【保姆级教程|YOLOv8添加注意力机制】【1】添加SEAttention注意力机制步骤详解、训练及推理使用
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
?更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
《------正文------》
前言

SENet是一种新颖的架构单元,通过明确建模通道之间的相互依赖性,自适应地重新校准通道特征响应。本文详细介绍了如何在YOLOv8的主干网络中添加SEAttention注意力机制,并且使用修改后的yolov8网络结构进行目标检测训练与推理。本文提供了所有源码免费供小伙伴们学习参考,需要的可以通过文末方式自行下载。
本文使用的ultralytics版本为:ultralytics == 8.0.227。
目录
1. SENet简介
github地址:https://github.com/hujie-frank/SENet
paper地址:https://arxiv.org/pdf/1709.01507.pdf
摘要:卷积神经网络(CNN)的核心构建块是卷积运算符,它使网络能够通过在每一层的局部感受域内融合空间信息和通道信息来构建有信息量的特征。以前的研究广泛探讨了这种关系的空间部分,旨在通过增强特征层次结构中空间编码的质量来增强CNN的表征能力。在这项工作中,我们转而关注通道关系,并提出了一种新颖的架构单元,我们称之为“挤压激励”(SE)块,通过明确建模通道之间的相互依赖性,自适应地重新校准通道特征响应。