基于YOLOv8的学生课堂行为检测,引入BRA注意力和Shape IoU改进提升检测能力
💡💡💡本文摘要:介绍了学生课堂行为检测,并使用YOLOv8进行训练模型,以及引入BRA注意力和最新的Shape IoU提升检测能力
1.SCB介绍

摘要:利用深度学习方法自动检测学生的课堂行为是分析学生课堂表现和提高教学效果的一种很有前途的方法。然而,缺乏关于学生行为的公开数据集给这一领域的研究人员带来了挑战。为了解决这个问题,我们提出了学生课堂行为数据集(SCB-dataset3),它代表了现实生活中的场景。我们的数据集包括5686张图像,45578个标签,重点关注六种行为:举手、阅读、写作、使用电话、低头和俯身在桌子上。我们使用YOLOv5、YOLOv7和YOLOv8算法对数据集进行评估,平均精度(map)高达80.3%。我们相信我们的数据集可以作为未来学生行为检测研究的坚实基础,并有助于该领域的进步。
在本研究中,我们对之前的工作进行了迭代优化,以进一步扩展scb数据集。最初,我们只关注学生举手的行为,但现在我们已经扩展到六种行为:举手,阅读,写作,使用电话,低头,靠在桌子上。通过这项工作,我们进一步解决了课堂教学场景中学生行为检测的研究空白。我们进行了广泛的数据统计和基准测试,以确保数据集的质量,提供可靠的训练数据。
我们的主要贡献如下:
1. ? ?我们已经将scb数据集更新到第三个版本(SCB-Dataset3),增加了6个行为类别。该数据集共包含5686张图像和45578个注释。它涵盖了从幼儿园到大学的不同场景。
2. ? ?我们对SCBDataset3进行了广泛的基准测试,为今后的研究提供了坚实的基础。
3. ? ?对于SCB-Dataset3中的大学场景数据,我们采用了“帧插值”方法并进行了实验验证。结果表明,该方法显著提高了行为检测的准确率。
4. ? ?我们提出了一种新的度量标准——行为相似指数(BSI),用来衡量网络模型下不同行为之间在形式上的相似性。


学生课堂行为不同数据集如下:
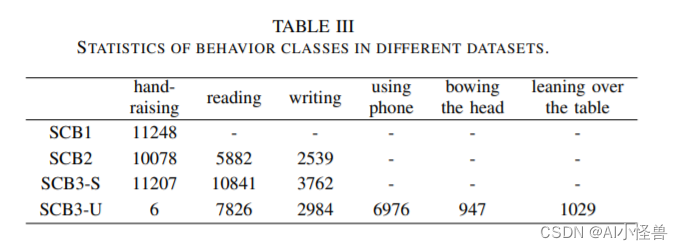 ?不同YOLO模型性能如下:
?不同YOLO模型性能如下:

2.如何提高YOLOv8课堂行为检测能力
通过加入Biformer中的注意力机制和多种IoU优化方法
?2.1??Biformer介绍
Yolov8 引入CVPR 2023 BiFormer: 基于动态稀疏注意力构建高效金字塔网络架构,对小目标涨点明显_biformer复现-CSDN博客
?
论文:https://arxiv.org/pdf/2303.08810.pdf
背景:注意力机制是Vision Transformer的核心构建模块之一,可以捕捉长程依赖关系。然而,由于需要计算所有空间位置之间的成对令牌交互,这种强大的功能会带来巨大的计算负担和内存开销。为了减轻这个问题,一系列工作尝试通过引入手工制作和内容无关的稀疏性到关注力中来解决这个问题,如限制关注操作在局部窗口、轴向条纹或扩张窗口内。
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
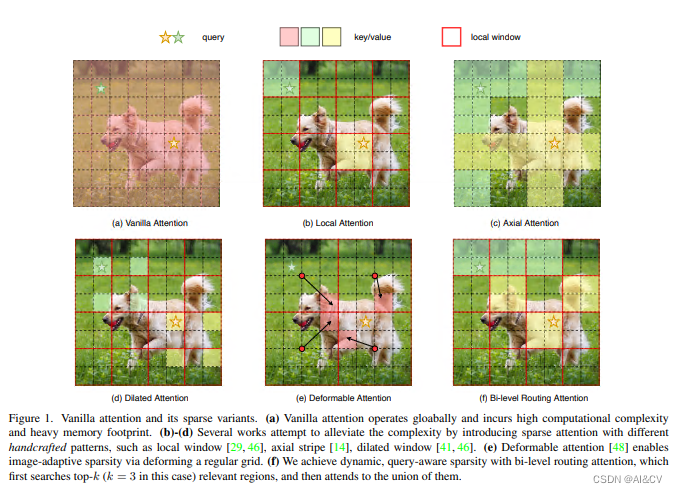
?其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention?),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。

