深度学习数据预处理
首先掌握一个创建文件的方法:
先导入os库(对文件进行操作)os.makedirs函数用于递归创建目录。其语法如下:
os.makedirs(name, mode=0o777, exist_ok=False)
?
name:要创建的目录的路径。mode:目录权限,默认为0o777,表示最大的访问权限。exist_ok:如果设置为True,则在目录已经存在的情况下不会抛出异常。
os.makedirs函数会递归地创建目录,即如果指定的目录路径中的某些父目录不存在,它也会一并创建。如果目录已经存在,且exist_ok参数为True,则不会抛出异常;如果exist_ok为False(默认值),则会抛出FileExistsError异常。
除此之外还有os.path。os.path 模块提供了许多用于处理文件路径的函数。下面是一些常用的 os.path 函数:
os.path.join(path1[, path2[, ...]]):将多个路径组合后返回os.path.abspath(path):返回绝对路径os.path.basename(path):返回文件名os.path.dirname(path):返回文件路径os.path.exists(path):判断路径是否存在os.path.isfile(path):判断路径是否为文件os.path.isdir(path):判断路径是否为目录os.path.split(path):将路径分割成目录和文件名的元组os.path.splitext(path):分割路径的扩展名os.path.getsize(path):返回文件大小
这些函数可以帮助你处理文件路径,获取文件名、目录名,判断路径是否存在,以及获取文件大小等操作。
