【基础】【Python网络爬虫】【4.requests入门】(附大量案例代码)(建议收藏)
Python网络爬虫基础
requests 入门
1. 请求方法(Method)
HTTP请求可以使用多种请求方法,但是爬虫最主要就两种方法:GET和POST方法。
get 请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用 get 请求。post 请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用 post 请求。
? 以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get 方法的请求就一定要改 成post 请求,这个要视情况而定。
2. GET与POST方法
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数都显示在浏览器网址上,即“Get”请求的参数是URL的一部分。 例如: http://www.baidu.com/s?wd=Chinese
- POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据。请求的参数类型包含在“Content-Type”消息头里,指明发送请求时要提交的数据格式。
注意:
- 网站制作者一般不会使用Get方式提交表单,因为有可能会导致安全问题。 比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。并且浏览器会记录历史信息,导致账号不安全的因素存在。
3. 简单爬虫
首先爬虫要引用 requests 内置库
import requests # 数据请求模块 pip install requests
# requests.get 发送一个 https://www.baidu.com/ 的请求
# 服务器接受到请求后会响应数据内容
response = requests.get('https://www.baidu.com/')
# 对象有对象的方法和属性
# .text 获取 Response 对象的文本内容
response.encoding = response.apparent_encoding
print(response.text)
"""
爬虫项目实现步骤:
1. 找数据对应的请求地址
静态网页: 在网页源代码能够找到的数据, 属于静态数据, 对应的地址是当前页面地址导航栏的地址
动态网页
2. 通过代码发送地址请求
3. 提取需要的数据内容, 剔除不需要的
4. 保存数据
"""
''' 示例 - 51游戏首页爬取 '''
# https://code.51.com/jh/tg1/i11/ld2j29ic.html
import requests
# 1.指定url
url = 'https://code.51.com/jh/tg1/i11/ld2j29ic.html'
# 2.发起请求
# get会返回一个响应对象。
response = requests.get(url=url)
# 3.获取响应数据
page_text = response.text # text表示获取字符串形式的响应数据
# print(page_text)
# 4.持久化存储
with open('51game.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
4. url地址构成
url的概念
URL(外文名:Uniform Resource Locator,中文名:统一资源定位符),统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息是指出文件的位置以及浏览器应该怎么处理它。它最初是由蒂姆·伯纳斯·李发明用来作为万维网的地址,现在它已经被万维网联盟编制为互联网标准了。
注意:在Internet上所有资源都有一个独一无二的URL地址,我们可以通过在地址栏中输入URL实现对资源的访问。
url的组成部分
URL格式:
协议类型://服务器地址或IP地址[:端口号]/路径/文件名[参数=值]。
import requests
response = requests.get('https://www.ku6.com/video/feed?pageNo=0&pageSize=40&subjectId=72')
"""
https://www.ku6.com/video/feed?pageNo=0&pageSize=40&subjectId=72
https:// 请求协议类型
www 服务器名字 www(world wide web) 万维网; mail(邮箱服务器名字)
ku6.com 服务器域名
/ 服务器根目录
video/feed?pageNo=0&pageSize=40&subjectId=72 资源路径
url地址/连接地址/api地址/api接口
"""
案例 - 添加请求头发送
import requests
"""
当我们请求不到数据的时候需要考虑, 是不是被反扒了, 是不是被检测到了
"""
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1683638065:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1683638065:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; ap_v=0,6.0; __utmc=30149280; __utmc=223695111; __utma=30149280.1169382564.1682168622.1687178001.1687181253.7; __utmb=30149280.0.10.1687181253; __utmz=30149280.1687181253.7.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1640817040.1683638062.1687178001.1687181253.3; __utmb=223695111.0.10.1687181253; __utmz=223695111.1687181253.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687181253%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DujFBYcF3-z7ymnUy-5xo5XWpfNzul-nJyXI3inL3u3eedAEiRBhQ-FAXcPdn2OYL%26wd%3D%26eqid%3D836185fc0016dde800000006649057c1%22%5D; _pk_ses.100001.4cf6=1',
'Host': 'movie.douban.com',
'Pragma': 'no-cache',
'Referer': 'https://www.baidu.com/link?url=ujFBYcF3-z7ymnUy-5xo5XWpfNzul-nJyXI3inL3u3eedAEiRBhQ-FAXcPdn2OYL&wd=&eqid=836185fc0016dde800000006649057c1',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
# headers=headers 携带请求头模拟请求
response = requests.get('https://movie.douban.com/top250', headers=headers)
html_str = response.text
print(html_str)
"""
一般请求被反扒了, 有如下请求头字段, 一般都需要添加
Origin: 声明资源的起始位置
User-Agent: 浏览器的身份标识
Host: 访问的域名
Referer: 防盗链,告诉服务器从哪个页面跳转过来
Cookies: 用户身份标识, 能不加就不加
"""
5. 查看请求体
import requests
headers = {
'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1683638065:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1683638065:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; ap_v=0,6.0; __utmc=30149280; __utmc=223695111; __utma=30149280.1169382564.1682168622.1687178001.1687181253.7; __utmb=30149280.0.10.1687181253; __utmz=30149280.1687181253.7.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1640817040.1683638062.1687178001.1687181253.3; __utmb=223695111.0.10.1687181253; __utmz=223695111.1687181253.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687181253%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DujFBYcF3-z7ymnUy-5xo5XWpfNzul-nJyXI3inL3u3eedAEiRBhQ-FAXcPdn2OYL%26wd%3D%26eqid%3D836185fc0016dde800000006649057c1%22%5D; _pk_ses.100001.4cf6=1',
'Host': 'movie.douban.com',
'Referer': 'https://www.baidu.com/link?url=ujFBYcF3-z7ymnUy-5xo5XWpfNzul-nJyXI3inL3u3eedAEiRBhQ-FAXcPdn2OYL&wd=&eqid=836185fc0016dde800000006649057c1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
response = requests.get('https://movie.douban.com/top250', headers=headers)
# html_str = response.text
# print(html_str)
"""查看请求体信息"""
# response.request 查看请求体信息
print(response.request.url) # 查看请求体中 url 地址
print(response.request.headers) # 查看请求体中请求头信息, requests模块在请求时,会自动带上常见的请求字段
print(response.request.method) # 查看请求体中请求方法
6.查看响应体
import requests
headers = {
'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1683638065:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1683638065:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; ap_v=0,6.0; __utmc=30149280; __utmc=223695111; __utma=30149280.1169382564.1682168622.1687178001.1687181253.7; __utmb=30149280.0.10.1687181253; __utmz=30149280.1687181253.7.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1640817040.1683638062.1687178001.1687181253.3; __utmb=223695111.0.10.1687181253; __utmz=223695111.1687181253.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687181253%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DujFBYcF3-z7ymnUy-5xo5XWpfNzul-nJyXI3inL3u3eedAEiRBhQ-FAXcPdn2OYL%26wd%3D%26eqid%3D836185fc0016dde800000006649057c1%22%5D; _pk_ses.100001.4cf6=1',
'Host': 'movie.douban.com',
'Referer': 'https://www.baidu.com/link?url=ujFBYcF3-z7ymnUy-5xo5XWpfNzul-nJyXI3inL3u3eedAEiRBhQ-FAXcPdn2OYL&wd=&eqid=836185fc0016dde800000006649057c1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
response = requests.get('https://movie.douban.com/top250', headers=headers)
# html_str = response.text
# print(html_str)
"""查看响应体信息"""
# response.request 查看请求体信息
"""获取响应体数据"""
print(response.text) # 字符串
