linux内存寻址原来那么简单
内存寻址
内存寻址听起来高大上,其实真实处理起来很简单,以常见的80x86架构为例,有三种不同的地址:
- 逻辑地址
- 线性地址
- 物理地址

内存控制单元(MMU)通过分段单元的硬件电路把一个逻辑地址转化为线性地址,通过分页单元的硬件电路把线性地址转换为一个物理地址,如上图。
逻辑地址(logical address) : 用来指定一个操作数或一条指令的地址。每一个逻辑地址都由一个段和偏移量组成,偏移量指明了从段开始的地方到实际地址之间的距离。
线性地址(linear address)也常被称为虚拟地址 : 是一个32位的无符号整数,取值范围0x00000000 - 0xffffffff
物理地址(physical address) : 内存芯片级内存单元寻址。
饭要一口一口吃,路要一步一步走,通过以上介绍我们明白了三种地址之间的关系,接下来我们分步拆解地址转换的过程:
分段单元(Segmentation Uint)
通过地址转换关系一图,我们可以知道逻辑地址需要通过分段单元才能转换为线性地址(linear address)。下图就是分段单元的实现:
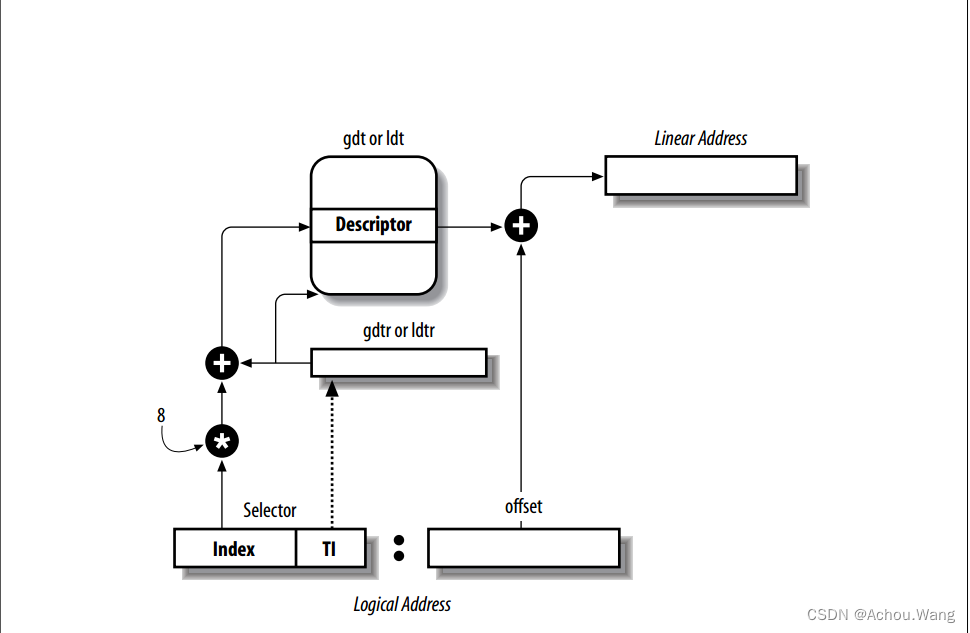
逻辑地址并不是真正的地址,它由段和偏移量组成。 想要得到段,我们首先要知道段是什么段又在哪?
段是代码段、数据段、栈段,按照是否是内核态,又可以分为内核代码段、内核数据段、内核栈段,用户代码段、用户数据段、用户栈段,图中给出的Selector就是用来确定使用哪个段的。
Selector又称为段选择符,或者段选择器,我更倾向于称其为段选择器,段选择器的实现如下图:

段选择器由三部分组成:
- index - 索引号
- TI - 表指示器
- RPL - 请求者特权级别
从图中我们能够看出,Index乘以8能定位出Descriptor中的段描述符,TI(Table indicator)指示出是gdt还是在ldt中,TI=0说明段描述符在gdt中,TI=1说明段描述符在ldt中。
那问题来了,段选择器又是从哪里来的,我们编程通常接触不到这些,就算是看汇编也只接触到一些寄存器就结束了,因此为了程序能够控制段选择器,处理器提供了段寄存器,顾名思义,段寄存器就是用来存放段选择符(器)的地方,常见的有cs,ss,ds,es,fs和gs,其中有三个有专门的用途:
- cs - 代码段寄存器
- ss - 栈段寄存器
- ds - 数据段寄存器
**注意:**cs寄存器中包含一个两位的字段,用以指名CPU当前的特权级别(Current privilege level, CPL),该字段只有两个值0和3,0代表最高优先级,3代表最低优先级。
段描述符的大小为8字节,因此、通过index * 8能定位出段描述符的偏移量,TI的值指示出应该去gdtr还是去ldtr寄存器中取值。
![.段描述符
image::image-2023-12-23-21-59-35-245.png[]](https://img-blog.csdnimg.cn/direct/2076c5c82d5747979a6471ccc291d327.png)
如何计算出段描述符地址?