我们当前的文件默认为__file__,比如要返回当前路径: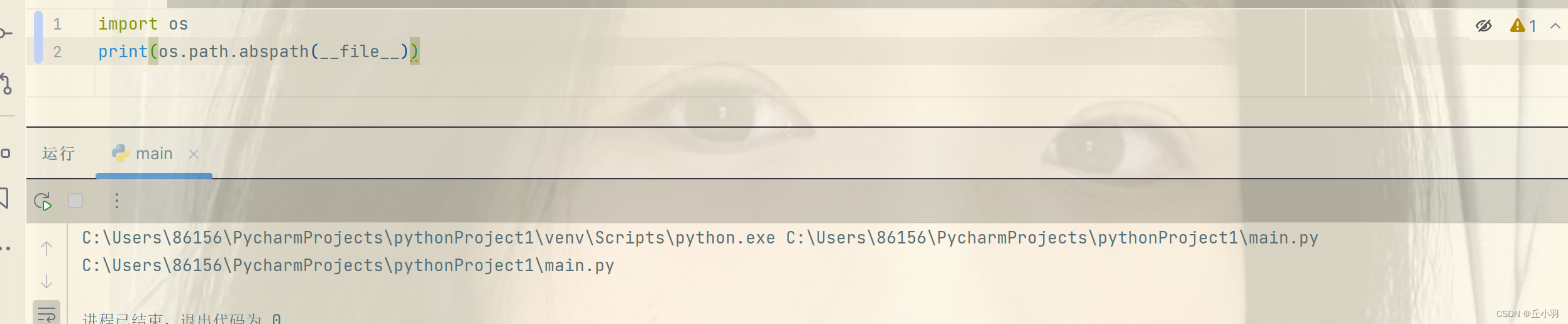
返回文件名:
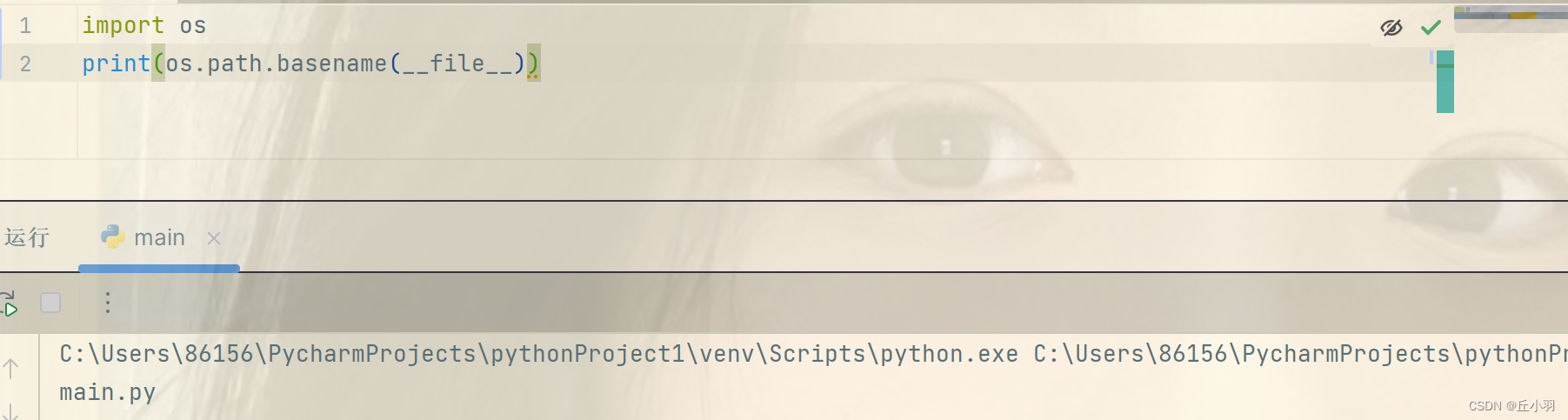
下面我们创建一个人工数据集,并存储在csv文件中,文件../data/house_tiny.csv中。
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
这段代码的作用是在当前目录的上一级目录(使用“..”)来创建一个/data的文件夹,如果存在则不会抛出异常,(如果没有exist_ok参数,存在的话,会抛出异常)。
data_file=os.path.join('..', 'data', 'house_tiny.csv')
这段代码是表示当前路径的/data下的house_tiny.csv文件。