print(response.content) # 二进制数据, 图片\视频\音频
# print(response.json()) # json数据, 只有规范的json数据才可以用json方法提取, 不然报错(JSONDecodeError)
print(response.headers) # 查看响应体的响应头信息
print(response.encoding) # 指定响应体编码
print(response.apparent_encoding) # 自动识别响应体编码
print(response.cookies)
print(response.cookies.get_dict()) # RequestsCookieJar 转字典
print(response.url) # 获取响应体的url地址
print(response.status_code) # 获取响应体的状态码
案例 - 某厨房首页数据爬取(UA检测)
'''
下厨房首页数据爬取(UA检测)
url:https://www.xiachufang.com/
- 爬虫模拟浏览器主要是模拟请求参数和主要的请求头。
- User-Agent:请求载体的身份标识。
- 使用浏览器发请求,则请求载体就是浏览器
- 使用爬虫程序发请求,则请求载体就是爬虫程序
- 反爬机制:UA检测
- 网站后台会检测请求的载体是不是浏览器,如果是则返回正常数据,不是则返回错误数据。
- 反反爬机制:UA伪装
- 将爬虫发起请求的User-Agent伪装成浏览器的身份
'''
import requests
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 1.指定url
url = 'https://www.xiachufang.com/'
# 2.发起请求
# 携带了指定的请求头进行的请求发送
response = requests.get(url=url, headers=headers)
# 3.获取响应数据
page_text = response.text
# 4.持久化存储
with open('cook.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
7. 设置响应体编码
import requests
response = requests.get('http://www.pcbaby.com.cn/')
## 方式1 :自动识别响应体编码
response.encoding = response.apparent_encoding
# 方式2 :手动指定编码识别
response.encoding = 'gb2312'
html_str = response.text
print(html_str)
8. Json数据
网址 :www.json.cn 可以翻译 Json 数据信息
"""json数据"""
# json数据是目前主流的数据交换格式 (结构清晰, 方便取值)
# 形式: 外层 {} [] 包裹 嵌套数据
# {"字段1": "值1",字段2: {嵌套字段1: 嵌套字段值1}, {}, {} ...}
# json数据和字典非常像, 但是有区别, 引号, json数据必须用双引号
"""
在json数据中, 值必须是以下数据类型
字符串
数字
对象(json对象)<嵌套形式>
数组
布尔值
null --> 字符串
"""
import requests
response = requests.get('https://www.ku6.com/video/feed?pageNo=0&pageSize=40&subjectId=72')
print(response.json())
# # 通过 json() 提取json数据之后, 会在底层经过数据转换, 转换成一个对象
print(type(response.json()))
9. 二进制下载数据
import requests
response = requests.get('https://i.hexuexiao.cn/up/da/75/47/f59543039ce27d69ef5d25b5a04775da.jpg')
# .content --> 提取响应体二进制数据
img_data = response.content
print(img_data)
# 图片\音频\视频
with open('a.jpg', mode='wb') as f:
f.write(img_data)
案例 - 请求猫眼
"""
目标地址:https://m.maoyan.com/asgard/board/4
要求:
1、请求到目标网址数据,需要在请求到的数据中看到当前页面所有的电影名字、主演、上映时间、评分等信息
2、请列举在请求不到数据时,需要添加几个常见请求头字段(课程讲过)
请在下方编写代码
"""
import requests
headers = {
'Cookie': 'iuuid=F5783590DF7F11ED9B25CD5E5234694FA2DAA684142046EEA9F6AB456B2AFF02; _lxsdk_cuid=1879ededf23c8-0483e83e302f2e-26031b51-1fa400-1879ededf23c8; _lxsdk=F5783590DF7F11ED9B25CD5E5234694FA2DAA684142046EEA9F6AB456B2AFF02; ci=70%2C%E9%95%BF%E6%B2%99; ci.sig=6ddYdqOybjnPiJJMwTWmS44rF4o; ci=70%2C%E9%95%BF%E6%B2%99; ci.sig=6ddYdqOybjnPiJJMwTWmS44rF4o; ci=70%2C%E9%95%BF%E6%B2%99; ci.sig=6ddYdqOybjnPiJJMwTWmS44rF4o; _lxsdk_s=188ddc29cb4-793-726-aed%7C%7CNaN; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1687347699; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1687347699',
'Host': 'm.maoyan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# headers=headers 在请求的时候携带请求头伪装
response = requests.get('https://m.maoyan.com/asgard/board/4', headers=headers)
response.encoding = response.apparent_encoding
print(response.text)
"""
User-Agent: 浏览器的身份标识
Host: 访问服务器的域名
referer: 防盗链,告诉服务器此次请求是从哪个页面跳转过来的
origin: 资源地址的地址位置
cookies: 用户身份字段
"""
案例 - 获取 Json 信息
"""
目标网址:https://www.ku6.com/video/feed?pageNo=0&pageSize=40&subjectId=76
发送 GET 请求
要求:
1、请求上述网址的数据
2、按照要求提取以下字段信息
title、
picPath、
playUrl
提取下来用 print() 函数打印即可
请在下方编写代码
"""
import pprint
import requests
response = requests.get('https://www.ku6.com/video/feed?pageNo=0&pageSize=40&subjectId=76')
json_data = response.json()
print(json_data)
# pprint.pprint(json_data)
for res in json_data['data']:
title = res['title']
picPath = res['picPath']
playUrl = res['playUrl']
print(title, picPath, playUrl)
案例 - 保存二进制数据
"""
目标网址:https://ibaotu.com/sucai/19838349.html
要求:
1、在上述目标网址中找到视频的数据包
2、用requests模块模拟请求视频数据并且保存下来
请在下方编写代码
"""
import requests
url = 'https://video-qn.ibaotu.com/19/83/83/49Z888piC4I8.mp4'
response = requests.get(url)
video_data = response.content
file_name = url.split('/')[-1]
# 准备保存视频的文件名字
with open(file_name, mode='wb') as f:
f.write(video_data)
10. params 关键字参数(查询参数)
requests 模块允许你使用 params 关键字参数,以一个字典来提供这些参数。
举例来说,如果你想传递 key1=value1 和 key2=value2 到 httpbin.org/get ,那么你可以使用如下代码:
import requests
params = {'q': '风景', 'src': 'srp'}
response = requests.get("https://image.so.com/i", params=params)
# 通过打印输出该 URL,你能看到 URL 已被正确编码:
print(response.url)
# 打印结果
https://image.so.com/i?q=%E9%A3%8E%E6%99%AF&src=srp
在url地址中默认是不支持中文字符的,所以在请求中会把中文字符转化成url编码形式
同样的查询参数可以在浏览器抓包工具中找到,位于Headers栏目下的Query String Parameters中,如下图所示:

import requests
headers = {
'Cookie': 'iuuid=F5783590DF7F11ED9B25CD5E5234694FA2DAA684142046EEA9F6AB456B2AFF02; _lxsdk_cuid=1879ededf23c8-0483e83e302f2e-26031b51-1fa400-1879ededf23c8; _lxsdk=F5783590DF7F11ED9B25CD5E5234694FA2DAA684142046EEA9F6AB456B2AFF02; ci=70%2C%E9%95%BF%E6%B2%99; ci.sig=6ddYdqOybjnPiJJMwTWmS44rF4o; ci=70%2C%E9%95%BF%E6%B2%99; ci.sig=6ddYdqOybjnPiJJMwTWmS44rF4o; ci=70%2C%E9%95%BF%E6%B2%99; ci.sig=6ddYdqOybjnPiJJMwTWmS44rF4o; _lxsdk_s=188ddc29cb4-793-726-aed%7C%7CNaN; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1687347699; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1687347699',
'Host': 'm.maoyan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
response = requests.get(url='https://m.maoyan.com/asgard/board/4', headers=headers)
print(response.url)
"""
method: 请求方法 get post
url: 请求网址的关键字
params: (可选参数) 指定查询参数
data: (可选参数) 指定请求参数
json: (可选参数) 指定json数据形式发送请求
headers: (可选参数) 请求头关键字参数
cookies: (可选参数) 请求的时候指定用户身份标识
proxies: (可选参数) 使用代理请求的关键字
timeout: (可选参数) 指定请求的时间, 单位/秒
allow_redirects: (可选参数) 是否允许重定向, 300左右
verify: (可选参数) 控制是否验证网站证书
files: (可选参数) 上传文件
auth: (可选参数) 权限认证
stream: (可选参数) 是否是数据流传输的数据
"""
11. url地址中的参数
- 使用requests模块发送请求之前,我们就要回顾之前学习到的url(统一资源定位符)。
- 在你拿到数据所在的url地址之后,发送网络请求时,请求的url中包含两种地址参数:
查询参数和请求参数。
查询参数
当我们爬一些特殊网址时,请求的url中会有一些特殊的参数,例如以下站点:

这种是 URL 的查询参数。前面是网址,? 后面的二值性数据,就是查询参数。
URL 的查询字符串(query string)传递某种数据。如果你是手工构建 URL,也就是通过拼接字符串构造的URL。那么数据会以键/值对的形式置于 URL 中,跟在一个问号的后面。
例如:
https://image.so.com/i?q=%E9%A3%8E%E6%99%AF&src=srp
# https://pic.sogou.com/pics?query=%E8%9C%A1%E7%AC%94%E5%B0%8F%E6%96%B0&mood=7&dm=0&mode=1
"""
查询参数:
在地址中如果与查询参数, 那么就是?后面的部分, 是属于查询参数
? 前面是请求地址, 后面是一系列的查询参数
& 隔开每一个查询参数
所有查询参数都是二值型的数据, key=value
"""
import requests
url = 'https://pic.sogou.com/pics?'