我们展示了这些块可以堆叠在一起形成可以在不同数据集上极其有效地推广的SENet架构。我们进一步证明,SE块在现有最先进的CNN上带来了显著的性能改进,稍微增加了计算成本。挤压激励网络构成了我们在ILSVRC 2017分类竞赛中的首个提交,获得了第一名,并将前五错误率降低到2.251%,相对于2016年的获胜成绩改善了约25%。
论文亮点如下:
SE块是一种旨在通过使网络能够进行动态通道特征校准来改善网络表征能力的架构单元。广泛的实验表明了SENets的有效性,它们在多个数据集和任务上实现了最先进的性能。此外,SE块也为之前的架构无法充分建模通道特征依赖关系的问题提供了一些启示。我们希望这一洞见对于其他需要强有力的区分特征的任务也能有所帮助。最后,SE块产生的特征重要性值也可以在其他任务中发挥作用,例如网络剪枝以进行模型压缩。
1.1 SENet网络结构
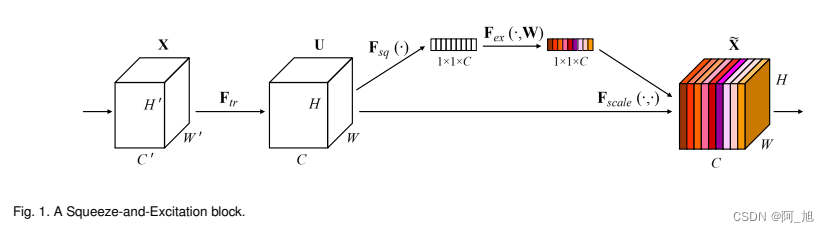
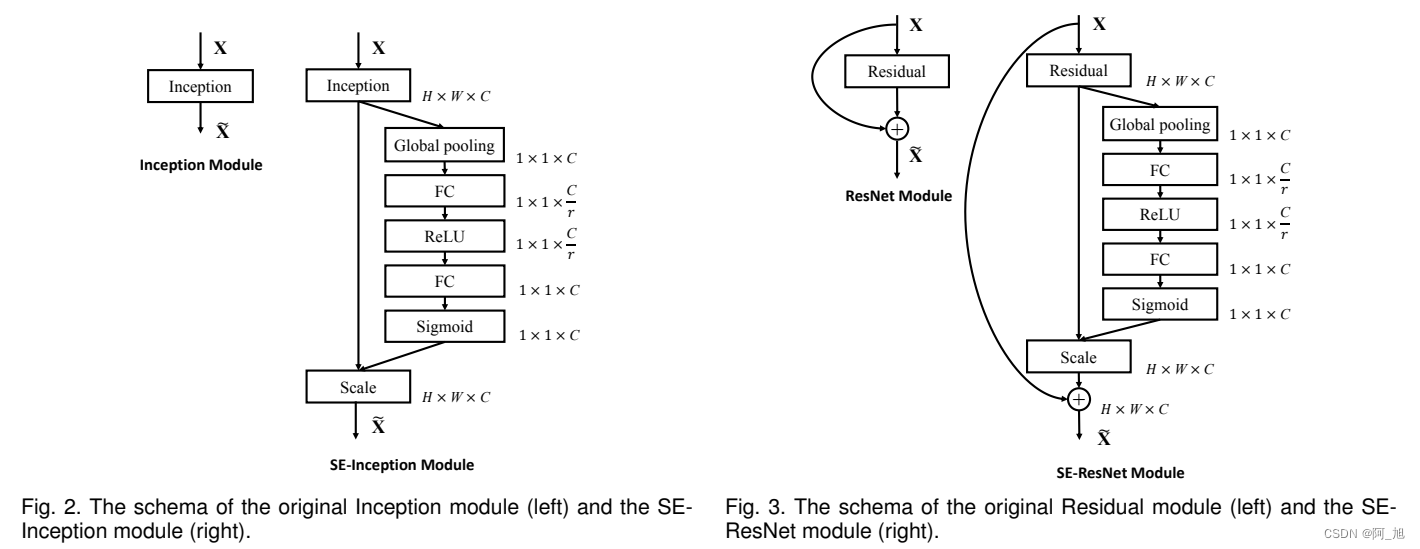
1.2 性能对比
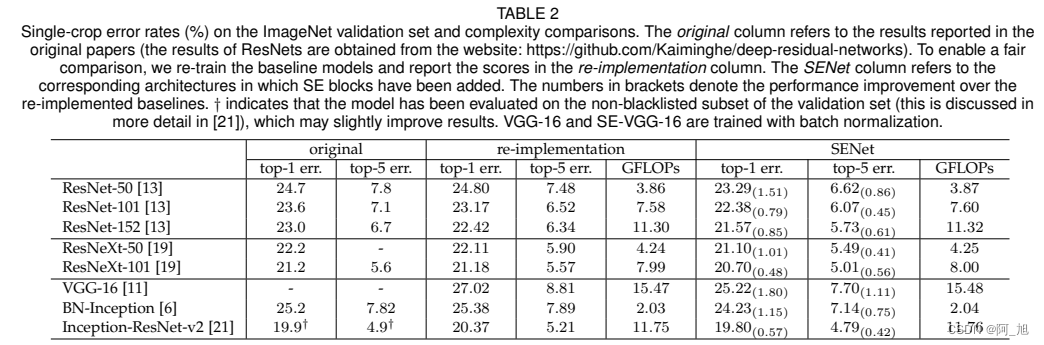
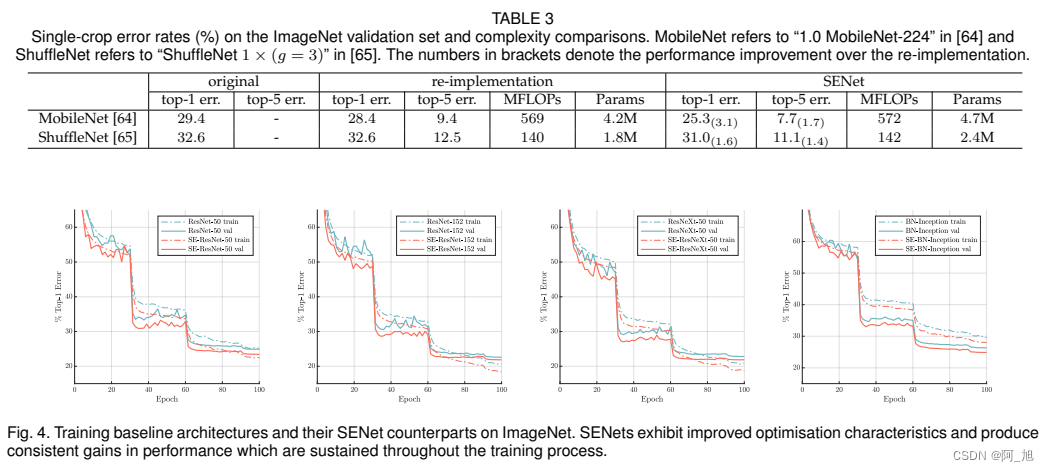
2.在YOLOV8主干中添加SEAttention注意力
第1步:新建SEAttention模块并导入
