7个必知必会的Python技巧
大家好,Python是数据科学领域最广泛使用的编程语言之一,其受欢迎程度与日俱增。近年来,数据科学领域本身已经得到了迅猛的发展,因此学习Python和机器学习是必要的。本文将介绍一些隐藏的Python技巧。
下面与大家分享七个Python技巧,这些技巧不仅可以加强Python技能,还可以提高工作效率,发现合适的Python库简化开发过程。
1.将图像轻松转换为LaTeX代码
有这样一个名为Pix2TeX的Python库,可以将带有方程式的图像神奇地转换为LaTeX代码。这可以轻松地将一个文档中的方程式整合到另一个文档中,甚至不需要从头开始重新创建。
可以使用pip安装该库:pip install pix2tex[gui]
下面来看一个示例:
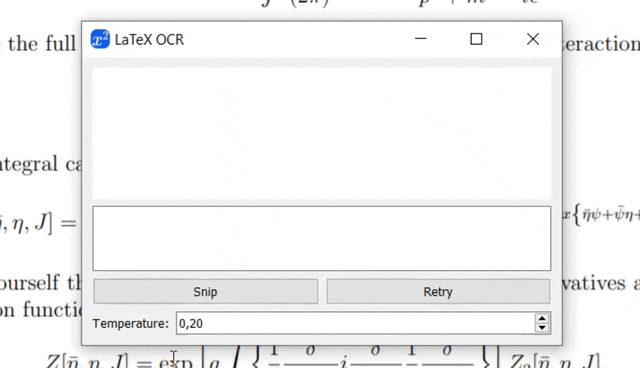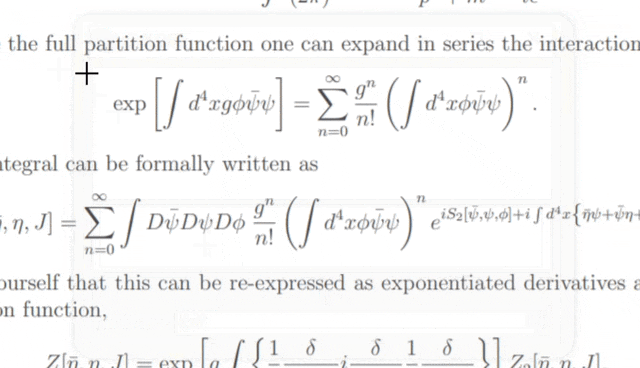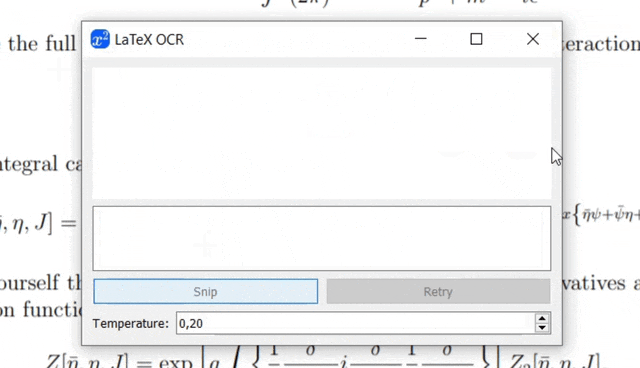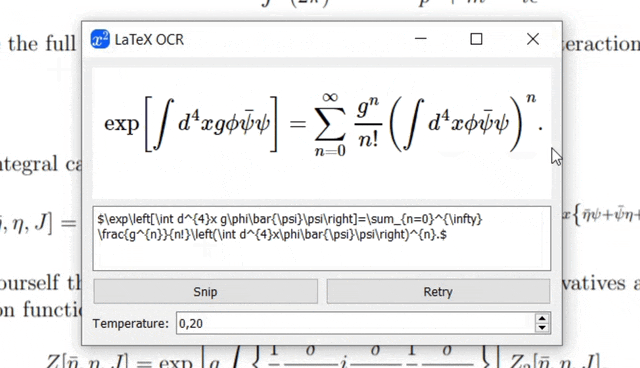
运行Pix2TeX的实际效果(Gif由pix2tex提供)
这个软件包大大简化了论文或科学论文的编写过程。而且最重要的是,它完全免费。
2.自动删除未使用的Python代码
这个技巧可以使源代码更加简洁,众所周知,在大型软件项目中存在着大量未使用的代码。未使用的Python代码可能会导致以下几个问题:
-
浪费内存和资源
-
使代码难以理解
-
测试和调试代码时遇到困难
有趣的是,有一个名为vulture的工具可以帮助开发者自动删除未使用的Python代码。