params = {
'query': '蜡笔小新',
'mood': '7',
'dm': '0',
'mode': '1'
}
# params 指定查询参数
# ? 可加可不加
response = requests.get(url=url, params=params)
print(response.request.url)
# https://pic.sogou.com/pics?query=%E8%9C%A1%E7%AC%94%E5%B0%8F%E6%96%B0&mood=7&dm=0&mode=1
"""
在http协议中, 默认不支持中文编码, 如果请求地址中包含中文, 会自动进行url编码
url编码: 由 % + 数字 + 字母
"""
# 手动转化url编码
# requests.utils.quote 对中文进行url编码
print(requests.utils.quote('蜡笔小新'))
# requests.utils.unquote 对中文进行url解码
print(requests.utils.unquote('%E8%9C%A1%E7%AC%94%E5%B0%8F%E6%96%B0'))
''' 示例1 - 51游戏搜索 '''
# 注意:在浏览器的地址栏中网址,网址?后面的内容就是请求的参数(请求参数)
import requests
# 1.指定url
params = { # 字典是用于封装请求参数
'q': '传奇'
}
url = 'https://game.51.com/search/action/game/'
# 2.发起请求
# get是基于指定的url和携带了固定的请求参数进行请求发送
response = requests.get(url=url, params=params)
# 3.获取响应数据
page_text = response.text # text表示获取字符串形式的响应数据
# print(page_text)
# 4.持久化存储
with open('传奇.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
''' 示例2 - 51游戏中任何游戏对应的搜索结果页面数据 '''
import requests
# 1.指定url
game_title = input('enter a game name:')
params = { # 字典是用于封装请求参数
'q': game_title
}
url = 'https://game.51.com/search/action/game/'
# 2.发起请求
# get是基于指定的url和携带了固定的请求参数进行请求发送
response = requests.get(url=url, params=params)
# 3.获取响应数据
page_text = response.text # text表示获取字符串形式的响应数据
# print(page_text)
# 4.持久化存储
fileName = game_title + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
案例 - 某厨房的菜谱搜索(多个请求参数)
'''
通过抓包工具的分析发现,搜索菜谱的数据包有两个请求参数:
- keyword:搜索的关键字
- cat:1001固定形式
'''
import requests
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
title = input('请输入菜名:')
# 请求参数
params = {
'keyword': title,
'cat': '1001'
}
# 1.指定url
url = 'https://www.xiachufang.com/search/'
# 2.发起请求
response = requests.get(url=url, headers=headers, params=params)
# 处理乱码
response.encoding = 'utf-8' # gbk
# 3.获取响应数据
page_text = response.text
# 4.持久化存储
fileName = title + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
案例 - 某豆瓣电影(动态加载数据爬取)
'''
爬取网址 :https://movie.douban.com/typerank?type_name=%E7%88%B1%E6%83%85&type=13&interval_id=100:90&action=
将豆瓣电影中的电影名称和电影的评分进行爬取
测试:直接使用浏览器地址栏中的url,进行请求发送查看是否可以爬取到电影详情数据?
'''
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'https://movie.douban.com/typerank?type_name=%E7%88%B1%E6%83%85&type=13&interval_id=100:90&action='
response = requests.get(url=url, headers=headers)
page_text = response.text
with open('douban.html', 'w') as fp:
fp.write(page_text)
经过测试发现,我们爬取到的数据并没有包含电影详情数据,why?
动态加载数据
'''
- 在一个网页中看到的数据,并不一定是通过浏览器地址栏中的url发起请求请求到的。如果请求不到,一定是基于其他的请求请求到的数据。
- 动态加载数据值的就是:
不是直接通过浏览器地址栏的url请求到的数据,这些数据叫做动态加载数据。
- 如何获取动态加载数据?
- 确定动态加载的数据是基于哪一个数据包请求到的?
