前端远原生js爬取数据的小案例
发布时间:2024年01月13日
使用方法
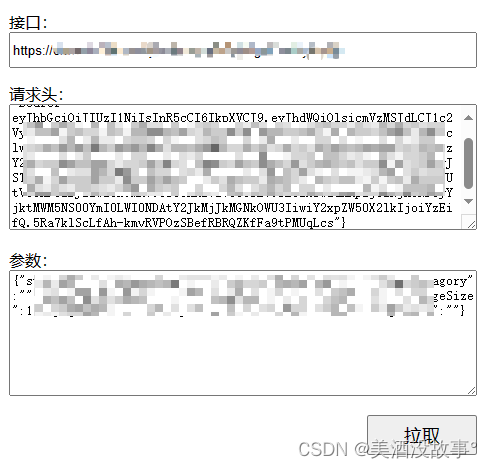
注意分页的字段需要在代码里面定制化修改,根据你爬取的接口,他的业务规则改代码中的字段。比如我这里总条数叫total,人家的不一定。返回的数据我这里是data.rows,看看人家的是叫什么字段,改改代码。再比如我这里的分页叫pageNum,人家的可能叫pageNo
效果
上源码
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>爬虫</title>
<style>
.container{
width: 50%;
margin: 50px auto;
}
input,
textarea {
height: 30px;
width: -webkit-fill-available;
margin-bottom: 15px;
}
textarea {
height: 120px;
}
button {
height: 40px;
width: 110px;
font-size: 18px;
}
#h1,
#h2 {
text-align: center;
}
</style>
</head>
<body>
<div class="container">
<div>
接口:<input id="api" type="text" /> <br />
请求头:<textarea id="headers" type="text" placeholder="要json格式"></textarea><br />
参数:<textarea id="textarea" placeholder="要json格式"></textarea>
</div>
<div style="text-align: right;">
<button onclick="crawling()">拉取</button>
</div>
<h1 id="h1"></h1>
<h2 id="h2"></h2>
</div>
<script>
var total = 0;
var pageNum = 1;
var pageSize = 30;
var api = "";
var headers = "";
var textarea = "";
const h1 = document.querySelector("#h1");
const h2 = document.querySelector("#h2");
async function crawling() {
api = document.querySelector("#api").value;
headers = document.querySelector("#headers").value;
textarea = document.querySelector("#textarea").value;
h1.innerHTML = "开始爬取...";
const data = await getData();
total = data.total;
const page = Math.ceil(total / pageSize);
saveFile(JSON.stringify(data.rows),`第1页 / 共${page}页`);
loading();
}
async function loading() {
const page = Math.ceil(total / pageSize);
h2.innerHTML = `一共${total}条,${page}页`;
for (let i = 1; i < page; i++) {
pageNum++;
h2.innerHTML = `一共${total}条,${page}页,正在第${i+1}页`;
const data = await getData();
saveFile(JSON.stringify(data.rows),`第${i+1}页 / 共${page}页`);
}
h1.innerHTML = "爬取完毕,已下载数据";
h2.innerHTML = "";
total = 0;
pageNum = 1;
}
async function getData() {
const response = await fetch(api, {
method: "POST",
mode: "cors",
cache: "no-cache",
credentials: "same-origin",
headers: {
"Content-Type": "application/json",
...JSON.parse(headers)
},
body: JSON.stringify({
...JSON.parse(textarea),
"pageSize": pageSize,
"pageNum": pageNum
})
});
return response.json();
}
function saveFile(data,name) {
const blob = new Blob([data], {
type: "application/json"
});
let link = document.createElement("a"); // 创建下载的实体标签
link.href = URL.createObjectURL(blob); // 创建下载的链接
link.download = name + ".json"; // 下载的文件名
link.click(); // 执行下载
URL.revokeObjectURL(link.href); // 下载完成释放掉blob对象
}
</script>
</body>
</html>
开始在小小的网站里面爬呀爬呀爬吧…
拓展
怎么爬取微信小程序的接口?使用Charles 拿到接口、请求头、参数,再回来使用界面爬取
文章来源:https://blog.csdn.net/qq_42618566/article/details/135567283
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java: java.lang.ExceptionInInitializerError com.sun.tools.javac.code.TypeTags
- 使用Notepad++将多行数据合并成一行
- 高并发情况下,数据库与缓存数据不一致问题
- 少走十年弯路!!!webpack详解
- Android 蓝牙相关广播介绍
- gin使用jwt登录验证
- 在VUCA时代,如何运用OKR突破困境?
- 如何在Linux中安装docker
- 云卷云舒:面向业务的智能运维(上)
- 华为产业链之车载激光雷达