可以使用pip安装该库:pip install vulture
如下所示,可以看到一个示例:
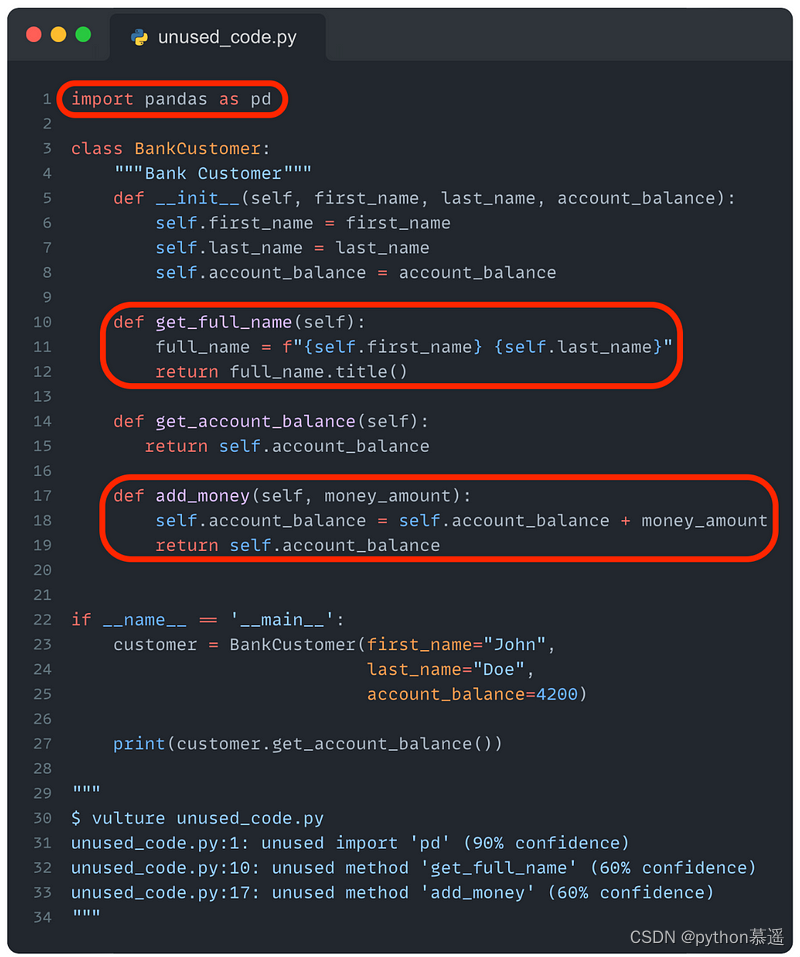
识别未使用的代码
该代码表示一个银行客户,首先导入pandas,然后定义客户类。在主函数中,创建一个客户对象,然后输出客户的账户余额。
之后使用vulture软件包运行了脚本,该工具返回当前未使用的所有代码部分(标为红色)。使用这个工具,可以非常轻松地清理代码。
3.保护敏感信息的最佳实践
另一个重要技巧——将敏感信息保存在.env文件中,然后使用Python包python-dotenv将其加载到Python脚本中,这始终是一个明智的做法。
这样,就可以确保重要数据的安全,不会因意外而出现在代码库或版本控制系统中。
可以使用pip安装该库:pip install python-dotenv
如下所示,可以看到如何使用该包:

保护敏感信息
该代码从本地的.env文件中加载OpenAI API密钥。
所有开发者都应遵循此过程,以避免因信息泄露而造成不必要的损失。
4.使用Rocketry调度Python函数
为了使用易于理解和可定制的调度语句来调度Python函数,可以使用Rocketry。与其他工具不同,Rocketry对项目结构不做任何假设。它非常适用于快速高效的自动化项目。
可以使用pip安装该库:pip install rocketry
以下代码展示了如何使用该库:
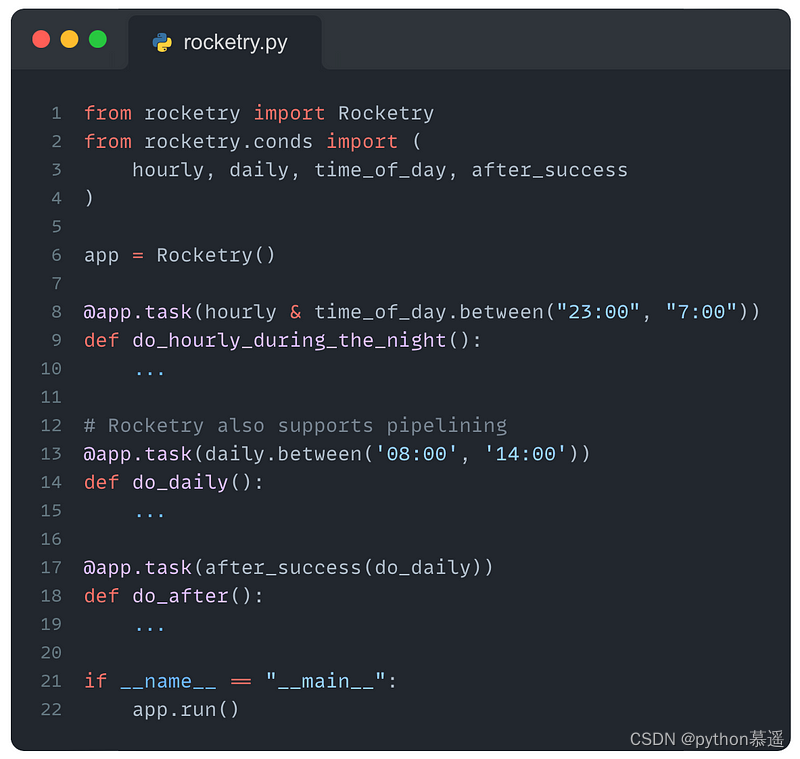
使用Rocketry调度Python函数