在ultralytics/nn目录下,新建SEAttention.py文件,内容如下:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512,reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
然后在ultralytics/nn/tasks.py中,导入SEAttention模块。
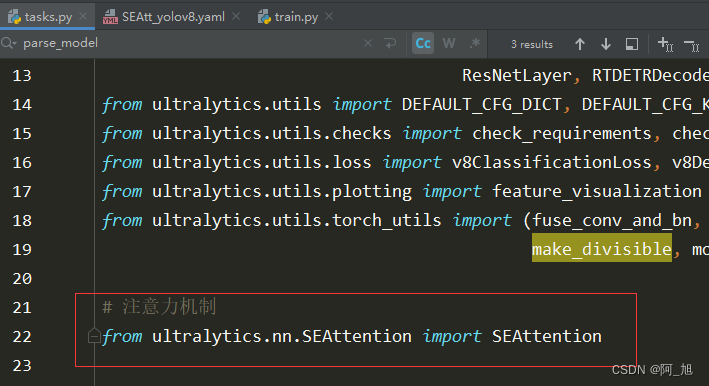
第2步:修改tasks.py部分代码
修改在ultralytics/nn/task.py中的parse_model函数【作用是解析模型结构】:在解析的地方添加如下代码:
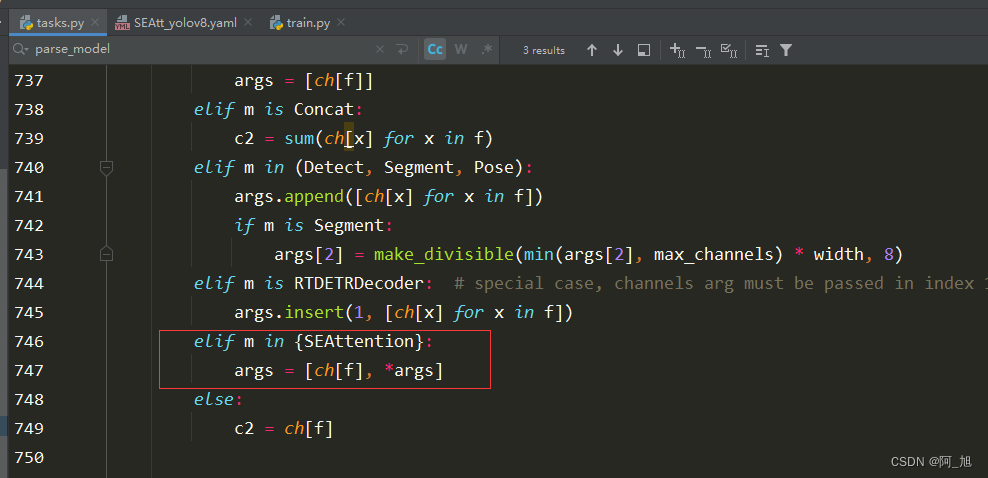
elif m in {SEAttention}:
args = [ch[f], *args]
然后创建SEAtt_yolov8.yaml文件,用于修改网络结构添加注意力,内容如下:【将注意力添加到自己想添加的层就行】,在这示例中我们是添加到了主干网络的最后面。
# Ultralytics YOLO ?, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, SEAttention, [16]]
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
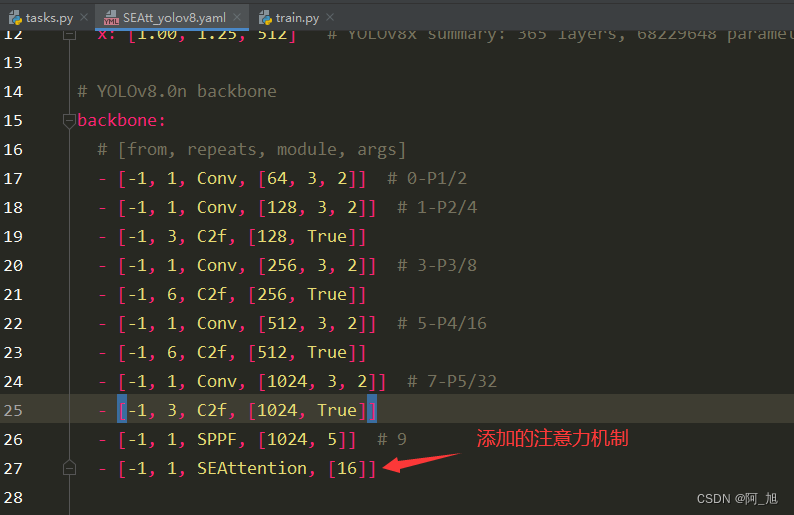
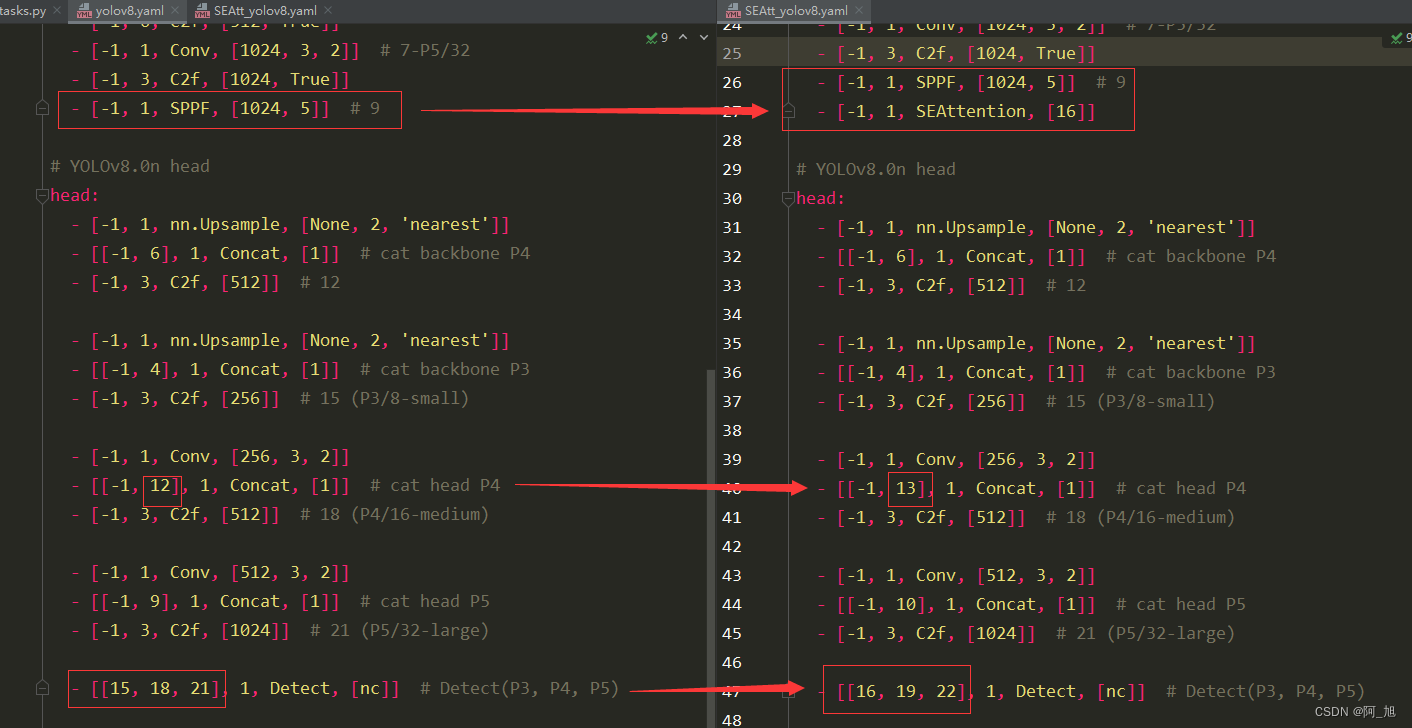
