信息检索与数据挖掘 | (七)概率检索模型
发布时间:2024年01月23日
文章目录
- 出于一些追求完整性的强迫症,开始做考完试了梳理知识点博客的离谱行为🤡?
- 但是也存存吧,不然就啥也不记得了嘤🤡?
📚基本概率论知识
给定查询表示和文档表示,系统只能给出文档内容和需求是否相关的一个非确定性推测,而概率论可以为这种非确定性推测提供一个基本的理论。

📚概率排序原理PRP-probability ranking principle
-
思想:概率排序通过将输入映射到输出的概率,并根据概率大小对输出进行排序,从而提供了一种基于统计和概率模型的排序方法
-
流程: R d R_d Rd?, q q q表示查询q和文档d是否相关,利用概率模型估计每篇文档和query的相关概率P(R=1|d,q),然后对结果进行排序:
- 收集数据:首先,需要收集足够的数据来建立概率模型。这可以是训练集、历史数据、用户行为数据等。数据应该包含输入和对应的输出(标签或评分)。
- 建立概率模型:使用收集到的数据,可以建立一个概率模型,例如朴素贝叶斯模型、逻辑回归、支持向量机等。概率模型将输入映射到输出,并给出了输入属于每个可能输出的概率。
- 计算概率:对于给定的输入,利用概率模型计算每个可能输出的概率。这些概率可以表示为条件概率、联合概率或后验概率,具体取决于所使用的模型和问题类型。
- 排序:根据计算得到的概率,对输出进行排序。通常,概率越高的输出将被排在前面,概率越低的则排在后面。这样可以使得排名靠前的结果更有可能是用户期望的答案或推荐。
- 可选的后处理:根据具体情况,可以对排序结果进行进一步的后处理。例如,可以加入其他特征或规则来调整排序顺序,考虑业务需求或用户反馈等因素。
-
结果:如果某个参照检索系统对每个需求进行应答时,会按照文档和需求的相关性概率从大到小排序,其中相关性概率是基于系统能得到的所有数据来尽可能精确估计而得到的,那么该系统是基于已知数据的可以获得的总体效果最优的系统。
📚二值独立模型BIM-Binary Independence Model
- 假设
- 文档和查询都表示为词项出现与否的布尔向量。即文档d表示为 x ? = ( x 1 , . . . , x M ) \vec{x}=(x_1,...,x_M) x=(x1?,...,xM?)
- M是字典大小,当词项t出现在文档d中,x为1,否则为0。不考虑词项的出现次数及顺序,所以不同的文档可能有相同的向量表示。
- 另外假设“独立性”,指词项在文档中的出现是互相独立的。
- 按照相关概率对文档进行排序
- 我们基于词项出现向量的概率P(R|x,q)对概率P(R|d,q)进行建模,使用贝叶斯定理有:

-
分子的第一项表示当返回一篇相关或不相关文档时文档为x的概率。
-
分子第二项表示对于查询q返回一篇相关和不相关文档的先验概率。
-
排序函数的推导



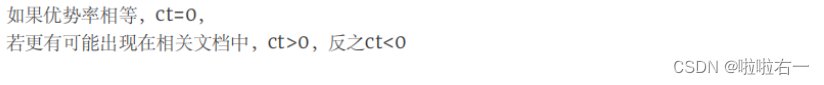


📚Okapi BM25模型
-
对于文档d,最简单的文档评分方法是给文档中的每个查询词一个idf权重

-
通过引入词项频率和文档长度,上式可以修改为

- ??解释:k1是取正的参数,k1=0是BIM模型,k1取较大的值,对应于原始词项频率,b是[0,1],决定文档长度的缩放程度,b=1表示基于文档长度对词项权重进行完全的缩放,b=0表示归一化时不考虑文档长度因素。
文章来源:https://blog.csdn.net/m0_63398413/article/details/135001939
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- WebofScience快速检索文献的办法
- CPMP、IPMP、PMP这三个认证优缺点?
- 企业电子招投标采购系统源码之鸿鹄电子招投标系统+电子招投标的组成
- 解释 Git 的基本概念和使用方式。
- 真菌基因组研究高分策略(二):比较基因组揭示寄主外生菌根真菌基因组的动态进化
- Android 清除临时文件,清空缓存
- 125 验证回文串
- NetApp AFF C 系列全闪存存储的主要优势和软件特性
- 【算法题】62. 不同路径
- 基于Java SSM框架实现智能停车场管理系统项目【项目源码+论文说明】