通过分段单元的图我们可以看到,index * 8 + (TI指定的描述表)就能得到段描述符的地址。
因此,如果TI=0,GDT在0x00020000(这个值保存在gdtr寄存器中),index的值为2,那么短描述符地址就是 2 * 8 + 0x00020000 = 0x00020010
如何计算出线性地址?
从段描述符一图中,我们看到很多部分,我们在计算线性地址之前需要先了解一下该部分的组成:
| 字段名 | 描述 |
|---|---|
| Base | 指向段首字节的线性地址 |
| G | 粒度标识,0代表以字节为单位,否则以4096字节为的倍数单位 |
| Limit | 存放段中最后一个内存单元的偏移量,从而决定段的长度 |
| S | 0 代表系统段,存储诸如LDT这种关键数据结构,否则它是一个普通的代码段或数据段 |
| Type | 段的特征 |
| DPL | 描述符特权级别 |
| P | 是否在主存中 |
| D或B | 取决于是代码段还是数据段 |
![.段描述符各个字段的含义
image::image-2023-12-23-22-37-31-014.png[]](https://img-blog.csdnimg.cn/direct/41e59e1326b447cfbcf367e0fa772f7e.png)
搞明白以上关系之后我们就可以轻松的计算出线性地址了,线性地址就是逻辑地址的偏移量(offset)和段描述符Base字段相加的值。
以上就是通过分段单元实现的逻辑地址->线性地址的转换
分页单元(paging unit)
相对于分段单元,分页单元复杂许多,但是说起来又简单许多,为什么这样说呢?因为分段主要靠硬件,而分页主要靠软件。
分页单元就是把线性地址转换为物理地址,其中最主要的一个任务就是把锁请求的访问类型与线性地址的访问权限相比较,如果这次的访问权限是无效的就产生一个缺页异常。
线性地址被分为固定长度为单位的组,称为页。页内部连续的线性地址会被映射到物理地址上。
以一种常见的页划分为例,32位的线性地址会被分为3个域:
- Directory(目录) - 10位
- Table(页表) - 10位
- Offset(偏移量) - 12位
真在使用的页目录的物理地址存放在控制寄存器cr3中,其常见组成形式可以用如下如表示:
![.paging 80x86 processors
image::image-2023-12-24-15-59-48-992.png[]](https://img-blog.csdnimg.cn/direct/da776ee46e2e4b93adfa2a986643e96a.png)
这种形式的目录结构寻址能力可以高达 1024 * 1024 * 4096 = 232
在linux上为了应对64位系统对内存的需求,使用了更多级的目录来进行内存的分页,其分页形式为:
- 页全局目录(Page Global Directory)
- 页上级目录(Page Upper Directory)
- 页中间目录(Page Middle Directory)
- 页表(Page Table)
其组成形式如图所示:
![.Linux paging model
image::image-2023-12-24-16-05-50-650.png[]](https://img-blog.csdnimg.cn/direct/4289c2efbc124e839c9ad67cf72de7d2.png)
以上就是计算机进行内存寻址的全过程,当然分页单元的过程主要是软件实现的,这里没有对linux的实现接口进行说明,如果感兴趣的可以下载linux 2.6版本查看,虽然新版本的linux分页单元有改动,但是还是推荐你看下2.6版本的,这个版本的功能实现更加的纯粹,也更容易理解。
文章以使用asciidoc形式上传到github上,需要的可以自行下载
https://github.com/zzu-andrew/note_book
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【更新】cyのMemo(20231231~)
- pytorch基础(十)-dropout
- 数据结构之<树>的介绍
- 健康成长的基石:新生儿补充镁的关键
- MySQL中的时间函数整理汇总
- web前端javaScript笔记——(4)方法
- 常用界面设计组件 —— 按钮组件、布局组件
- 【PWN】学习笔记(三)【返回导向编程】(中)
- Maven工程继承和聚合关系
- redis哨兵+redis主从复制(在虚拟机centos的docker下)