翻译: LLM构建 GitHub 提交记录的聊天机器人二 使用 Timescale Vector、pgvector 和 LlamaIndex
接着上篇内容:翻译: LLM构建 GitHub 提交记录的聊天机器人一 使用 Timescale Vector、pgvector 和 LlamaIndex
TSV Time Machine 示例应用有三个页面:
- Home主页:提供应用程序使用说明的应用程序主页。
- Load Data加载数据:页面以加载所选存储库的 Git 提交历史记录。
- Time Machine Demo:与加载的任何 GitHub 存储库聊天的界面。
由于该应用程序是 ~600 行代码,我们不会逐行解压(尽管您可以要求 ChatGPT 向您解释任何棘手的部分!让我们看一下其中涉及的关键代码片段:
- 从要与之聊天的 GitHub 存储库加载数据
- 通过时间感知检索time-aware retrieval augmented generation增强聊天效果
第 1 部分:使用 Timescale Vector 和 LlamaIndex 加载基于时间的数据
输入要为其加载数据的 GitHub 存储库的 URL,TSV Time Machine 使用 LlamaIndex 加载数据,为其创建向量嵌入,并将其存储在 Timescale Vector 中。

在文件0_LoadData.py中,我们从您选择的 GitHub 存储库中获取数据,使用 OpenAI 的 text-embedding-ada-002 模型和 LlamaIndex 为其创建嵌入,并将其存储在 Timescale Vector 的表中。这些表包含与 Git 提交关联的向量嵌入、原始文本和元数据,包括反映提交时间戳的 UUID。
首先,我们定义一个 load_git_history() 函数。此函数将要求用户输入 GitHub 存储库 URL、分支和提交数,以通过 st.text_input 元素加载。然后它将获取存储库的 Git 提交历史记录,使用 LlamaIndex 嵌入提交历史记录文本并将它们转换为 LlamaIndex 节点,并将嵌入和元数据插入到 Timescale Vector 中:
s, and insert the embeddings and metadata into Timescale Vector:
首先,我们定义一个 load_git_history() 函数。此函数将要求用户输入 GitHub 存储库 URL、分支和提交数,以通过 st.text_input 元素加载。然后它将获取存储库的 Git 提交历史记录,使用 LlamaIndex 嵌入提交历史记录文本并将它们转换为 LlamaIndex 节点,并将嵌入和元数据插入到 Timescale Vector 中:
# Load git history into the database using LlamaIndex
def load_git_history():
repo = st.text_input("Repo", "<https://github.com/postgres/postgres>")
branch = st.text_input("Branch", "master")
limit = int(st.text_input("Limit number commits (0 for no limit)", "1000"))
if st.button("Load data into the database"):
df = get_history(repo, branch, limit)
