Automated clinical coding using off-the-shelf large language models

Tags: Diagnosis Prediction, LLM
Authors: Alison Q. O’Neil, Antanas Kascenas, Joseph S. Boyle, Maria Liakata, Pat Lok
Created Date: January 18, 2024 3:57 PM
Status: Reading
organization: Anglia Ruskin University, Canon Medical Research Europe, Queen Mary University of London, The Alan Turing Institute, University of Edinburgh, University of Warwick
publisher : NeurIPS
year: 2023
paper: https://arxiv.org/abs/2310.06552
介绍
给住院病人分配icd诊断编码通常是专业的人类编码专家的工作。在人工智能领域,主要的方向是通过有监督深度学习模型来进行自动icd编码。然而,学习如何预测大量的罕见编码仍然是临床实践中存在的困难。
因此本文尝试利用现成的大语言模型来尝试开发一个零样本和少样本的编码对齐方案,尝试避开特定任务的训练过程。由于无监督的预训练并不能保证对于ICD本体和临床编码任务的准确性,因此本文将任务视为信息抽取。让大语言模型根据提供的编码概念来进行相关提及的抽取。为了提高效率,本文利用ICD本体的层次结构来稀疏地搜索相关代码,而不是遍历所有的代码。
本文主要贡献:
- 在ICD编码任务中首次尝试无特定任务训练或微调的方法。
- 证明了大语言模型即开即用的ICD编码能力。