此处注意修改层数的变化,层数是从0开始数的,由于此处是添加到了第10层,因此后面层数都发生了变化。10层以后的相关层数都需要加1.具体修改内容如下:【左边是原始的yolov8.yaml文件,右边是新建的SEAtt_yolov8.yaml文件】
第3步:加载配置文件训练模型
运行训练代码train.py文件,内容如下:
#coding:utf-8
from ultralytics import YOLO
# 加载预训练模型
# 添加注意力机制,SEAtt_yolov8.yaml 默认使用的是n。
# SEAtt_yolov8s.yaml,则使用的是s,模型。
model = YOLO("ultralytics/cfg/models/v8/SEAtt_yolov8n.yaml").load('yolov8n.pt')
# Use the model
if __name__ == '__main__':
# Use the model
results = model.train(data='datasets/TomatoData/data.yaml', epochs=250, batch=4) # 训练模型
# 将模型转为onnx格式
# success = model.export(format='onnx')
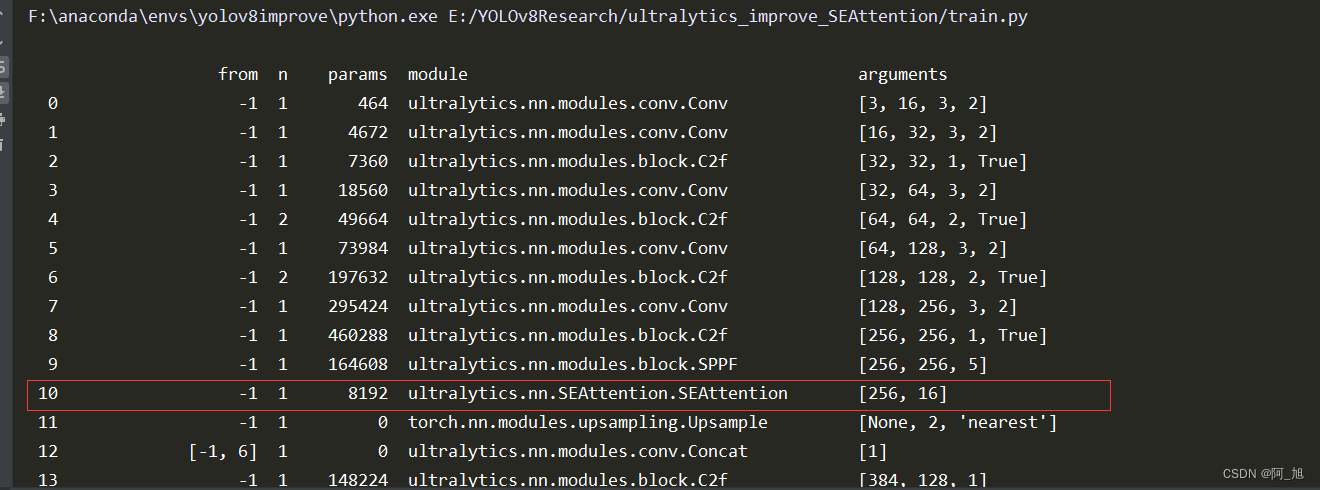
训练开始的时候,注意一下,打印出的网络结构是否有修改,如下图所示:模型训练开始时,打印的网络结构中显示SEAttention已经添加成功。
第4步:模型推理
模型训练完成后,我们使用训练好的模型对图片进行检测:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
# path = 'models/best2.pt'
path = 'runs/detect/train2/weights/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/Riped tomato_20.jpeg"
# 加载预训练模型
# conf 0.25 object confidence threshold for detection
# iou 0.7 intersection over union (IoU) threshold for NMS
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path)
res = results[0].plot()
res = cv2.resize(res,dsize=None,fx=0.5,fy=0.5,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)

【源码免费获取】
为了小伙伴们能够,更好的学习实践,本文已将所有代码、示例数据集、论文等相关内容打包上传,供小伙伴们学习。获取方式如下:
结束语
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!