简易机器学习笔记(六)不同优化算法器
前言
我们之前不是说了有关梯度下降公式的事嘛,就是那个

这样梯度下降公式涉及两个问题,一是梯度下降的策略,二是涉及到参数的选择,如果我们选择固定步长的时候,就会发现我们求的值一直在最小值左右震荡,很难选择到我们期望的值。
假设上图中,x0为我们期望的极小值,yB = xA - yA’xA的时候,xB实际上蹿到了极小值的右侧去了,当我们yC = xB - yB’xB的时候,我们求的yC又跑到极小值的左边去了,反正就是一直会在极小值x0附近震荡。
这时候我们有几种常见的优化算法,这也是我们在之前的代码中看到的SGD(随机梯度下降)优化器的由来。
来自Paddlepaddle的官方文档,图示如下:
- SGD(随机梯度下降)

- Momentum
引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。

每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
- AdaGrad
根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
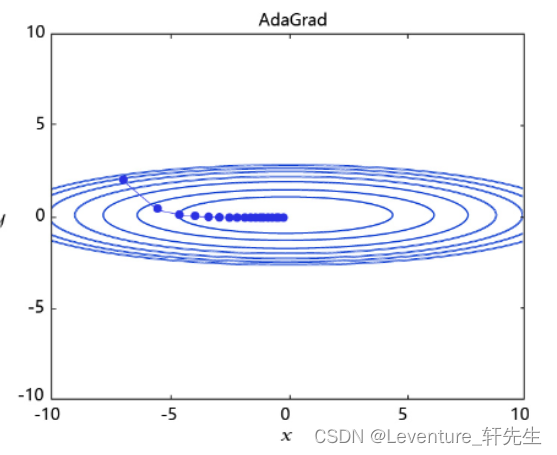
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,学习率随着梯度变化而适应,解决AdaGrad学习率急剧下降的问题。
- Adam

由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
很显然,除开我们常用的随机梯度下降方法,每种优化的方式都有自己的优势。这主要看目标场景和数据集类型和数值的好坏。
实际代码
实际上在开发中,在Paddlepaddle库只需要修改优化器的选型即可,库本身已经做好了这些方案的分装
#仅优化算法的设置有所差别
def train(model):
model.train()
#调用加载数据的函数
train_loader = load_data('train')
#四种优化算法的设置方案,可以逐一尝试效果
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# opt = paddle.optimizer.Momentum(learning_rate=0.01, momentum=0.9, parameters=model.parameters())
# opt = paddle.optimizer.Adagrad(learning_rate=0.01, parameters=model.parameters())
# opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 3
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
#前向计算的过程
predicts = model(images)
#计算损失,取一个批次样本损失的平均值
loss = F.cross_entropy(predicts, labels)
avg_loss = paddle.mean(loss)
#每训练了100批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
# 最小化loss,更新参数
opt.step()
# 清除梯度
opt.clear_grad()
#保存模型参数
paddle.save(model.state_dict(), 'mnist.pdparams')
#创建模型
model = MNIST()
#启动训练过程
train(model)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- OpenHarmony之HDF驱动框架
- kotlin Kmp多平台模板生成
- JAVA主流日志框架梳理学习及使用
- elasticsearch|大数据|低版本的elasticsearch集群的官方安全插件x-pack的详解
- 纯前端 —— 200行JS代码、实现导出Excel、支持DIY样式,纵横合并
- 人工智能-机器学习-深度学习-分类与算法梳理
- 【Xcode】解决Unable to process request - PLA Update available
- echarts柱状图加单位,底部文本溢出展示
- 【精通C语言】:深入解析C语言中的while循环
- JG/T 571-2019 玻纤增强聚氨酯节能门窗检测