table_name = record_catalog_info(repo)
load_into_db(table_name, df)
用于从用户定义的 URL 加载 Git 历史记录的函数。默认为 PostgreSQL 项目。
虽然帮助程序函数 get_history(),record_catalog_info() 和 load_into_db() 的完整代码位于示例应用存储库中,但下面是概述:
get_history():获取存储库的 Git 历史记录并将其存储在 Pandas DataFrame 中。我们获取提交哈希、作者姓名、提交日期和提交消息。record_catalog_info():在我们的 Timescale Vector 数据库中创建一个关系表,用于存储已加载的 GitHub 存储库的信息。存储库 URL 和表提交的名称存储在数据库中。load_into_db():在 LlamaIndex 中创建一个 TimescaleVectorStore,用于存储提交数据的嵌入和元数据。- 我们将time_partition_interval参数设置为 365 天。此参数表示按时间对数据进行分区的每个间隔的长度。每个分区将包含指定时间长度的数据。
# Create Timescale Vectorstore with partition interval of 1 year
ts_vector_store = TimescaleVectorStore.from_params(
service_url=st.secrets["TIMESCALE_SERVICE_URL"],
table_name=table_name,
time_partition_interval=timedelta(days=365),
)
💡选择正确的分区间隔
此示例使用 365 天作为分区间隔,但选择对应用查询有意义的值。
例如,如果您经常查询最近的向量,使用较小的时间间隔(例如一天)。如果查询十年内向量,请使用更大的时间间隔(例如六个月或一年)。
大多数查询应该只涉及几个分区,而整个数据集应该适合 1,000 个分区。
创建 TimescaleVectorStore 后,我们为每个提交创建 LlamaIndex TextNodes,并批量为每个节点的内容创建嵌入。
create_uuid() 从与节点和向量嵌入关联的提交datetime创建一个 UUID v1。这个 UUID 使我们能够按时间有效地将节点存储在分区中,并根据其分区查询嵌入。
# Create UUID based on time
def create_uuid(date_string: str):
datetime_obj = datetime.fromisoformat(date_string)
uuid = client.uuid_from_time(datetime_obj)
return str(uuid)
创建带有时间组件的 UUID v1 有助于按时间进行相似性搜索。我们使用 Timescale Vector Python 客户端中的 uuid_from_time() 函数来帮助我们。
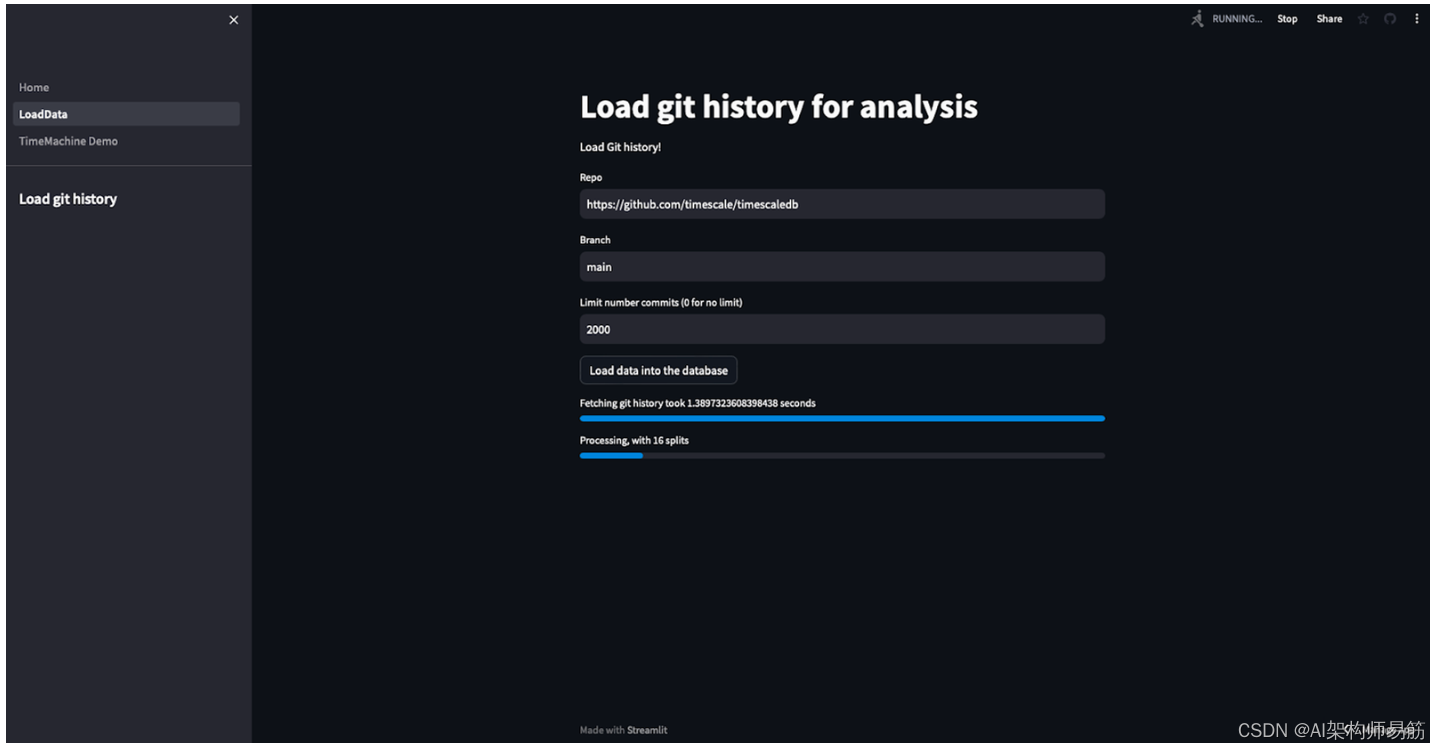
“加载数据”页面显示从用户指定的 GitHub URL 加载和矢量化数据的进度。
最后,我们创建一个 TimescaleVectorIndex,这将允许我们对时间感知 RAG 进行快速相似性搜索和基于时间的搜索。我们使用 st.spinner 和 st.progress 来显示加载进度。
st.spinner("Creating the index...")