with open(data_file, 'w') as f: 这里,如果data_file文件不存在会自动创建一个空文件,明显,上句中并不会创建文件,house_tiny.csv文件是在open函数里面创建的。
f.write('NumRooms,Alley,Price\n')#写入第一行
f.write('NA,Pave,127500\n')#写入第二行
f.write('2,NA,106000\n')#写入第三行
f.write('4,NA,178100\n')#写入第四行
f.write('NA,NA,140000\n')#写入第五行
\n是转义字符,表示换行。
不过删除行比较困难,这里我们需要一些技巧,我们将文件内容读入lines列表中,然后将列表中元素写入一个新的文件,同时跳过指定元素。
这些代码执行完后就会在你当前文件的上一层目录中生成一个文件,文件中含有house_tiny.csv文件:

该文件中又有写入的数据:

而后我们要读取数据集,用来加载原始数据,我们需要导入pandas包,并调用read_csv函数,该数据集有四行三列。
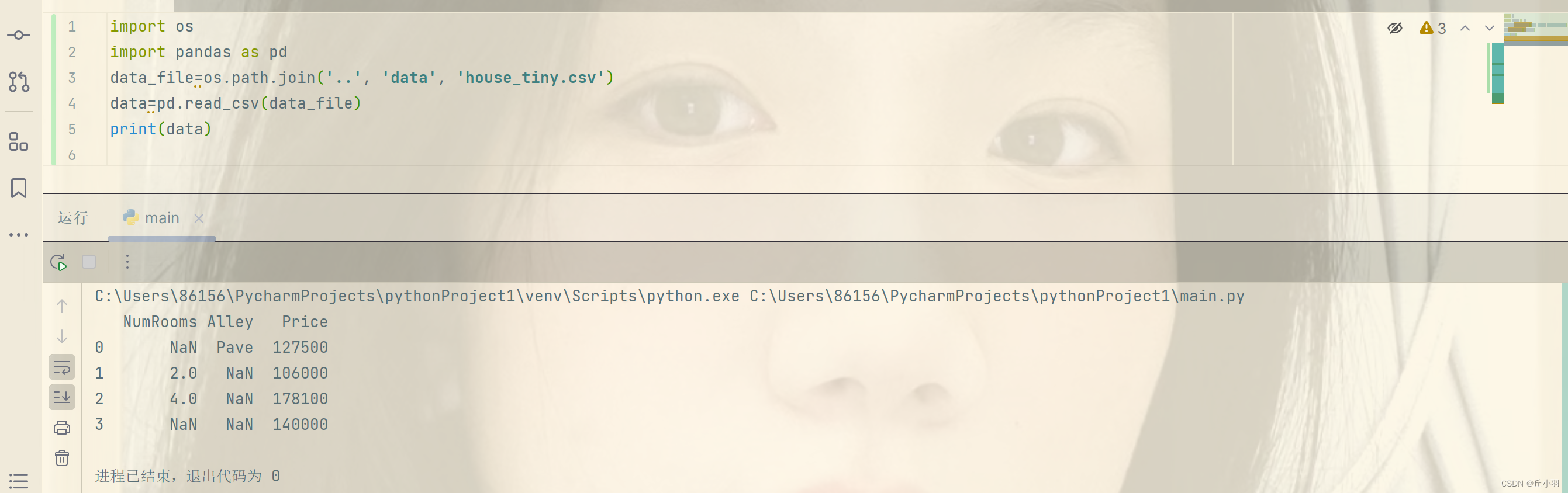
通常将文件的第一行默认为属性,从第二行开始作为每一个样本数据,左边是索引,索引从0开始。
处理缺失值:
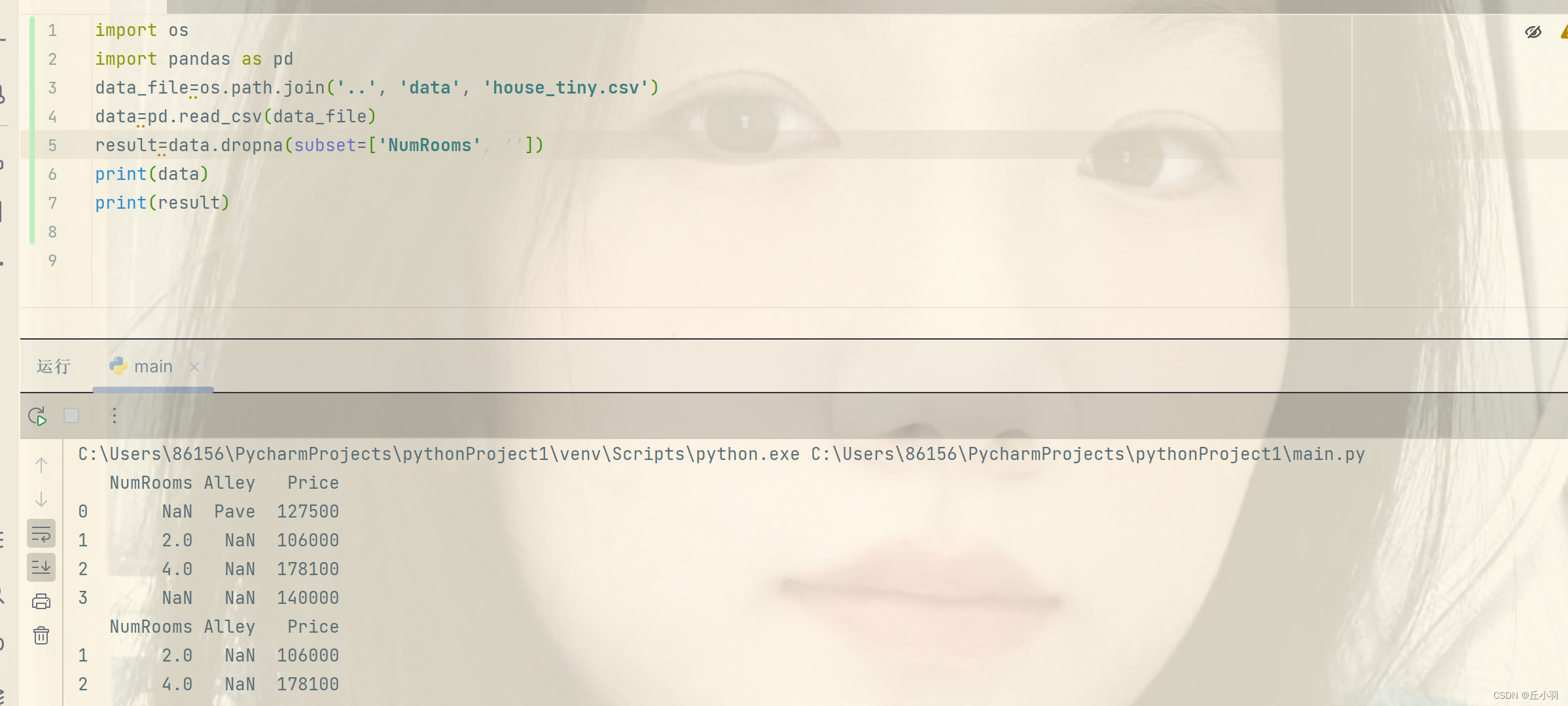
NaN表示缺失值,处理缺失值我们将常用到插值法,当然也有删除法。以下是删除法:dropna函数是删除,后面的参数subset=['NumRooms']表示删除指定的列,如果没有这个参数,则默认是所有的列。
我们还可以用插值法处理,在这里,我们将房屋数量中NAN值变为已知数据的均值(inputs.mean()),其实指的是这一列的均值,其中NAN表示默认为0。
