R语言学习case5:NC基于R语言的UpSetR
step1: 安装库
install.packages("UpSetR")
step2:导入包
library(UpSetR)
step3:读取数据
otu_RA <- read.delim('./otu_RA.txt',
header = TRUE, row.names = 1, sep = '\t')
read.delim(): 这是R语言中的一个函数,用于读取文本文件,特别是以制表符分隔的文件。它可以处理包含表格数据的文本文件。
header = TRUE: 这是一个参数,指示文件的第一行包含列名(变量名)。
row.names = 1: 这是另一个参数,指示使用文件中的第一列作为行名。
sep = '\t': 这是指定分隔符的参数,这里使用的是制表符(‘\t’)。
step4:对数据进行操作
otu_RA[otu_RA > 0] <- 1
otu_RA > 0: 这是一个逻辑条件,它生成一个与otu_RA相同大小的布尔型数据框或矩阵,其中元素为TRUE表示对应位置的元素大于0,而FALSE表示小于等于0。
<- 1: 这是将选中的元素的值赋值为1。换句话说,所有在原始数据框或矩阵中大于0的元素都被设置为1。
step5:upset 绘图
plot <- upset(otu_RA, nset = 7, nintersects = 10, order.by = c('degree','freq'), decreasing = c(TRUE, TRUE),
mb.ratio = c(0.7, 0.3),
point.size = 1.8,
line.size = 1,
mainbar.y.label = "Intersection size",
sets.x.label = "Set Size",
main.bar.color = "#2a83a2", sets.bar.color = "#3b7960",
queries = list(list(query = intersects,
params = list("BS","RS","RE","VE","SE","LE","P"),
active = T,color="#d66a35",
query.name = "BS vs RS vs RE vs VE vs SE vs LE vs P")))
upset(): 这是创建UpSet图的函数。
nset = 7: 这是设置的数量,即UpSet图中显示的集合的数量。
nintersects = 10: 这是交集的数量,即显示的交集的数量。