progress = st.progress(0, "Creating the index")
start = time.time()
ts_vector_store.create_index()
duration = time.time()-start
progress.progress(100, f"Creating the index took {duration} seconds")
st.success("Done")
2. 第 2 部分:构建聊天机器人
在文件1_TimeMachineDemo.py中,我们使用 LlamaIndex 的自动检索器通过从 Timescale Vector 获取数据来回答用户问题,以用作 GPT-4 的上下文。
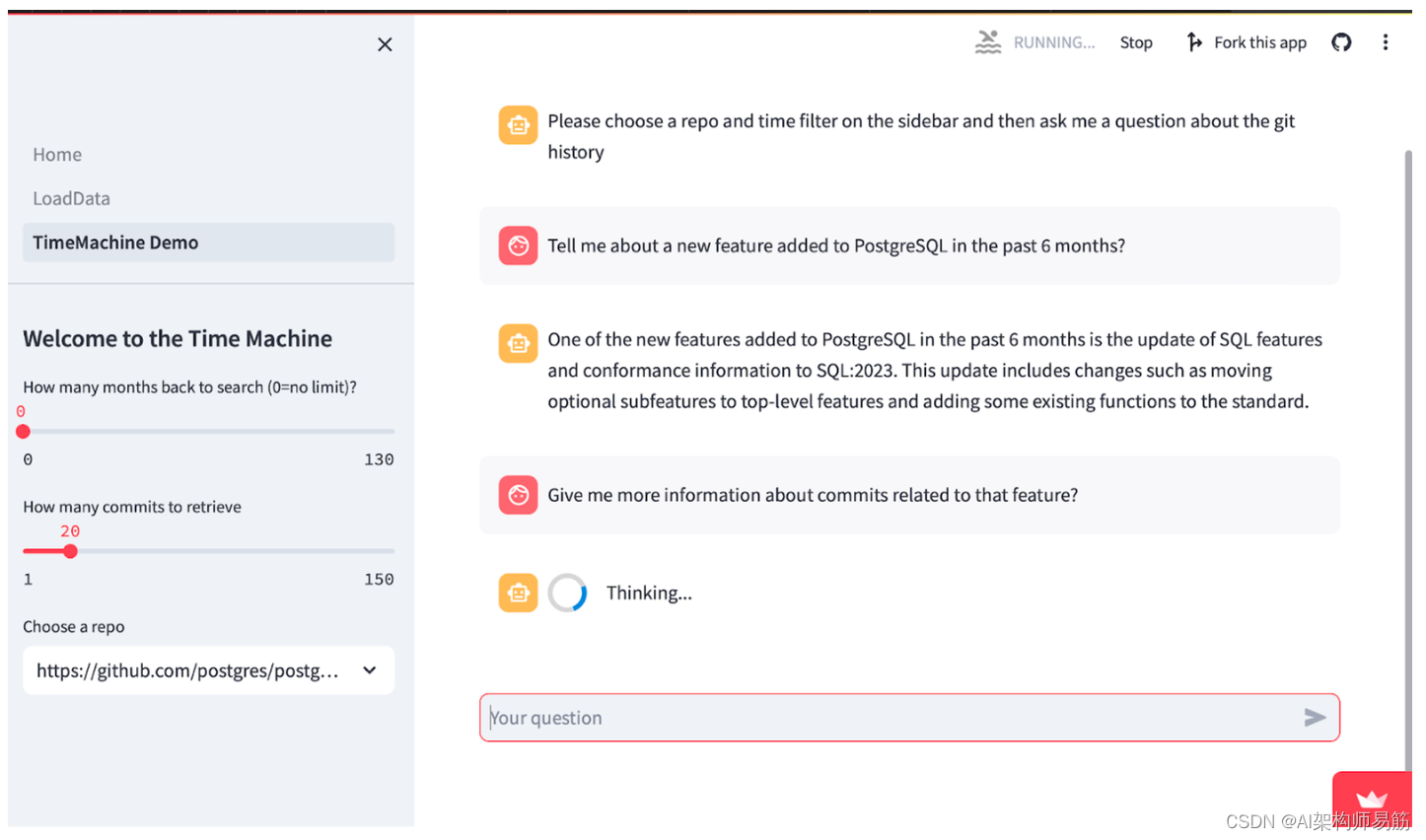
Time Machine 演示页面显示示例用户对话。以下是主要功能的概述:
-
get_repos():获取已加载的可用 GitHub 存储库列表,你可以与之聊天,因此你可以在侧边栏中轻松地在它们之间切换。 -
get_autoretriever():从 TimescaleVectorStore 创建一个 LlamaIndex 自动检索器,这使 GPT-4 能够使用元数据过滤器形成矢量存储查询。这使 LLM 能够将用户查询的答案限制在特定的时间范围内。 -
例如,查询:“过去 6 个月发布了哪些新功能”将仅搜索 Timescale Vector 中包含现在到 6 个月前数据的分区,并获取最相关的向量用作 RAG 的上下文。
# Creates a LlamaIndex auto-retriever interface with the TimescaleVector database
def get_auto_retriever(index, retriever_args):
vector_store_info = VectorStoreInfo(
# Note: Modify this to match the metadata of your data
content_info="Description of the commits to PostgreSQL. Describes changes made to Postgres",
metadata_info=[
MetadataInfo(
name="commit_hash",
type="str",
description="Commit Hash",
),
MetadataInfo(
name="author",
type="str",
description="Author of the commit",
),
MetadataInfo(
name="__start_date",
type="datetime in iso format",
description="All results will be after this datetime",