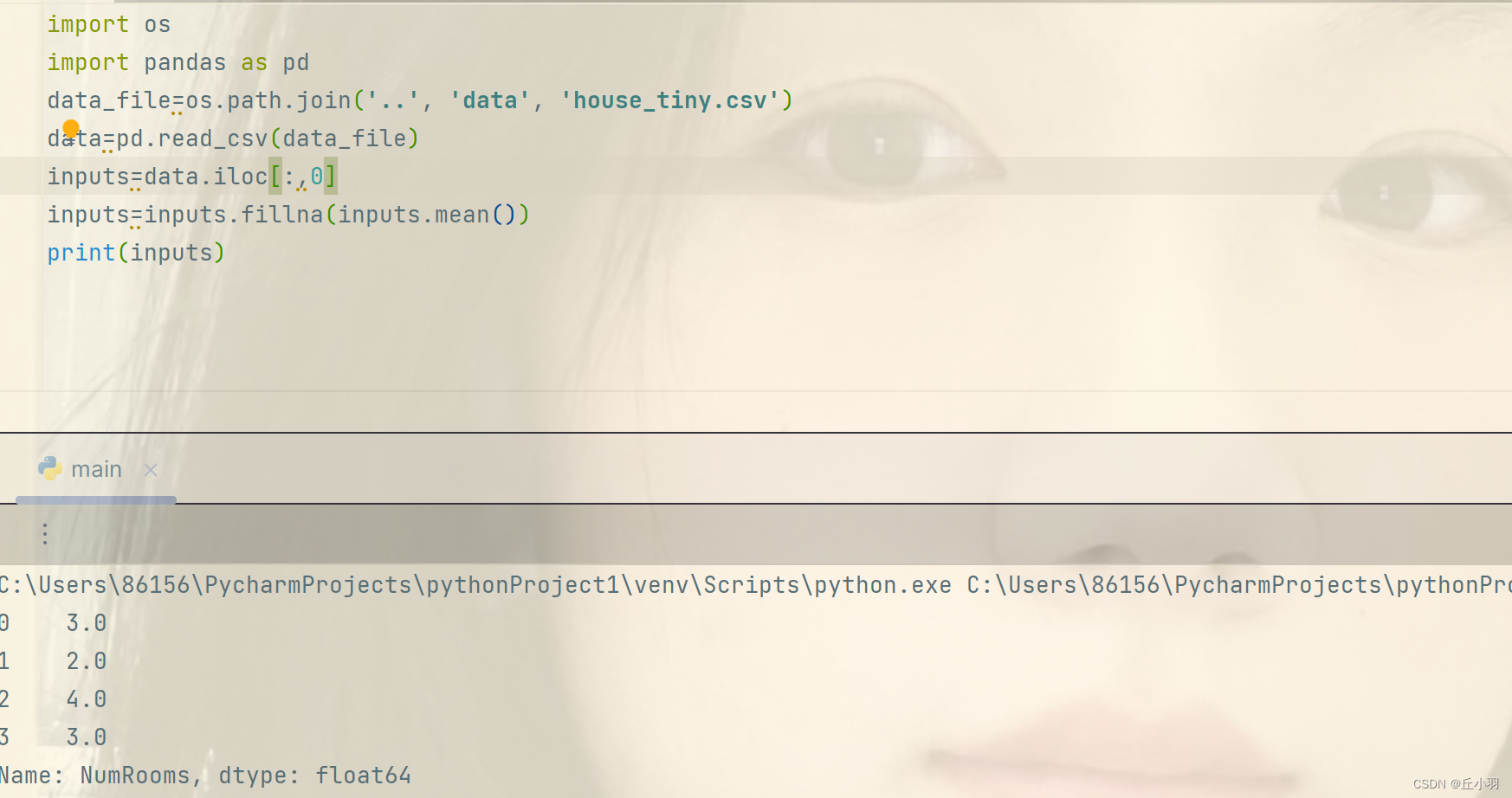
当然我们还可以指定填充。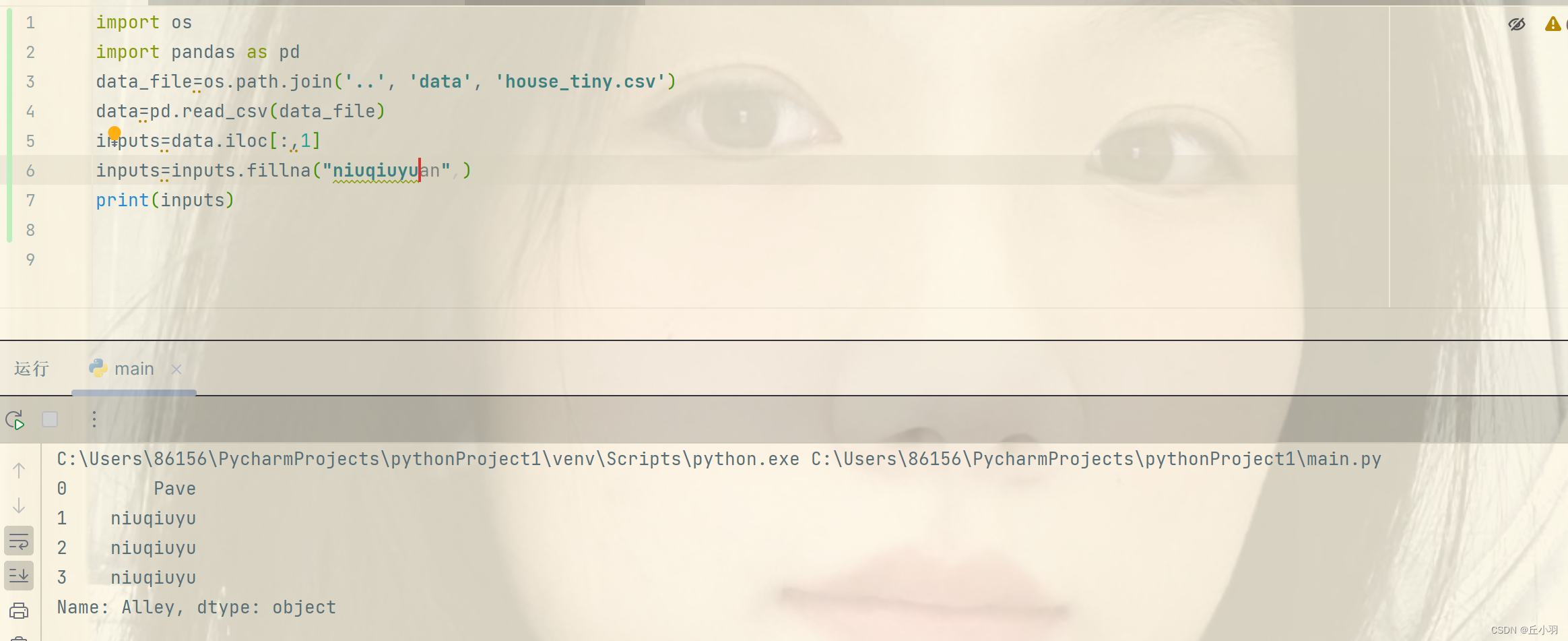
这里我们将Alley属性为NAN的默认填充为niuqiuyu。
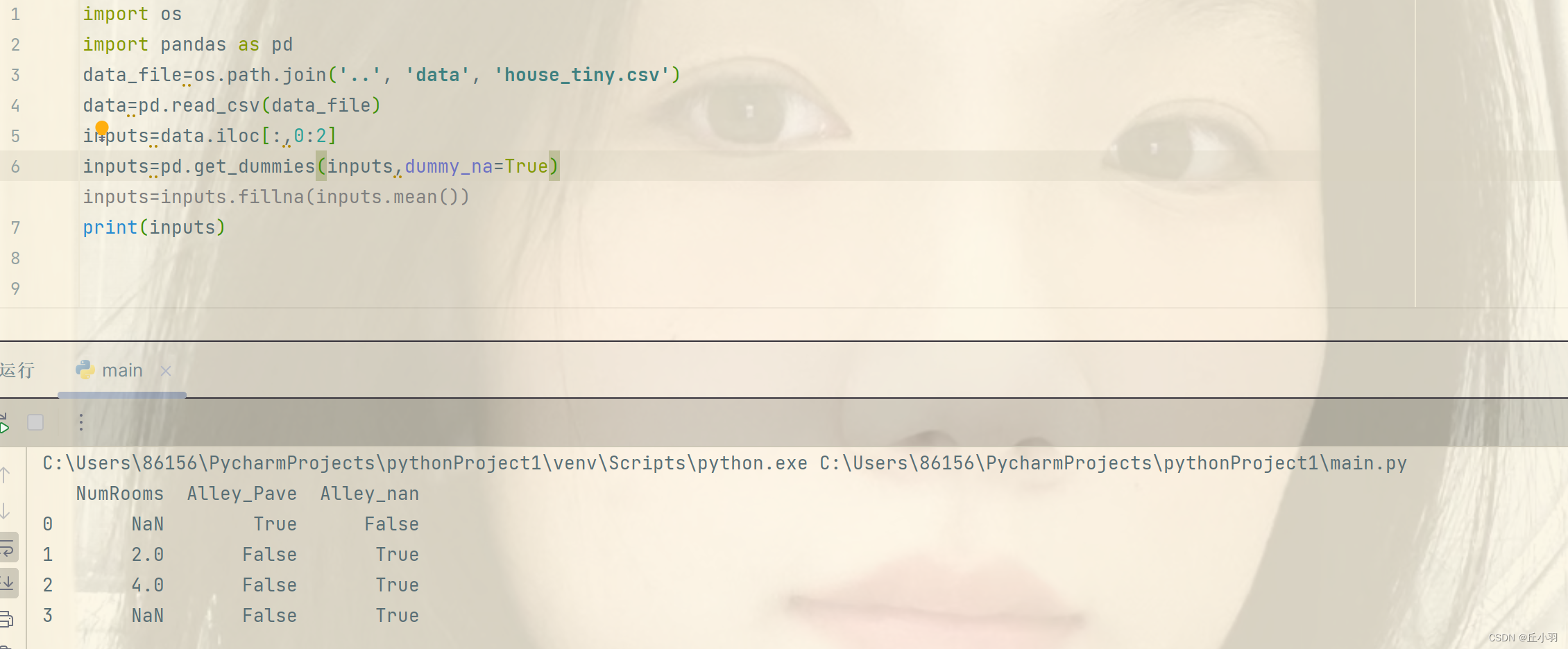
对于inputs中的类别值或离散值,我们将NaN视作一个类别,由于Alley列只接受两种类别值Pave和NaN,pandas可以自动将此列转化为两列Alley_Pave和Alley_nan,对应样本存在的话为true,否则为false。
转化为张量格式:
现在inputs和outputs中的条目都是数值类型,可以将他们转化为张量格式,我们通常使用张量格式进行计算。values函数是保留数值。