首先导入rocketry包,然后可以使用装饰器@app.task(...)定义任务,非常简单。
5.使用Faker生成逼真的虚假数据
Faker是一个Python包,可以轻松创建虚假但逼真的测试数据。它可以生成姓名、地址、邮政编码等等,告别手工创建测试数据,使用Faker改进测试效果。
可以使用pip安装该库:pip install Faker
如下所示,可以看到一些示例:
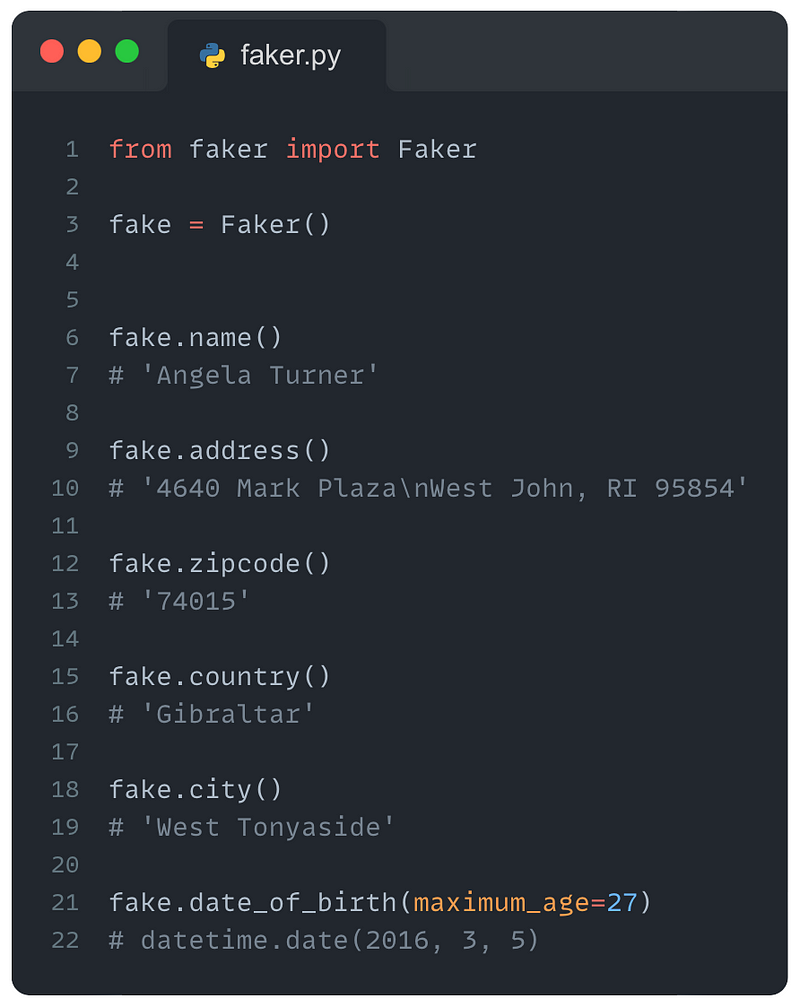
使用Faker生成逼真的虚假数据
首先导入Faker包并创建一个对象,然后就可以使用此对象生成逼真的虚假数据(姓名、地址、邮政编码等等),生成虚假数据比以往任何时候都更容易。
6.以一种简单的方式跟踪机器学习实验
跟踪机器学习实验非常重要,但是要知道编写多个日志语句可能会有点麻烦。为了简化事情,可以在训练代码之前添加mlflow.autolog()以实现自动日志记录。
最棒的是提供了一个基于Docker的开源MLflow Workspace,帮助立即开始跟踪,可以从GitHub下载我们的MLflow Workspace(包含Python示例)。
【下载链接】:https://github.com/tinztwins/mlflow-workspace
可以看到一个短视频演示,演示如何使用MLflow Workspace进行自动日志记录,可以在GitHub存储库中找到更多信息,使用MLflow Workspace跟踪你的机器学习实验,尽情享受MLflow Workspace带来的乐趣,愉快地进行跟踪。
7.通过单个参数加快代码速度
