高性能Mixtral:467亿参数MoE技术,逼近GPT-3.5与GPT-4
模型简介
近日,Mistral AI团队发布了全新的大型语言模型——Mixtral 8x7B。这款以稀疏专家混合模型(Sparse Mixture-of-Experts,简称SMoE)为基础的语言模型,拥有467亿个参数,是当前市场上最强大的开源权重模型之一。不仅如此,Mixtral 8x7B还在Apache 2.0许可下开源,为开发者社区提供了一个全新的研究和应用平台。、
-
Huggingface模型下载: https://huggingface.co/mistralai
-
AI快站模型免费加速下载: https://aifasthub.com/models/mistralai
技术特点和性能
-
稀疏混合专家模型(SMoE): Mixtral 8x7B采用了高效的稀疏混合专家网络结构。这种结构通过“路由网络”(router network)智能选择并组合不同的参数组(即“专家”),使模型在处理每个token时,仅使用总参数的一小部分。这种技术在增加模型参数的同时,有效控制了运算成本和延迟,因为模型每个token只使用12.9B参数,使其在速度和成本上与12.9B模型相当。
-
强大的处理能力: Mixtral 8x7B能处理高达32k个token的长上下文,支持多语言处理,包括英语、法语、意大利语、德语和西班牙语。它在代码生成方面表现出卓越的性能,同时可以优化为指令遵循型模型,有效应对各种复杂的任务。

-
显著的性能优势: 在多项基准测试中,Mixtral不仅与70亿参数的Llama 2和GPT3.5相媲美,甚至在某些领域超越了这些模型。特别是在真实性和偏见测试(如TruthfulQA/BBQ/BOLD)中,Mixtral展现了更高的真实性和较低的偏见。
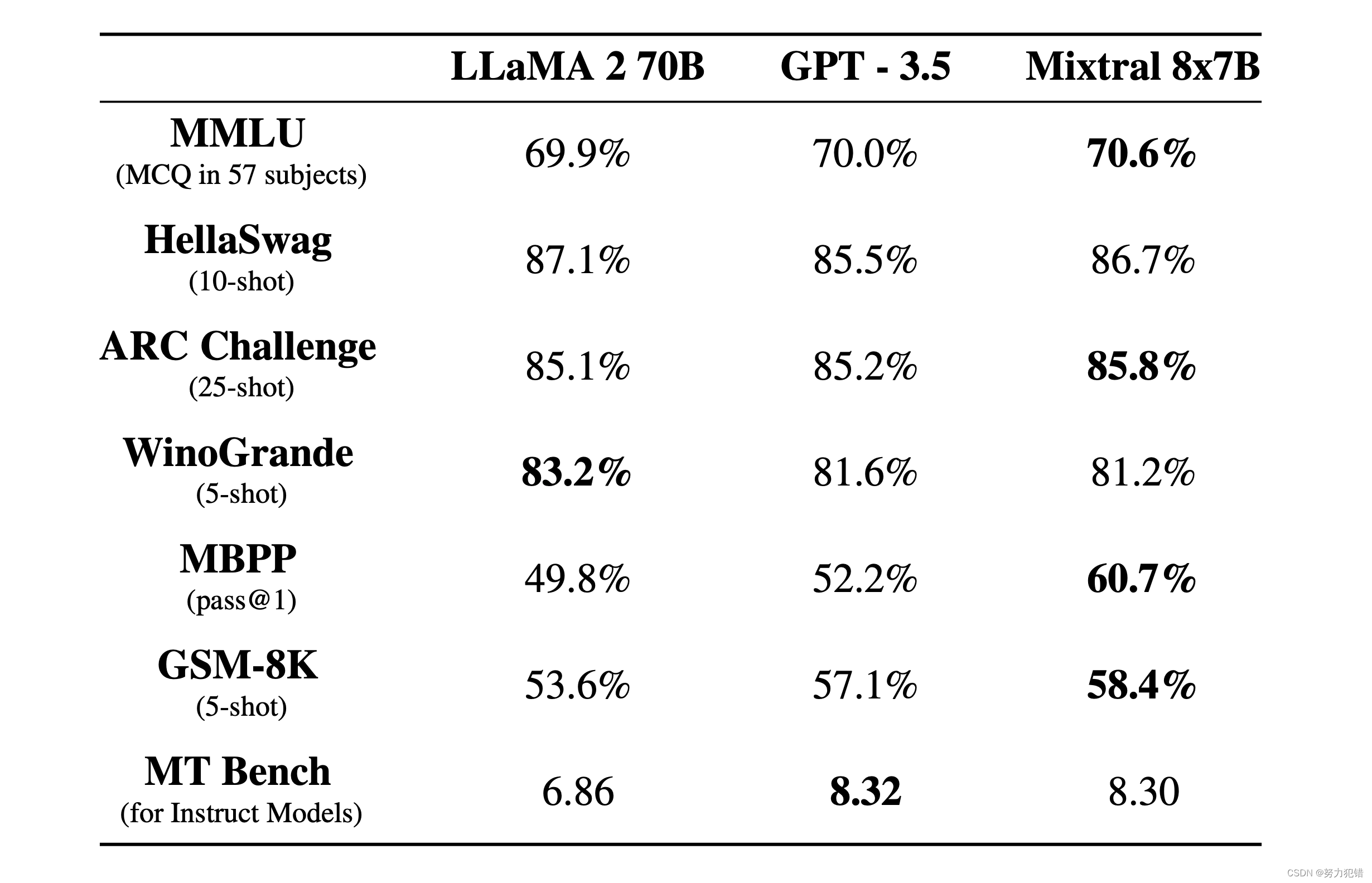
-
高效的推理性能: Mixtral 8x7B在推理速度上相较于Llama 2 70B有显著提升,达到6倍快的推理速度。这意味着在相同的硬件条件下,Mixtral能更快地处理和生成响应,这对于实时应用来说极为重要。

-
优化的模型架构: Mixtral利用变量分组查询注意力(Variable Grouped Query Attention)技术,优化了传统的多查询注意力(MQA)和标准分组查询注意力(GQA)。这种方法在不同层之间引入变量,使得模型在保持高速处理的同时,也能提高准确度和生成质量。
-
自动化架构搜索(NAS)引擎: Mixtral的架构是通过Deci的高级NAS引擎AutoNAC开发的。这种自动化搜索过程在计算效率上更高,为Mixtral的高效架构设计提供了关键支持。
-
多样化的应用场景: Mixtral的设计不仅仅局限于文本生成。它在教育、客户服务、内容创作和其他多种领域都具有广泛的应用潜力。尤其是在需要处理大量并发请求的服务领域,Mixtral的高速、高容量处理能力将极大地提升用户体验和操作效率。
结语
Mixtral 8x7B的发布,不仅在大型语言模型领域设置了新的标准,而且其开源特性预示着AI技术更广泛的应用和发展。随着技术的不断进步,Mixtral无疑将在推动行业创新和提升AI解决方案效率方面发挥关键作用。
模型下载
Huggingface模型下载
https://huggingface.co/mistralai
AI快站模型免费加速下载
https://aifasthub.com/models/mistralai
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!