order.by = c('degree','freq'): 这是指定按照哪些标准对集合进行排序,这里使用了两个标准:度(degree)和频率(freq)。
decreasing = c(TRUE, TRUE): 这是指定排序的顺序,这里设置为降序。
mb.ratio = c(0.7, 0.3): 这是主条形图和集合条形图的比例。(上图和下图)
point.size = 1.8: 这是点的大小。
line.size = 1: 这是线的大小。
mainbar.y.label = "Intersection size": 这是主条形图的y轴标签。
sets.x.label = "Set Size": 这是集合条形图的x轴标签。
main.bar.color = "#2a83a2": 这是主条形图的颜色。
sets.bar.color = "#3b7960": 这是集合条形图的颜色。
queries = list(list(query = intersects, params = list("BS","RS","RE","VE","SE","LE","P"), active = T,color="#d66a35", query.name = "BS vs RS vs RE vs VE vs SE vs LE vs P")): 这是用于添加查询的参数,其中指定了一组查询,每个查询包括集合的名称、参数、活动状态和颜色。
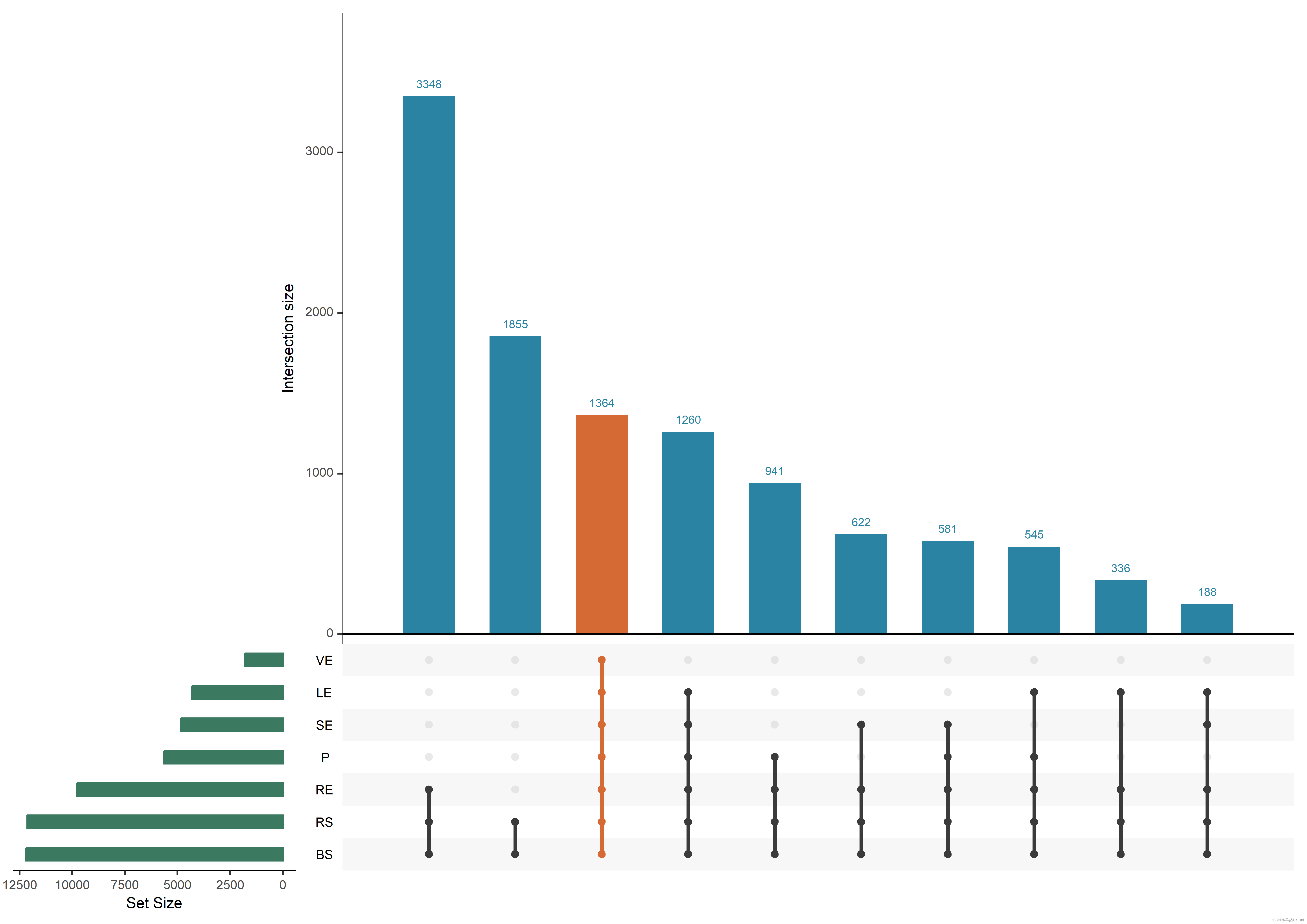
该图解读:c、 垂直条形图显示了植物区室和土壤之间交集的操作分类单元(OTU)数量;水平条形图显示了原数数据OUT总量;线条和圆圈表示在七个隔间之间
重叠的OTU,即,通过点与点之间的连接,对应传统韦恩图中圈与圈的重叠部分。
研究检测到1364个OTU,在所有植物区室和大块土壤中共存,这表明它们有能力适应不同的生态位,甚至可以在植物器官中正常发育(图1c)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 想成为一名C++开发工程师,需要具备哪些条件?
- 广泛关注!多家媒体集中报道 Mo 人工智能平台年终发布会
- C 练习实例23
- 冰箱和小型制冷系统毛细管选型计算软件介绍
- Node.js中的模块,常用模块具体代码示例
- 3.事件处理机制
- 前端歌谣-第七十五课-Koa讲解
- Rancher2部署MySQL无法挂载Longhorn创建的pvc,怎么办?
- jQuery: 整理5---删除元素和遍历元素
- 结构体:修改默认对齐数、结构体传参