大型pandas数据帧可能会消耗大量内存,令人惊奇的是,通过以较小的块处理数据可以帮助防止内存耗尽并更快地访问数据!
可以在下图中看到一个示例:
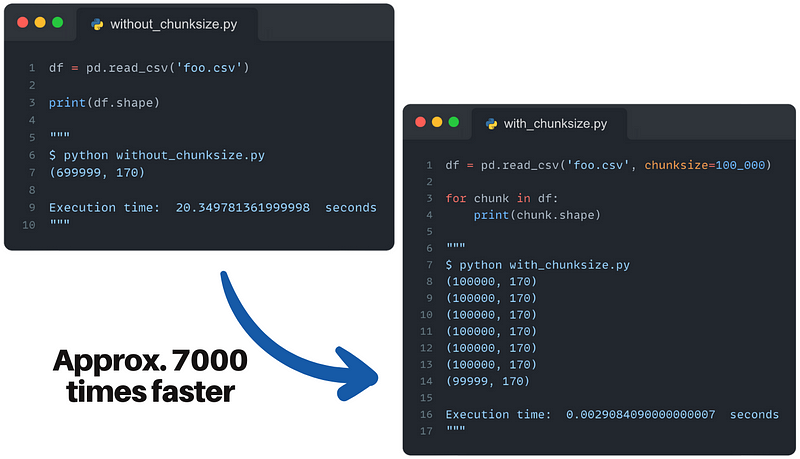
使用chunksize加快数据访问速度
速度快了近7000倍,下次想要读取大型数据帧时,应记住使用该参数。
综上所述,这七个技巧旨在提升Python技能,提高工作效率,并简化作为数据数据工程师的生活。
从使用Pix2TeX轻松将图像转换为LaTeX代码,到使用vulture清理代码,使用python-dotenv保护敏感数据,使用Rocketry调度函数,使用Faker生成虚假数据,使用mlflow跟踪机器学习实验,以及在处理大型pandas数据帧时加快代码速度,每个技巧都能带来独特的价值。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++——简介、Hello World、变量常量、数据类型
- 金蝶云星空扩展业务对象保存报错,提示列名 ‘F_XXXX_CKLB‘ 无效。
- 弹性调度助力企业灵活应对业务变化,高效管理云上资源
- LeetCode //C - 2130. Maximum Twin Sum of a Linked List
- linux服务器实现免密登陆
- 如何实现远程公共网络下访问Windows Node.js服务端
- docker -v 和docker --device 有什么区别
- 【linux】awk的基本使用
- 力扣:93. 复原 IP 地址(回溯)
- 猫头虎分享:最新Clion 2023.3.2 安装和试用教程