- 数据包数据的全局搜索:
- 点击抓包工具中任何一个数据包
- control+f进行全局搜索(弹出全局搜索框)
- 目的:定位动态加载数据是在哪一个数据包中
- 定位到动态加载数据对应的数据包,模拟该数据包进行请求发送即可:
- 从数据包中提取出:
- url
- 请求参数
'''
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
params = {
"type": "13",
"interval_id": "100:90",
"action": "",
"start": "0",
"limit": "20"
}
url = 'https://movie.douban.com/j/chart/top_list'
response = requests.get(url=url, headers=headers, params=params)
# json()可以获取json格式的响应数据,并且直接对json格式的响应数据进行反序列化
data_list = response.json()
fp = open('movie.txt', 'w')
for dic in data_list:
title = dic['title']
score = dic['score']
print(title, score)
fp.write(title + ':' + score + '\n')
fp.close()
案例 - 搜某图片采集
"""
ajax 异步加载
在不加载整个网页的情况下, 对页面进行局部刷新
页面上半部分数据不会刷新, 下半部分加载新数据
网站动态数据渲染:
页面第一页数据做了静态数据渲染
后续页数的数据统一做动态渲染
一般情况下可以按照动态数据包翻页的规律, 构建第一页请求
"""
import requests
def get_params(page):
"""构建请求参数的函数"""
return {
'mood': '7',
'dm': '0',
'mode': '1',
'start': str(page),
'xml_len': '48',
'query': '蜡笔小新'
}
url = 'https://pic.sogou.com/napi/pc/searchList'
for i in range(0, 97, 48):
# print(i)
params = get_params(i)
response = requests.get(url=url, params=params)
json_data = response.json()
list_data = json_data['data']['items']
for data in list_data:
img_url = data['picUrl']
print(img_url)
案例 - 某德基(post请求)
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
params = {'op': 'keyword'} # 查询参数
data = { # 请求参数
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': '1',
'pageSize': '10'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
# data是构建post请求的请求参数关键字
response = requests.post(url=url, params=params, data=data, headers=headers)
json_data = response.json()
print(json_data)
list_data = json_data['Table1']
for res in list_data:
storeName = res['storeName']
addressDetail = res['addressDetail']
pro = res['pro']
print(storeName, addressDetail, pro)
"""
注意事项:
1. 浏览器中地址导航栏只能发送get请求
2. post请求还会有另一种请求参数<Form Data> 和 <Request Payload> --> 以json数据提交的请求参数, 用json关键字传递
"""
案例 - 某德基(post请求)爬取多页面
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
for page in range(1, 6):
data = {
"cname": "",
"pid": "",
"keyword": "天津",
"pageIndex": str(page), # 设置打印页数
"pageSize": "10"
}
# post请求携带请求参数使用data这个参数
response = requests.post(url=url, headers=headers, data=data)
data = response.json()
for dic in data['Table1']:
city = dic['cityName']
address = dic['addressDetail']
print(city, address)
案例 - 图片数据爬取
# 方式1:
import requests
url = 'https://img0.baidu.com/it/u=540025525,3089532369&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500'
response = requests.get(url=url)
# content获取二进制形式的响应数据
img_data = response.content
with open('1.jpg', 'wb') as fp:
fp.write(img_data)
# 方式2
from urllib import request
url = 'https://img0.baidu.com/it/u=540025525,3089532369&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500'
# urlretrieve可以将参数1表示的图片地址请求并且保存到参数2的目录中
request.urlretrieve(url, '2.jpg')
#### 爬取图片的时候需要做UA伪装使用方式1,否则使用方式2 ####
12. data 关键字参数(请求参数)
requests模块中发送POST请求也是比较容易的操作,要实现这个,只需简单地传递一个字典给data参数。你的数据字典在发出请求时会自动编码为表单形式:
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post("http://httpbin.org/post", data=data)
当然Requests中的post方法只是相对于get方法多了一个data参数,其他参数都是类似的,例如我们也可以为post中的网址添加查询字符串 params 参数,也可以像get方法一样添加 headers 参数等。
请求参数
- 请求参数和查询参数有本质的区别。请求参数一般是在发送post请求,向服务器提交表单数据请求的时候携带的参数。
- 注意:url地址中不会显示请求参数,只会显示查询参数。
- 请求参数在浏览器抓包工具中,位于Headers栏目下的Form Data中
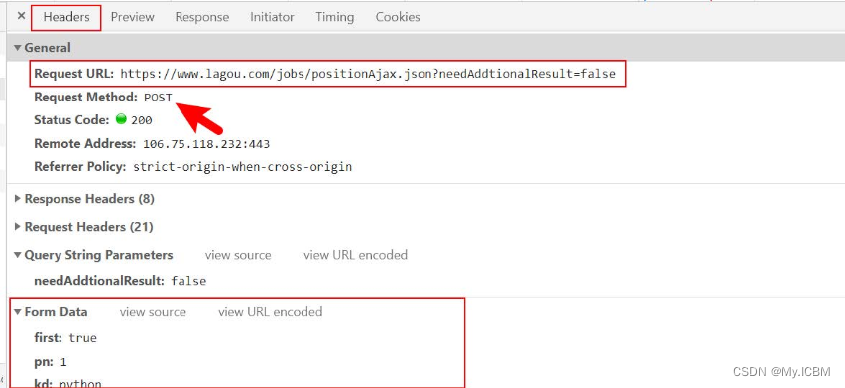
13. cookies 关键字
学习http协议的时候,请求体字段中就讲述过cookies字段,这个字段代表用户身份的标识,一般平台通过这个字段存储用户信息,包括并不限于用户名、密码、登陆时间等等。一般cookies信息都是二值型的,即key=value形式,非常像字典的构造形式。每一个key=value的信息,都代表用户的片段信息,很多个key=value片段构成一个完整的cookies字段,如下图所示:
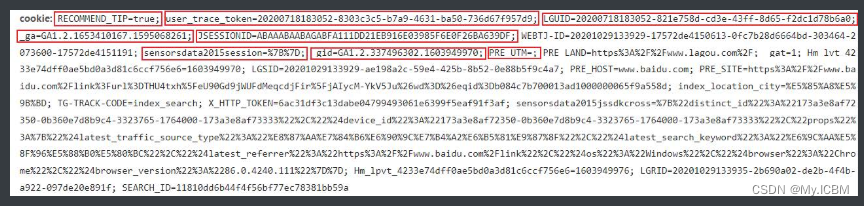
- 值得注意的是,cookies中所有片段信息,有浏览器自动生成的,也有服务器在响应数据的时候给你生成的。一旦服务给你生成了cookie片段,那么大概率就会针对这些片段进行校验,验证你的用户身份,从而决定是否返回数据给你。相反来说浏览器自动为我们生成的cookie片段对我们代码请求影响不大,因为服务器往往会校验自己生成的cookie片段,对于浏览器自动生成的cookie片段不会校验。
- 在requests模块中发送带cookies字段的请求也是比较容易的操作,要实现这个,只需简单地传递一个字典给cookies关键字即可:
import requests
url = 'https://fanyi.baidu.com/v2transapi?from=zh&to=en'
headers = {
'Acs-Token': '1687354513445_1687354530324_U0QUCd0KA/F7BYp74tXcgnoFsNtOOxo4iufv+Hk5xXqn2+frnr0XUBVQuvTA3dfcUNYPfwpE/Y/JKtFNRsVrPchR4jO1sLxlmyw0hvh3usx51exIBKNRgH4NQXBDqAt3YJadXkNDjTR67nCTZiw+RJk7dF5HUYF5tJQ2b6P7MOd74rkMTn+xiwSraonXITV1rfLX6Pljrf7BCAACg8KuPEJplI1HlqnRHpoq54OKlcGiWXm2ZWfAcq4EVmqb1nVSge61u6U85j/n7R3JJ4LA96Vw0kcKtFi5X8GAw2SHCZ1fAZREBFeYdhG6fXVEZP+e6mkHJn/yUmb3IUb+GxtEhS1alaQMFv9QQZSBx6tXbfW6ncLHgcZfcDTqoKWSe3tdX39s1qnOEoWGvwLFFe/XMszJzUdMuOhndbQPdjkofy58aIlMTJErOTeELJ+21UOigR2VuwxiD/k9oI7vmMH0UUYzjVqojZcGNU2GrWMcfto=',