YOLOv8-BRA结构图
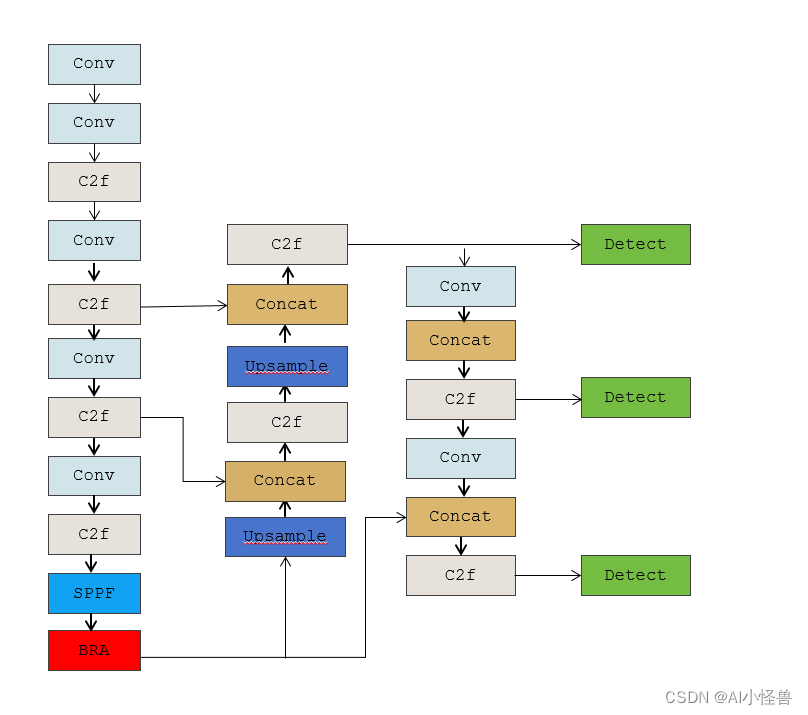
yolov8-bra.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, BiLevelRoutingAttention, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.2 Shape-IoU介绍

论文:https://arxiv.org/pdf/2312.17663.pdf?
源码博客:YOLOv8独家原创改进:提出一种新的Shape IoU,更加关注边界框本身的形状和尺度,对小目标检测也很友好 | 2023.12.29收录_shape_iou yolov8-CSDN博客?
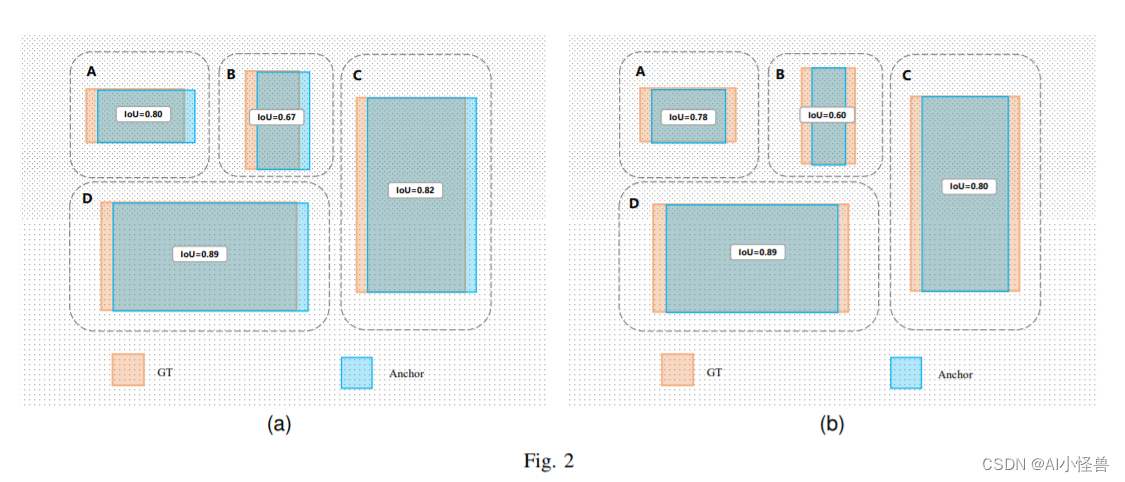
?摘要:边界盒回归损失作为检测器定位分支的重要组成部分,在目标检测任务中起着重要的作用。现有的边界盒回归方法通常考虑GT盒与预测盒之间的几何关系,利用边界盒的相对位置和形状来计算损失,而忽略了边界盒的形状和规模等固有属性对边界盒回归的影响。为了弥补已有研究的不足,本文提出了一种关注边界盒本身形状和尺度的边界盒回归方法。首先,我们分析了边界框的回归特征,发现边界框本身的形状和尺度因素都会对回归结果产生影响。基于以上结论,我们提出了Shape IoU方法,该方法可以通过关注边界框本身的形状和尺度来计算损失,从而使边界框回归更加准确。最后,我们通过大量的对比实验验证了我们的方法,结果表明,我们的方法可以有效地提高检测性能,并且优于现有的方法,在不同的检测任务中达到了最先进的性能。
本文贡献:
1.我们分析了边界盒回归的特点,得出边界盒回归过程中,边界盒回归样本本身的形状和尺度因素都会对回归结果产生影响。
2.在已有的边界盒回归损失函数的基础上,考虑到边界盒回归样本本身的形状和尺度对边界盒回归的影响,提出了shape- iou损失函数,针对微小目标检测任务提出了 the shape-dotdistance and shape-nwd loss
3.我们使用最先进的单级探测器对不同的检测任务进行了一系列的对比实验,实验结果证明本文方法的检测效果优于现有的方法来实现sota。
3.源码获取方式
私信获取源码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- VN网络接口卡(同步线、同步盒子、配套线束)
- HCIA——25FTP 的工作原理、功能、TFTP、控制连接、数据连接的选择、解答
- “寻龙量化”,寻龙诀AI量化系统套装,实时监测游资与主力资金动向
- 虾皮跨境电商物流:打造高效便捷的全球供应链解决方案
- Blockchain-APTrace-Fabric-master农产品溯源开源项目详解
- Improve Coding with Enhanced C# 12 Support
- 知虾大数据Shopee平台有:为什么它对用户和卖家都如此重要?
- 项目经理和产品经理的区别,如何判断自己适合哪个,从事该岗位前期需做的准备(学习技能考、哪些证书)?
- 只有可复制的生意才能做大,2024靠谱创业项目推荐!
- k8s---ingress对外服务(七层)