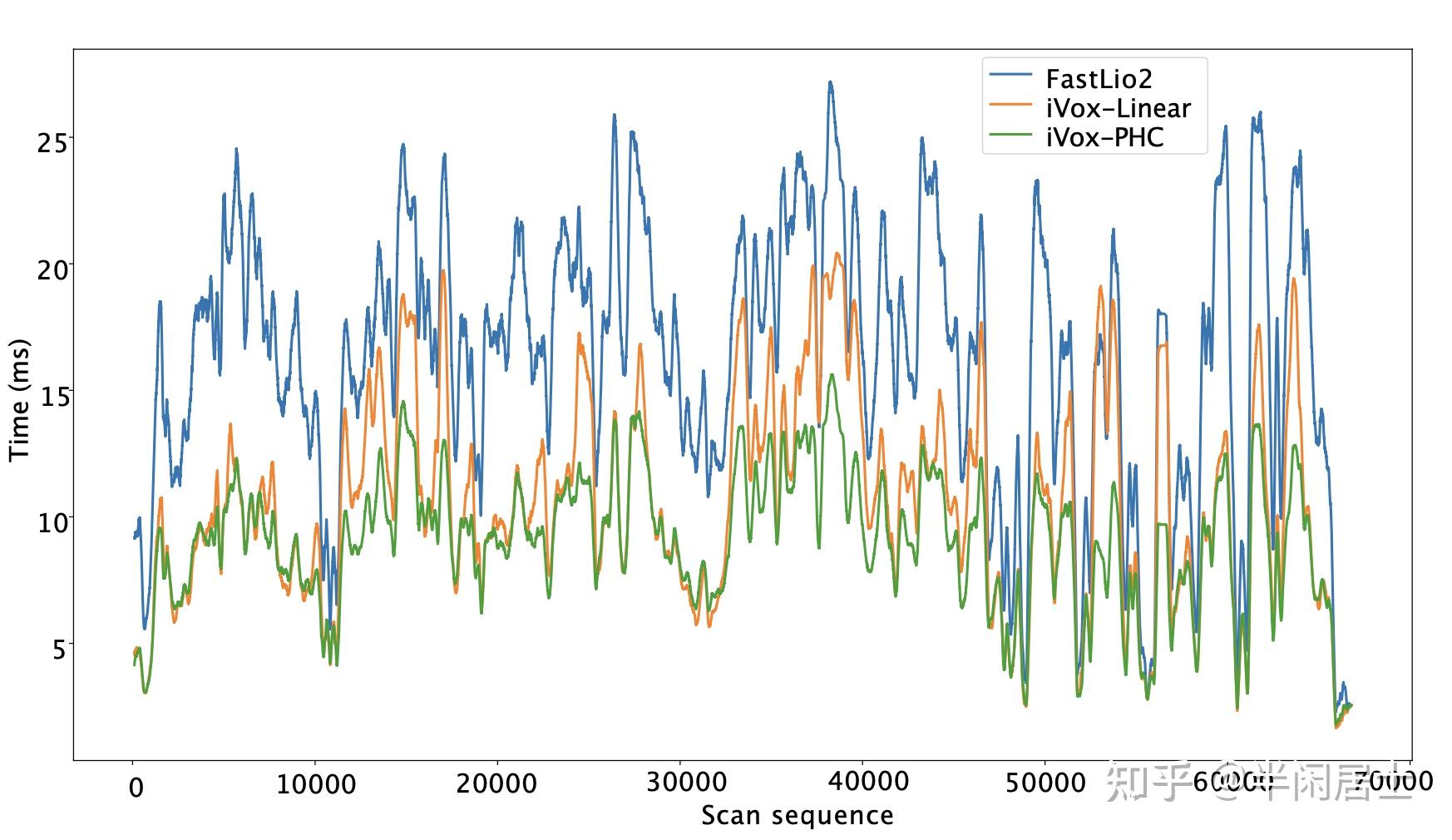
两个版本的LIO的运算效率不会随着时间有明显变化,而FasterLIO要明显用时更低一些。对LIO-SAM、LiLi-OM的一些计算用时指标可以参考论文的表格。
在精度方面,考虑到LIO默认不带回环检测,所以我们主要评价每百米的漂移误差指标(百分比形式),见下表。
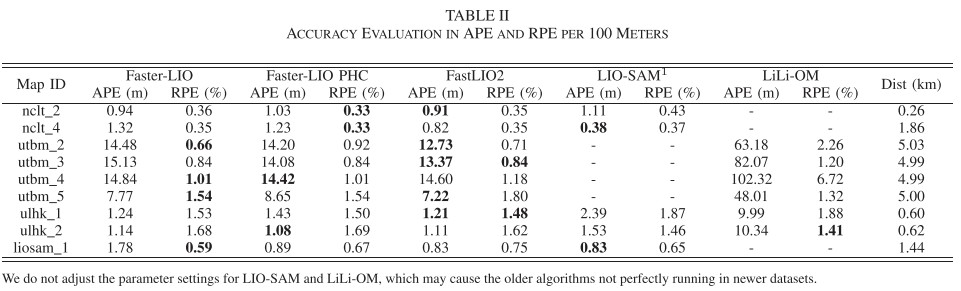
实际上,只要不漂,LIO精度都是差不多的。
iVox也可以被集成到其他LO或LIO里,但是大部分方案里,最近邻并不是主要的计算瓶颈,gtsam/ceres什么的耗时相比最近邻那可太多了。我们也尝试了把iVox集成到Lego-LOAM里,发现主要只是省了增量地图构建那部分时间,优化方面没什么变化(点少)。所以iVox与FastLIO倒是相性更好一些。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 洞察平台团队的8大挑战:探索软件开发背后的秘密
- AI智能配音助手微信小程序前后端源码支持多种声音场景选择
- 深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?
- Jenkins----基于 CentOS 或 Docker 安装部署Jenkins并完成基础配置
- vue3中的一些便捷写法记录
- 常用css
- Linux:centos yum安装指令指南
- 【C++】谈谈深拷贝与浅拷贝
- 词法语法语义分析程序设计及实现,包含出错提示和错误恢复
- Qt 表格相关API