# 'Cookie': "BIDUPSID=A8D9EA340531252B16551CBD43A8D395; PSTM=1681976911; BAIDUID=A8D9EA340531252BDEF2C13A73AFA5E7:FG=1; APPGUIDE_10_0_2=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; H_WISE_SIDS=131862_114552_216844_213346_214803_219942_110085_243887_244712_249892_256348_256447_256739_254317_257586_257996_258372_258375_230288_259102_259287_258772_234207_234295_253022_260335_260806_259299_253631_261575_261718_261459_261983_259782_260440_261793_259629_236312_262490_262452_261869_262607_262677_262597_262604_249411_259519_259948_262743_262746_262913_263190_256998_263221_263306_263279_243615_263343_261683_263434_254299_261411_263584_257289_262439_262533_263644_262408_262910_257169_262289_263906_263363_256419_264175_264089_264228_257442_256225_262260_255224_264018_264368_259558_256083_264383_264423_264452_264285_256152_264626_264246_258698_264749_261934_264820_264136_261035_261663; H_PS_PSSID=38516_36550_38686_38860_38793_38841_38581_38802_38828_38840_38640_26350; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=A8D9EA340531252BDEF2C13A73AFA5E7:FG=1; delPer=0; PSINO=6; BA_HECTOR=ah2g2ka48k0g8h2h00a4842h1i95r4t1p; ZFY=CMMricp5SfogOfi1RswFaP4NBZN6t5zy:Axurblw8al4:C; BCLID=8504214758825411246; BCLID_BFESS=8504214758825411246; BDSFRCVID=TO8OJexroG0ZmSbfuwStIGta5LweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; BDSFRCVID_BFESS=TO8OJexroG0ZmSbfuwStIGta5LweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tRAOoC_-tDvDqTrP-trf5DCShUFsLU4OB2Q-XPoO3KJADfOPbRob0n0PQpOKtx7f5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPr9QgbjahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjDMDTJy3j; H_BDCLCKID_SF_BFESS=tRAOoC_-tDvDqTrP-trf5DCShUFsLU4OB2Q-XPoO3KJADfOPbRob0n0PQpOKtx7f5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPr9QgbjahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjDMDTJy3j; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1687354513; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1687354513; ab_sr=1.0.1_NDJjZTI3ZGQwZjJhN2I2YThjMWMxNDgxNWJhOGM5YTEwMjYwYWM0NDU3Mjk0Y2MxZTAyNWE0MzIyNDlhYjJmYjQ5NDUxNzEzOTI4YmIyZjUyNDFiNjFkM2Q0ZTYyMjZjMGU1ZTU3MDFiMTNhMWU5NTY2NDdlYWExZWEyZDZiMWNkNGVjMTExNTQyM2MyNzYxYThiNzAzYmUxNTAxZGI2NA==",
'Host': 'fanyi.baidu.com',
'Origin': 'https://fanyi.baidu.com',
'Referer': 'https://fanyi.baidu.com/?aldtype=16047',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
data = {
'from': 'zh',
'to': 'en',
'query': '你好',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '232427.485594',
'token': '351b986af9e8a703056ff2f022cdf830',
'domain': 'common',
'ts': '1687354530307',
}
# cookies = {'Cookie': 'BIDUPSID=A8D9EA340531252B16551CBD43A8D395; PSTM=1681976911; BAIDUID=A8D9EA340531252BDEF2C13A73AFA5E7:FG=1; APPGUIDE_10_0_2=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; H_WISE_SIDS=131862_114552_216844_213346_214803_219942_110085_243887_244712_249892_256348_256447_256739_254317_257586_257996_258372_258375_230288_259102_259287_258772_234207_234295_253022_260335_260806_259299_253631_261575_261718_261459_261983_259782_260440_261793_259629_236312_262490_262452_261869_262607_262677_262597_262604_249411_259519_259948_262743_262746_262913_263190_256998_263221_263306_263279_243615_263343_261683_263434_254299_261411_263584_257289_262439_262533_263644_262408_262910_257169_262289_263906_263363_256419_264175_264089_264228_257442_256225_262260_255224_264018_264368_259558_256083_264383_264423_264452_264285_256152_264626_264246_258698_264749_261934_264820_264136_261035_261663; H_PS_PSSID=38516_36550_38686_38860_38793_38841_38581_38802_38828_38840_38640_26350; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=A8D9EA340531252BDEF2C13A73AFA5E7:FG=1; delPer=0; PSINO=6; BA_HECTOR=ah2g2ka48k0g8h2h00a4842h1i95r4t1p; ZFY=CMMricp5SfogOfi1RswFaP4NBZN6t5zy:Axurblw8al4:C; BCLID=8504214758825411246; BCLID_BFESS=8504214758825411246; BDSFRCVID=TO8OJexroG0ZmSbfuwStIGta5LweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; BDSFRCVID_BFESS=TO8OJexroG0ZmSbfuwStIGta5LweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tRAOoC_-tDvDqTrP-trf5DCShUFsLU4OB2Q-XPoO3KJADfOPbRob0n0PQpOKtx7f5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPr9QgbjahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjDMDTJy3j; H_BDCLCKID_SF_BFESS=tRAOoC_-tDvDqTrP-trf5DCShUFsLU4OB2Q-XPoO3KJADfOPbRob0n0PQpOKtx7f5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPr9QgbjahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjDMDTJy3j; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1687354513; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1687354513; ab_sr=1.0.1_NDJjZTI3ZGQwZjJhN2I2YThjMWMxNDgxNWJhOGM5YTEwMjYwYWM0NDU3Mjk0Y2MxZTAyNWE0MzIyNDlhYjJmYjQ5NDUxNzEzOTI4YmIyZjUyNDFiNjFkM2Q0ZTYyMjZjMGU1ZTU3MDFiMTNhMWU5NTY2NDdlYWExZWEyZDZiMWNkNGVjMTExNTQyM2MyNzYxYThiNzAzYmUxNTAxZGI2NA=='}
# 将每个cookies片段构建键值对
cookies = {