),
MetadataInfo(
name="__end_date",
type="datetime in iso format",
description="All results will be before this datetime",
)
],
)
retriever = VectorIndexAutoRetriever(index,
vector_store_info=vector_store_info,
service_context=index.service_context,
**retriever_args)
# build query engine
query_engine = RetrieverQueryEngine.from_args(
retriever=retriever, service_context=index.service_context
)
# convert query engine to tool
query_engine_tool = QueryEngineTool.from_defaults(query_engine=query_engine)
chat_engine = OpenAIAgent.from_tools(
tools=[query_engine_tool],
llm=index.service_context.llm,
verbose=True,
service_context=index.service_context
)
return chat_engine
vector_store_info为 LLM 提供有关元数据的信息,以便它可以创建有效的过滤器来获取数据以响应用户问题。如果您使用自己的数据(与 Git 提交历史记录不同),则需要修改此方法以匹配您的元数据。__start_date和__end_date是 Timescale Vector 用于支持基于时间的搜索的特殊过滤器名称。如果您在 Timescale Vector 中启用了时间分区(通过在创建 TimescaleVectorStore 时指定time_partition_interval参数),则可以在VectorStoreInfo中指定这些字段,以使 LLM 能够执行对每个 LlamaIndex 节点的 UUID 进行基于时间的搜索。- 返回的
chat_engine是一个 OpenAIAgent,它可以使用 QueryEngine 工具来执行任务 - 在本例中,回答有关 GitHub 存储库提交的问题。 tm_demo()处理用户和LLM之间的聊天交互。它提供了一个st.slider元素,供用户指定要获取的时间段和提交次数。然后,它提示用户输入,使用get_autoretriever()处理输入,并显示聊天消息。在 GitHub 存储库 中查看此方法。
3. Deployment部署
3.1 ?? 在 Streamlit 社区云上
- Fork and clone this repository.