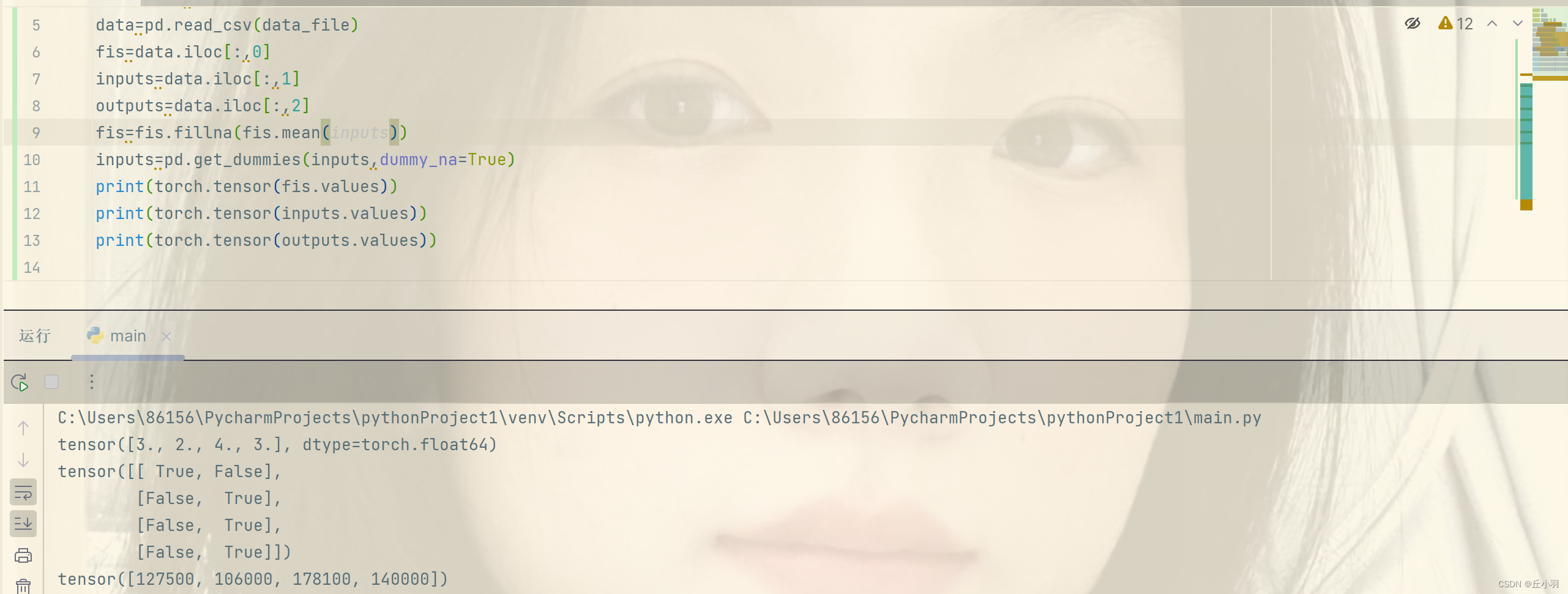
一个小quiz:
1,删除缺失值最多的列。
2,将预处理后的数据集转化为张量格式。
(答案将在下集揭晓)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 参加百度的测试开发面试是一种怎样的体验?
- 桥接虚拟机设置上网步骤
- Flink集成Hive之Hive Catalog
- CSS 纵向扩展动画
- Python: 你所不知道的星号 * 用法
- LeetCode刷题--- 解数独
- 九、分布式锁 —— 超详细操作演示!!!
- Solidity-20 StorageToStorageValueTypeAssignment
- Pingcode和HelpLook对比:哪一个知识库工具更好?
- PCL 已知同名点对计算旋转矩阵并对点云进行旋转