'BAIDUID': 'A8D9EA340531252BDEF2C13A73AFA5E7:FG=1',
'BAIDUID_BFESS': 'A8D9EA340531252BDEF2C13A73AFA5E7:FG=1',
'ZFY': 'CMMricp5SfogOfi1RswFaP4NBZN6t5zy:Axurblw8al4:C',
'BIDUPSID': 'A8D9EA340531252B16551CBD43A8D395',
'PSTM': '1681976911',
'APPGUIDE_10_0_2': '1',
'REALTIME_TRANS_SWITCH': '1',
'FANYI_WORD_SWITCH': '1',
'HISTORY_SWITCH': '1',
'SOUND_SPD_SWITCH': '1',
'SOUND_PREFER_SWITCH': '1',
'H_WISE_SIDS': '131862_114552_216844_213346_214803_219942_110085_243887_244712_249892_256348_256447_256739_254317_257586_257996_258372_258375_230288_259102_259287_258772_234207_234295_253022_260335_260806_259299_253631_261575_261718_261459_261983_259782_260440_261793_259629_236312_262490_262452_261869_262607_262677_262597_262604_249411_259519_259948_262743_262746_262913_263190_256998_263221_263306_263279_243615_263343_261683_263434_254299_261411_263584_257289_262439_262533_263644_262408_262910_257169_262289_263906_263363_256419_264175_264089_264228_257442_256225_262260_255224_264018_264368_259558_256083_264383_264423_264452_264285_256152_264626_264246_258698_264749_261934_264820_264136_261035_261663',
'H_PS_PSSID': '38516_36550_38686_38860_38793_38841_38581_38802_38828_38840_38640_26350',
'BDORZ': 'B490B5EBF6F3CD402E515D22BCDA1598',
'delPer': '0',
'PSINO': '6',
'BA_HECTOR': 'ah2g2ka48k0g8h2h00a4842h1i95r4t1p',
'BCLID': '8504214758825411246',
'BCLID_BFESS': '8504214758825411246',
'BDSFRCVID': 'TO8OJexroG0ZmSbfuwStIGta5LweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'BDSFRCVID_BFESS': 'TO8OJexroG0ZmSbfuwStIGta5LweG7bTDYrEOwXPsp3LGJLVFakFEG0Pts1-dEu-S2OOogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF': 'tRAOoC_-tDvDqTrP-trf5DCShUFsLU4OB2Q-XPoO3KJADfOPbRob0n0PQpOKtx7f5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPr9QgbjahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjDMDTJy3j',
'H_BDCLCKID_SF_BFESS': 'tRAOoC_-tDvDqTrP-trf5DCShUFsLU4OB2Q-XPoO3KJADfOPbRob0n0PQpOKtx7f5mkf3fbgy4op8P3y0bb2DUA1y4vp0toW3eTxoUJ2-KDVeh5Gqq-KXU4ebPRiWPr9QgbjahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHjDMDTJy3j',
'Hm_lvt_64ecd82404c51e03dc91cb9e8c025574': '1687354513',
'Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574': '1687354513',
'ab_sr': '1.0.1_NDJjZTI3ZGQwZjJhN2I2YThjMWMxNDgxNWJhOGM5YTEwMjYwYWM0NDU3Mjk0Y2MxZTAyNWE0MzIyNDlhYjJmYjQ5NDUxNzEzOTI4YmIyZjUyNDFiNjFkM2Q0ZTYyMjZjMGU1ZTU3MDFiMTNhMWU5NTY2NDdlYWExZWEyZDZiMWNkNGVjMTExNTQyM2MyNzYxYThiNzAzYmUxNTAxZGI2NA==',
}
# cookies关键字
response = requests.post(url=url, data=data, headers=headers, cookies=cookies)
json_data = response.json()
print(json_data)
# 请求会校验用户cookies字段
"""
携带cookies的方式:
1. 放到请求头里面
2. 可以通过构建cookies字典用cookies关键字请求
3. 将cookies的每一个片段信息构建键值对, 通过cookies关键字请求
"""
cookie 概述
当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就是cookie,它是Internet站点创建的,为了辨别用户身份而储存在用户本地终端上的数据,cookie大部分都是加密的,cookie存在与缓存中或者硬盘中,在硬盘中的是一些文本文件,当你访问该网站时,就会读取对应的网站的cookie信息,cookie有效地提升了用户体验,一般来说,一旦将cookie保存在计算机上,则只有创建该cookie的网站才能读取它
cookie 的由来
大家都知道HTTP协议是无状态的。
- 状态可以理解为客户端和服务器在某次会话中产生的数据,那无状态的就以为这些数据不会被保留。每当有新的请求发送时,就会有对应的新响应产生。协议本身并不保留之前一切的请求或响应的相关信息。
- 一句有意思的话来描述就是人生只如初见,对服务器来说,每次的请求都是全新的,及时同一个客户端发起的多个请求间。随着Web的不断发展,因无状态而导致业务处理变得棘手的情况增多,因此我们需要解决这个问题,也就是说要让http可以“保持状态”,那么Cookie就是在这样一个场景下诞生。
什么是 cookie
- cookie的本质就是一组数据(键值对的形式存在)
- 是由服务器创建,返回给客户端,最终会保存在客户端浏览器中。
- 如果客户端保存了cookie,则下次再次访问该服务器,就会携带cookie进行网络访问。
- 首先来讲,cookie是浏览器的技术,Cookie具体指的是一段小信息,它是服务器发送出来存储在浏览器上的一组组键值对,可以理解为服务端给客户端的一个小甜点,下次访问服务器时浏览器会自动携带这些键值对,以便服务器提取有用信息。
记住:cookie表示的键值对数据是由服务器创建,且存储在客户端浏览器中。
cookie 的原理(重点)
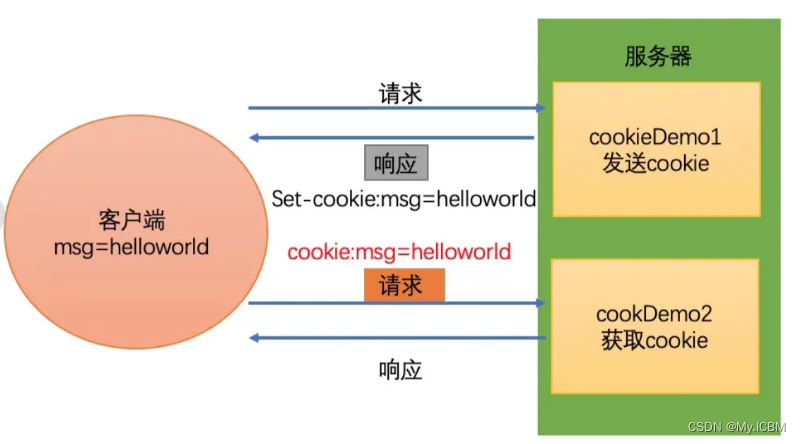
cookie的工作原理是:
- 浏览器访问服务端,带着一个空的cookie,然后由服务器产生内容,浏览器收到相应后保存在本地;
- 当浏览器再次访问时,浏览器会自动带上Cookie,这样服务器就能通过Cookie的内容来判断这个是“谁”了。
- cookie的内容是有服务器自主设计的,客户端无法干涉!
cookie的规范
- Cookie大小上限为4KB;
- 一个服务器最多在客户端浏览器上保存20个Cookie;
- 一个浏览器最多保存300个Cookie,因为一个浏览器可以访问多个服务器。
- 上面的数据只是HTTP的Cookie规范,但在浏览器大战的今天,一些浏览器为了打败对手,为了展现自己的能力起见,可能对Cookie规范“扩展”了一些,例如每个Cookie的大小为8KB,最多可保存500个Cookie等!但也不会出现把你硬盘占满的可能!
- 注意,不同浏览器之间是不共享Cookie的。也就是说在你使用IE访问服务器时,服务器会把Cookie发给IE,然后由IE保存起来,当你在使用FireFox访问服务器时,不可能把IE保存的Cookie发送给服务器。
案例- 某球网中的咨询数据
'''
- url:https://xueqiu.com/,需求就是爬取热帖内容
- 经过分析发现帖子的内容是通过ajax动态加载出来的,因此通过抓包工具,定位到ajax请求的数据包,从数据包中提取:
- url:https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=311519&size=15
- 请求方式:get
- 请求参数:拼接在了url后面
'''
import requests
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36',
}
url = 'https://xueqiu.com/statuses/hot/listV2.json'
param = {
"since_id": "-1",
"max_id": "311519",
"size": "15",
}
response = requests.get(url=url, headers=headers, params=param)
data = response.json()
print(data)
#### 发现没有拿到我们想要的数据 ####
'''
- 分析why?
- 切记:只要爬虫拿不到你想要的数据,唯一的原因是爬虫程序模拟浏览器的力度不够!一般来讲,模拟的力度重点放置在请求头中!
- 上述案例,只需要在请求头headers中添加cookie即可!