- 使用 Timescale Vector 创建新的云 PostgreSQL 数据库(在此处注册帐户)。下载包含数据库连接字符串的备忘单或
.env文件。 - 创建一个新的 OpenAI API 密钥以在此项目中使用,或者按照这些说明注册 OpenAI 开发者帐户以获取一个密钥。我们将使用 OpenAI 的嵌入模型来生成文本嵌入,并使用 GPT-4 作为 LLM 来为我们的聊天引擎提供支持。
- 在 Streamlit 社区云 中:
- 点击
New app,然后选择适当的存储库、分支和文件路径。 - 单击
Advanced Settings并设置以下配置:
OPENAI_API_KEY=”YOUR_OPENAI_API KEY”
TIMESCALE_SERVICE_URL=”YOUR_TIMESCALE_SERVICE_URL”
ENABLE_LOAD=1
点击Deploy
3.2 💻 在您的本地计算机上
- 为您的项目创建一个新文件夹,然后按照上面的步骤 1-3 进行操作。
- 安装依赖项。导航到
tsv-timemachine目录并在终端中运行以下命令,这将安装所需的 python 库:
pip install -r requirements.txt
- 在
tsv-timemachine目录中,创建一个新的.streamlit文件夹并创建一个secrets.toml文件,其中包含以下内容:
OPENAI_API_KEY=”YOUR_OPENAI_API KEY”
TIMESCALE_SERVICE_URL=”YOUR_TIMESCALE_SERVICE_URL”
ENABLE_LOAD=1
包含 Streamlit 机密的 TOML 文件示例。您需要使用 OpenAI 和 Timescale Vector 设置这些来嵌入和存储数据。
- 要在本地运行应用程序,请在命令行中输入以下内容:
streamlit run Home.py
🎉恭喜! 现在,您可以使用 LlamaIndex 作为数据框架,使用 Timescale Vector 作为向量数据库,加载任何存储库的 Git 提交历史记录并与之聊天。
Git 提交历史记录可以替换您选择的任何基于时间的数据。其结果是一个应用程序可以有效地对基于时间的数据执行 RAG,并使用特定时间段的数据回答用户问题。
4. 您将如何使用基于时间的检索time-based retrieval ?
基于上面的示例,以下是时间感知 RAG 解锁的一些用例示例:
- 时间范围内的相似性搜索:在与文档语料库聊天时按创建日期、发布日期或更新日期过滤文档。
- 查找最新的嵌入:查找有关特定主题的最相关和最新的新闻或社交媒体帖子。
- 让LLMs思考的时间:利用 LangChain’s self-query retriever或LlamaIndex’s auto-retriever 等工具来询问基于时间和语义的问题文档知识库。
- 搜索和检索聊天历史记录:搜索用户之前的对话以检索与当前聊天相关的详细信息。
5. 总结
您了解到,时间感知 RAG 对于构建处理基于时间的数据的强大 LLM 应用程序至关重要。您还使用 Timescale Vector 和 LlamaIndex 构建基于时间的 RAG 管道,从而生成一个能够回答有关 GitHub 提交历史记录或任何其他基于时间的知识库的问题的 Streamlit 聊天机器人。
参考
https://blog.streamlit.io/using-time-based-rag-llm-apps-with-timescale-vector/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!