- 本文提出了一种方法,通过将信息注入LLM提示并应用类似于多标签决策树的新型搜索策略,避免对目标编码本体的模型知识的依赖。经验证明,这种树搜索策略在罕见编码上提高了模型性能。
方法
信息检索形式
整体提示:
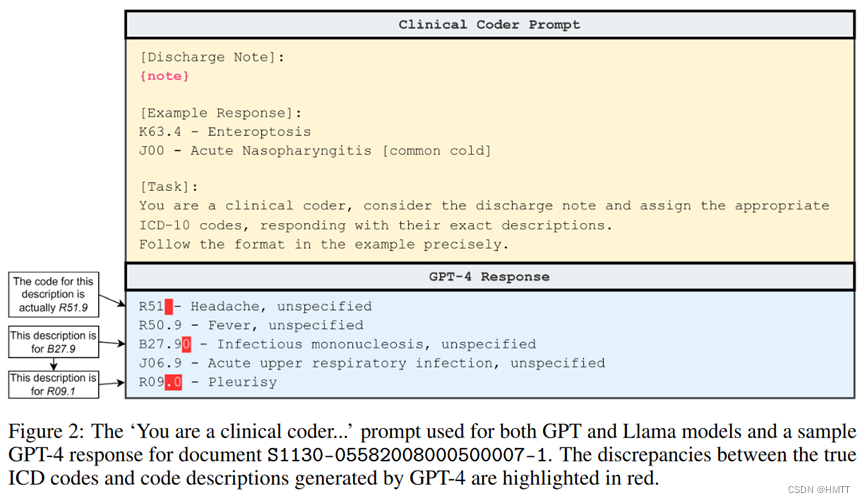
让大语言模型输出文本中能对应上的icd编码及其描述。
由于大语言模型的回复中存在一些错误信息,因此文中把问题定义为信息检索,并让大语言模型从给定文本中检索候选代码。如下图:

树形搜索
由于ICD编码的数量巨大,因此很难确定具体使用哪些编码,因此作者尝试使用一种树形检索结构,尝试让大语言模型递归检索树的第二层概念,并最终返回一个叶子结点。
具体方法如下:
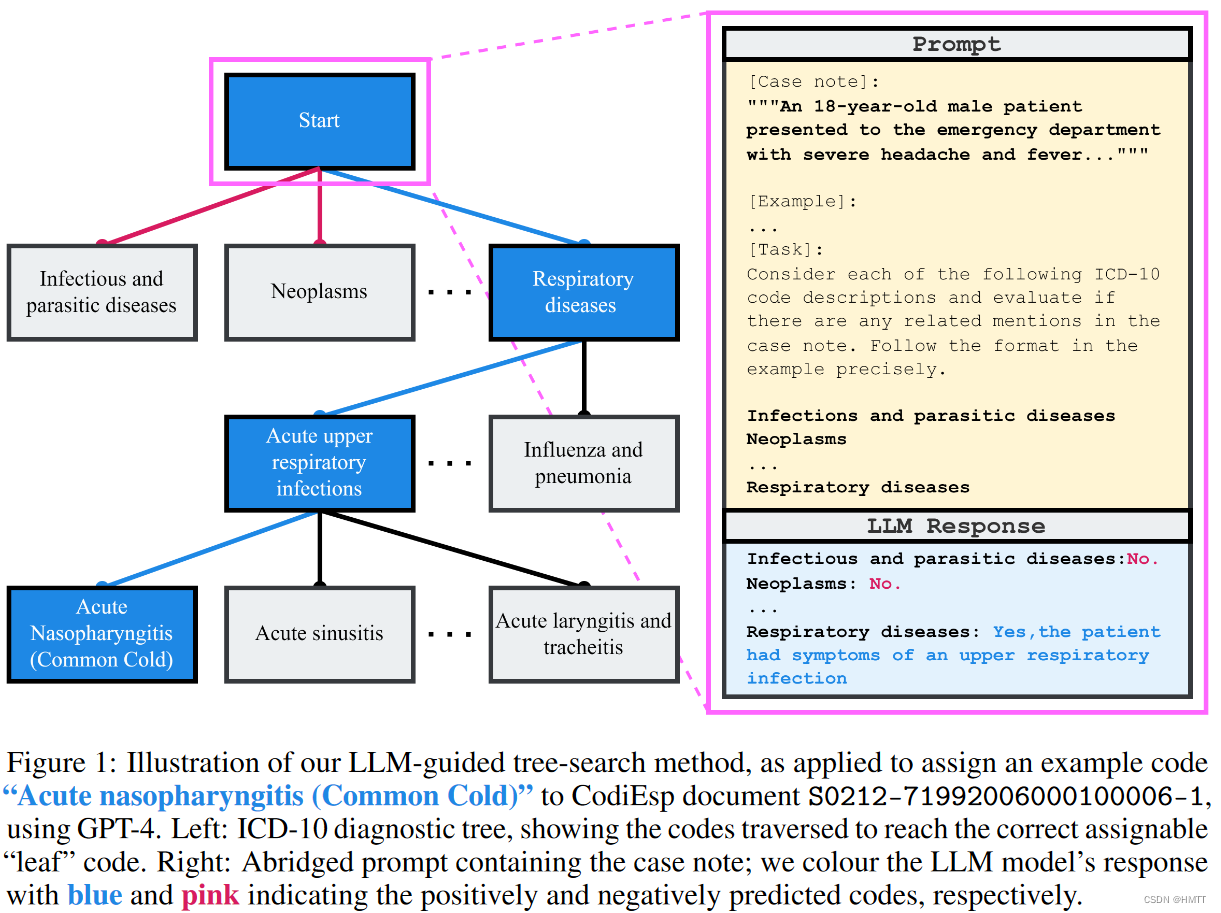
实验
本中使用了三种检索方式:
- 直接生成icd编码,匹配具体的代码
- 直接生成icd编码,匹配代码的描述
- 树形搜索
具体结果如下:
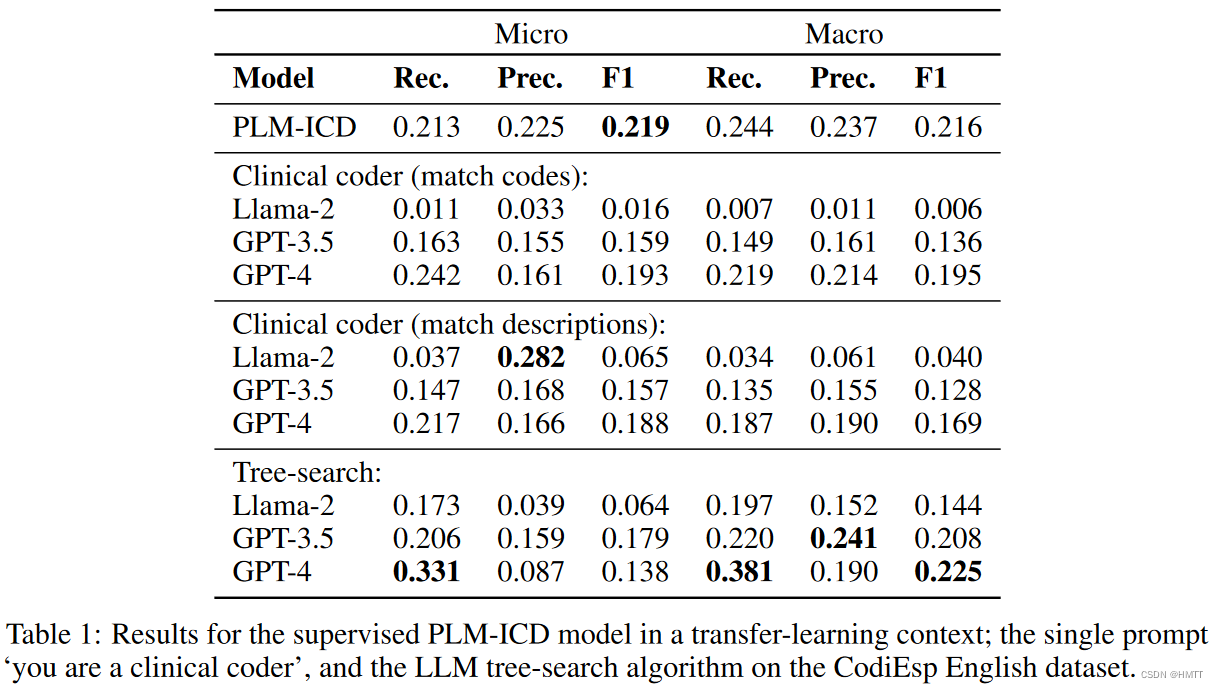
此外,文中还根据树形结构做了实验,如果预测到某层的正确父类,就算正确答案:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LeetCode刷题---字母异位词分组(哈希表)
- 这本书没有一个公式,却讲透了数学的本质
- 竞赛练一练 第27期:GESP和电子学会相关题目练习
- 【面试】在Python中如何实现单例模式
- Python元组与字典的基础介绍
- 比丝袜还丝滑!这个简历制作软件10大优势!
- 晶振的输出波形:TTL、CMOS、LVPECL、LVDS和正弦波
- 【图像去噪】基于带脉冲检测器实现图像去噪PSNR计算附matlab实现
- Vue2-组件的基本应用
- 虚拟主机操作系统 Windows、Linux