- 爬虫中cookie的处理方式(两种方式):
- 手动处理:将抓包工具中的cookie赋值到headers中即可
- 缺点:
- 编写麻烦
- cookie通常都会存在有效时长
- cookie中可能会存在实时变化的局部数据
- 自动处理
- 基于session对象实现自动处理cookie。
- 1.创建一个空白的session对象。
- 2.需要使用session对象发起请求,请求的目的是为了捕获cookie
- 注意:如果session对象在发请求的过程中,服务器端产生了cookie,则cookie会自动存储在session对象中。
- 3.使用携带cookie的session对象,对目的网址发起请求,就可以实现携带cookie的请求发送,从而获取想要的数据。
- 注意:session对象至少需要发起两次请求
- 第一次请求的目的是为了捕获存储cookie到session对象
- 后次的请求,就是携带cookie发起的请求了
'''
import requests
# 1.创建一个空白的session对象
session = requests.Session()
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36',
}
main_url = 'https://xueqiu.com/'
# 2.使用session发起的请求,目的是为了捕获到cookie,且将其存储到session对象中
session.get(url=main_url, headers=headers)
url = 'https://xueqiu.com/statuses/hot/listV2.json'
param = {
"since_id": "-1",
"max_id": "311519",
"size": "15",
}
# 3.就是使用携带了cookie的session对象发起的请求(就是携带者cookie发起的请求)
response = session.get(url=url, headers=headers, params=param)
data = response.json()
print(data)
案例 - 17k图书网
#### 获取https://passport.17k.com/中的书架页面里的图书信息 ####
import pprint
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
# 发送登陆处理接口的url地址
url = 'https://passport.17k.com/ck/user/login'
# 传递给服务器端的数据
data = {
'loginName': '15027900535',
'password': 'bobo328410948'
}
session = requests.Session()
response = session.post(url, headers=headers, data=data)
pprint.pprint(response.text)
# 抓取登录后的数据:书架页面
# url = 'https://user.17k.com/www/bookshelf/'
# 书架页面的图书信息
url = 'https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919'
res = session.get(url, headers=headers)
# 获取书架上的所有书籍
shelf_books = res.json()
pprint.pprint(shelf_books)
14. verify 关键字
数字证书(俗称ca证书,以下简称ca证书)为实现双方安全通信提供了电子认证。在因特网、公司内部网或外部网中,使用数字证书实现身份识别和电子信息加密。数字证书中含有密钥对(公钥和私钥)所有者的识别信息,通过验证识别信息的真伪实现对证书持有者身份的认证。- 目前各大网站基本有自己的ca证书,但是不排除有的网站为了节约网站建设开销并没有购买ca证书。又因为requests模块在发送网络请求的时候,默认会验证ca证书。如果当前网站没有ca证书,那么就会报出如下的错误:
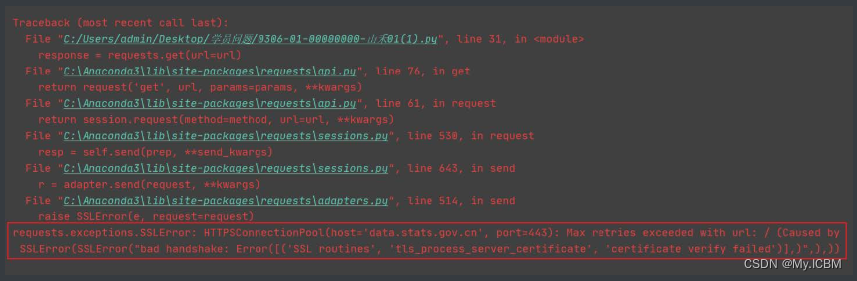
如果出现上述错误,那么我们可以用verify关键字参数,在请求的时候不验证网站的ca证书
response = requests.get("url", verify=False)
如果加了verify=False这个关键字参数,使用requests模块发送请求的时候会给你弹出一个警告,警告你当前的请求可能不安全,如下图所示:

这个警告对于后面的代码逻辑没有影响,有强迫症的可以考虑加入以下代码忽略警告:
import requests
import urllib3
# urllib3.disable_warnings() # 忽略关闭认证ca证书之后引发的警告
requests.packages.urllib3.disable_warnings()
url = 'https://data.stats.gov.cn/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# verify=False 使用requests模块发送请求的时候,不验证ca证书,默认会验证(verify=True)
response = requests.post(url=url, headers=headers, verify=False)
data = response.text
print(data)
"""
网站没有证书使用requests模块请求会报错 --> requests.exceptions.SSLError
"""
15. timeout 关键字
如果对于requests模块发送的网络请求,请求数据的速度太慢,达不到你的要求。那么你可以考虑加上timeout关键字参数对于请求数据的时间做出限制,如下所示:
import requests
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# timeout 设置一个请求获取数据的时间, 如果超过这个时间就会报错, 报错可以用异常捕获解决
response = requests.get(url=url, headers=headers, timeout=2)
data = response.text
print(data)
# 限制时间单位以秒为单位,超过这个时间限制,程序报错。对于报错可以用异常捕获解决。
16. allow_redirects关键字
对于一些重定向的网络请求,比如登陆成功后跳转到用户个人页面。如果对于当前请求你不想要重定向,就需要当前地址数据,那么可以添加allow_redirects=False关键字,阻止当前请求的重定向。如下所示:
import requests
url = 'http://github.com/'
# allow_redirects默认是True, 自动重定向; 如果设置为False, 那么会阻止重定向
response = requests.get(url=url, allow_redirects=False)
print(response.request.url)
17. proxies关键字
-
什么是代理
- 代理服务器
-
代理服务器的作用
- 就是用来转发请求和响应

- 就是用来转发请求和响应
-
做爬虫的过程中经常会遇到这样的情况:最初爬虫正常运行,正常抓取数据,然而一杯茶的功夫可能就会出现错误,比如403 Forbidden;这时候网页上可能会出现 “您的IP访问频率太高”这样的提示,过很久之后才可能解封,但是一会后又出现这种情况。
-
造成这种现象的原因是该网站已采取了一些防爬虫措施。 例如,服务器将在一个时间单位内检测IP请求的数量。 如果超过某个阈值,服务器将直接拒绝该服务并返回一些错误信息。 这种情况可以称为封IP,因此该网站成功禁止了我们的抓取工具。
-
想象一下,由于服务器检测到IP单位时间内的请求数量,因此我们使用某种方式来伪装IP,以使服务器无法识别由本地计算机发起的请求,因此我们可以成功地阻止IP被封。
-
对应的在使用requests模块发送网络请求时,可以用proxies关键字参数对本地计算机进行伪装,如下所示:
import requests
def get_proxy():
json_data = requests.get('http://demo.spiderpy.cn/get/').json()
proxy = json_data['proxy']
print('获取到的代理:', proxy)
"""
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
"""
proxies = {
"http": "http://" + proxy,
"https": "http://" + proxy,
}
print('规整好的代理:', proxies)
return proxies
# get_proxy()
url = 'https://www.baidu.com/'
proxies = get_proxy()
# 找了一个第三方工具人帮助我们发送请求, 得到数据, 常用于自己电脑ip被服务器封锁的情况
response = requests.get(url=url, proxies=proxies)
print(response.text)
# 代理质量不高会报错: requests.exceptions.ProxyError, 免费代理质量不高, 经常报错, 后面我们会学习付费代理
在爬虫中为何需要使用代理?
- 有些时候,需要对网站服务器发起高频的请求,网站的服务器会检测到这样的异常现象,则会讲请求对应机器的ip地址加入黑名单,则该ip再次发起的请求,网站服务器就不在受理,则我们就无法再次爬取该网站的数据。
- 使用代理后,网站服务器接收到的请求,最终是由代理服务器发起,网站服务器通过请求获取的ip就是代理服务器的ip,并不是我们客户端本身的ip。
代理的匿名度
- 透明:网站的服务器知道你使用了代理,也知道你的真实ip
- 匿名:网站服务器知道你使用了代理,但是无法获知你真实的ip
- 高匿:网站服务器不知道你使用了代理,也不知道你的真实ip(推荐)
代理的类型(重要)
- http:该类型的代理服务器只可以转发http协议的请求
- https:可以转发https协议的请求
如何获取代理?
- 芝麻代理:https://jahttp.zhimaruanjian.com/(推荐,有新人福利)
如何使用代理?
#### 测试:访问如下网址,返回自己本机ip ####
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36',
}
url = 'http://www.cip.cc/'
page_text = requests.get(url, headers=headers).text
tree = etree.HTML(page_text)
text = tree.xpath('/html/body/div/div/div[3]/pre/text()')[0]
print(text.split('\n')[0])
#### 使用代理发起请求,查看是否可以返回代理服务器的ip ####
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36',
}
url = 'http://www.cip.cc/'
page_text = requests.get(url, headers=headers, proxies={'http':'121.234.12.62:4246'}).text
tree = etree.HTML(page_text)
text = tree.xpath('/html/body/div/div/div[3]/pre/text()')[0]
print(text.split('\n')[0])
案例- 某勾网(深度测试)
'''
- 拉勾网一次只能请求5页数据https://www.lagou.com/
- 对快代理进行n次请求,直到本机无法访问快代理为止(证明本机ip被快代理封掉了)
- 构建一个代理池(封装了很多代理ip和端口的容器),用于数据的批量爬取
'''
import requests
from lxml import etree
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36',
}
# 构建一个代理池
proxy_list = []
proxy_url = 'http://webapi.http.zhimacangku.com/getip?num=5&type=3&pro=&city=0&yys=0&port=1&pack=218090&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='
page_text = requests.get(url=proxy_url, headers=headers).text
for ip in page_text.strip().split('\n'):
dic = {}
dic['https'] = ip.strip()
proxy_list.append(dic)
for page in range(1, 5001):
print('正在爬取第%d页的ip数据......' % page)
url = 'https://www.kuaidaili.com/free/inha/%d/' % page
page_text = requests.get(url=url, headers=headers, proxies=random.choice(proxy_list)).text
tree = etree.HTML(page_text)
tr_list = tree.xpath('//*[@id="list"]/table/tbody/tr')
for tr in tr_list:
ip = tr.xpath('./td[1]/text()')[0]
print(ip)
18. 防盗链
现在很多网站启用了防盗链反爬,防止服务器上的资源被人恶意盗取。什么是防盗链呢?
- 以图片为例,访问图片要从他的网站访问才可以,否则直接访问图片地址得不到图片
图片懒加载
url:https://sc.chinaz.com/tupian/meinvtupian.html- 爬取上述链接中所有的图片数据
- 图片懒加载:
- 主要是应用在展示图片的网页中的一种技术,该技术是指当网页刷新后,先加载局部的几张图片数据即可,随着用户滑动滚轮,当图片被显示在浏览器的可视化区域范围的话,在动态将其图片请求加载出来即可。(图片数据是动态加载出来)。
- 如何实现图片懒加载/动态加载?
- 使用img标签的伪属性(指的是自定义的一种属性)。在网页中,为了防止图片马上加载出来,则在img标签中可以使用一种伪属性来存储图片的链接,而不是使用真正的src属性值来存储图片链接。(图片链接一旦给了src属性,则图片会被立即加载出来)。只有当图片被滑动到浏览器可视化区域范围的时候,在通过js将img的伪属性修改为真正的src属性,则图片就会被加载出来。
- 如何爬取图片懒加载的图片数据?
- 只需要在解析图片的时候,定位伪属性(src2)的属性值即可
案例 - 爬取微博图片
url:http://blog.sina.com.cn/lm/pic/,将页面中某一组系列详情页的图片进行抓取保存,比如三里屯时尚女郎:http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1
注意:
- 在解析图片地址的时候,定位src的属性值,返回的内容和开发工具Element中看到的不一样,通过network查看网页源码发现需要解析real_src的值。
- 直接请求real_src请求到的图片不显示,加上Refere请求头即可
- 哪里找Refere:抓包工具定位到某一张图片数据包,在其requests headers中获取
import requests
from lxml import etree
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
"Referer": "http://blog.sina.com.cn/",
}
url = 'http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1'
page_text = requests.get(url, headers=headers).text
tree = etree.HTML(page_text)
img_src = tree.xpath('//*[@id="sina_keyword_ad_area2"]/div/a/img/@real_src')
if not os.path.exists('图片'):
os.mkdir('图片')
img_name = 1
print(img_src)
for src in img_src:
data = requests.get(src, headers=headers).content
with open('./图片/' + str(img_name) + '.jpg', 'wb') as fp:
fp.write(data)
img_name += 1
# break
19. requests模块官方文档
以下是requests模块中文文档和在GitHub上面的地址:
中文文档:https://requests.readthedocs.io/projects/cn/zh_CN/latest/
github地址:https://github.com/requests/requests
案例 - 搜狗图片数据保存
"""
- 课上的搜狗图片案例,先自己实现一遍, 构建查询参数请求数据
- 将前三页的图片数据保存到文件夹里面
有错误需要解决报错<可以根据情况使用(异常捕获 + 请求参数)>
请在下方编写代码
"""
"""
ajax 异步加载
在不加载整个网页的情况下, 对页面进行局部刷新
页面上半部分数据不会刷新, 下半部分加载新数据
网站动态数据渲染:
页面第一页数据做了静态数据渲染
后续页数的数据统一做动态渲染
一般情况下可以按照动态数据包翻页的规律, 构建第一页请求
"""
import requests
def get_params(page):
"""构建请求参数的函数"""
return {
'mood': '7',
'dm': '0',
'mode': '1',
'start': str(page),
'xml_len': '48',
'query': '蜡笔小新'
}
url = 'https://pic.sogou.com/napi/pc/searchList'
count = 1 # 定义一个变量用于文件名字的指定
for i in range(0, 97, 48):
# print(i)
params = get_params(i)
response = requests.get(url=url, params=params)
json_data = response.json()
list_data = json_data['data']['items']
for data in list_data:
img_url = data['picUrl']
print(img_url)
try:
# 请求图片数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
img_data = requests.get(url=img_url, timeout=3, headers=headers).content
file_name = str(count) + '.png'
with open('img\\' + file_name, mode='wb') as f:
f.write(img_data)
count += 1 # 自增
except Exception as e:
print(e)
continue
print('*' * 50)
案例 - 肯德基城市采集
"""
- 课上肯德基案例, 将北京,上海,广州三个城市的门店信息获取下来
- 获取下来的信息用print函数打印即可
请在下方实现代码:
"""
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
def get_page(city_name):
"""
传入城市名, 计算当前成一共有多少页数据
:param city_name: 城市名
:return: 城市对应的数据页数
"""
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
params = {'op': 'keyword'} # 查询参数
data = { # 请求参数
'cname': '',
'pid': '',
'keyword': city_name,
'pageIndex': '1',
'pageSize': '10'
}
response = requests.post(url=url, params=params, data=data, headers=headers)
json_data = response.json()
count = json_data['Table'][0]['rowcount']
# print(count)
if count % 10 > 0: # 171取余10余1
page_num = count // 10 + 1
else:
page_num = count // 10
return page_num
# print(get_page('武汉'))
def send_request(keyword):
page = get_page(keyword)
for page in range(1, page + 1):
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
params = {'op': 'keyword'} # 查询参数
data = { # 请求参数
'cname': '',
'pid': '',
'keyword': keyword,
'pageIndex': str(page),
'pageSize': '10'
}
# data是构建post请求的请求参数关键字
response = requests.post(url=url, params=params, data=data, headers=headers)
json_data = response.json()
# print(json_data)
list_data = json_data['Table1']
for res in list_data:
storeName = res['storeName']
addressDetail = res['addressDetail']
pro = res['pro']
print(storeName, addressDetail, pro)
if __name__ == '__main__':
all_city = ['北京', '上海', '广州']
for city in all_city:
print(f'========================正在抓取 {city} 城市的数据======================')
send_request(city)
案例 - 公告数据采集
"""
目标网址: http://www.zfcg.sh.gov.cn
作业要求:
1. 点击页面导航栏中 "采购公告" 栏目
2. 采集下面公告信息数据, 需要采集以下数据:
title 公告标题
districtName 公告区域
3. 采集完后打印输出即可
请在下方完成代码:
"""
import requests
url = 'http://www.zfcg.sh.gov.cn/portal/category'
json_data = {"pageNo": 1, "pageSize": 15, "categoryCode": "ZcyAnnouncement1", "_t": 1687780627000}
# json 以json数据提交的请求参数
response = requests.post(url=url, json=json_data)
json_data = response.json()
print(json_data)
for data in json_data['result']['data']['data']:
title = data['title']
districtName = data['districtName']
print(title, districtName)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!