【2023 CCF 大数据与计算智能大赛】基于TPU平台实现超分辨率重建模型部署 基于FSRCNN的TPU平台超分辨率模型部署方案
2023 CCF 大数据与计算智能大赛
基于TPU平台实现超分辨率重建模型部署
基于FSRCNN的TPU平台超分辨率模型部署方案
WELL
刘渝
人工智能 研一
西安交通大学
中国-西安
1461003622@qq.com
史政立
网络空间安全 研一
西安交通大学
中国-西安
1170774291@qq.com
崔琳、张长昊、郭金伟
软件工程等 研一
北京大学软微学院
中国-北京
g1335129739@163.com
团队简介
刘渝:西安交通大学本硕,目前研一,研究兴趣是机器人多模态感知
史政立:西安交通大学本硕,网络空间安全专业。曾获得首届人工智能安全大赛优秀奖
崔琳:本科毕业于西安交通大学,目前北京大学软件与微电子学院研一在读,主要进行多模态和dml方向的研究以及学习
张长昊:研究生就读于北大软微软件工程专业,研究兴趣是时序数据预测
郭金伟:本科毕业于辽宁工程技术大学,在校期间获得数学竞赛国家一等奖,辽宁省acm竞赛银牌,硕士就读于北京大学软件与微电子学院,录取方向为人工智能
摘要
视觉效果逼真的Stable Diffusion在生成高分辨率图像时效率较低,在TPU平台上提高Stable Diffusion模型生成高分辨率图像的效率可以依靠超分辨率模型作为上采样器。
赛题的目标是为在边缘计算设备上提高高分辨率图像生成效率提供有效的技术方案,降低资源和内存需求,同时保证图像质量。
针对本赛题,我们经过对比分析采用了FSRCNN作为超分辨率模型,并设计了集中式超分辨率(Centralized Super Resolution)的方法与插值组合到一起用于提高图像分辨率。此外,我们将前后处理集成到模型中,利用TPU的算力加速前后处理的速度,以减少处理时间。
实验结果表明,我们的方法在牺牲一部分图像质量评估指标NIQE的情况下,显著减少了处理时间,在赛题给定的评价指标上具有较高的得分。我们还讨论了性能改进的可能性,包括考虑使用Bmcv硬件加速部分操作。
关键词
图像超分辨率,TPU模型部署
1 赛题数据分析
赛题的任务是针对给定的数据在TPU上进行超分辨率处理,以期实现推理速度与图像质量之间的最佳平衡。
我们首先从大小和内容两个方面分析了数据的基本构成,从尺寸上说:最大尺寸:2039*2039,最小尺寸:183*510。
根据最大尺寸和最小尺寸对图像分组,组1:长宽均小于500,组2:去除组1后长宽均小于1000,组3:组2中长或宽为510,组4:去除组1、2后长宽均小于1500,组5:去除组1、2、4后的数量。根据分组对数据进行统计,得到下表:
| 组别 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 数量 | 1 | 494 | 400 | 92 | 13 |
可以看出小尺寸图像占比较大,大尺寸图像占比较少,同时长或宽为510的图像占比很大。
同时我们采样查看了数据图像的内容,图像确实包含各个场景,既包含外景也包含人像,还有虚拟二次元人物,内容比较丰富。我们认为赛题使用的是网络搜集的图像可以避免直接使用Diffusion生成的图像与实际情况可能的偏差,从而避免可能对NIQE这一自然评价指标有所影响。
2 方案介绍
本节将介绍我们采用的方案的具体内容, 我们针对比赛任务主要进行了三方面设计:超分辨率模型选取、集中式超分辨率处理(CSR)设计和前后处理集成。
2.1 超分模型选取
在经过多次比较实验之后,我们最终选用FSRCNN[1]作为超分模型使用。以下说明其设计结构及主要思想:
1、特征提取层:使用少量的卷积层来提取图像特征。我们使用的卷积核。
2、收缩层:减少特征维度,以降低后续处理的计算复杂度。我们使用的卷积核对特征提取层的高维数据降维。
3、映射层:一系列的卷积层,用于学习输入到输出(低分辨率到高分辨率)的映射关系。我们使用 的卷积核进行非线性映射。
4、扩张层:增加特征维度,准备进行分辨率提升。我们采用 的小卷积核恢复图像至收缩前的维度。
5、放大层:对图像进行分辨率提升。我们采用的卷积核放大图像尺寸。
总结结构如下图所示:
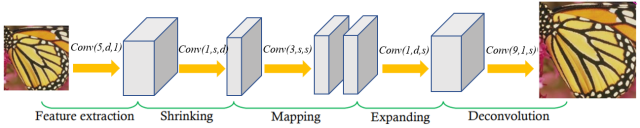
图1:FSRCNN结构
2.2 超分实施策略
官方代码通过将原图分解成多个小块进行超分辨率处理,然后使用权重融合来消融边界,这是比较优雅的处理。但是根据我们对评价公式的分析,运算速度的提高即运算时间的减少带来的收益高于图像质量带来的收益。
我们了解JPEG压缩图像是通过丢弃即使丢失也不会显著影响图像视觉质量的信息,从而在保持相对较高视觉质量的同时,能够以更小的文件大小存储和传输。受此启发,对于增大图像分辨率的任务,直接通过插值算法放大的质量通常比使用超分辨率模型放大的效果更差,因此我们可以仅使用超分辨率模型放大图像中对视觉效果影响更大的一部分,从而在时间和效果之间达到更好的平衡。
由于NIQE通过分析图像的统计特性,评估其视觉质量,从而更接近于人眼对图像的感知评价;另一方面,测试使用的图像种类也非常丰富。因此我们只能寻找一个普适的注意力集中的区域。
在计算机视觉和图像处理领域,有一些研究关注人眼视觉系统在观察图像时对中心区域的更高关注度[2]。这种现象通常被称为"中心偏向"(center bias)。受此启发,我们决定采用集中式超分辨率处理Centralized Super Resolution (CSR) 的策略。我们针对更高关注度的中心区域采用模型处理,而其他较低关注度的区域采用插值处理,这一方案首先符合人眼认知,而下一节我们将重点介绍其统计原理。
2.3 统计特性分析
为了进一步说明提出的CSR框架的有效性,我们对CSR、ESR(Edge Super Resolution)和GSR(Global Super Resolution)统计特性分析,深入探究不同超分辨率策略对图像的影响,并为它们的性能进行客观评估(NIQE)提供有力依据。
频率统计差异(幅度谱): 如图2所示,相较于ESR, CSR和GSR的的幅度谱变化更加自然,趋于一致,ESR在高频阶段能量增加剧烈。
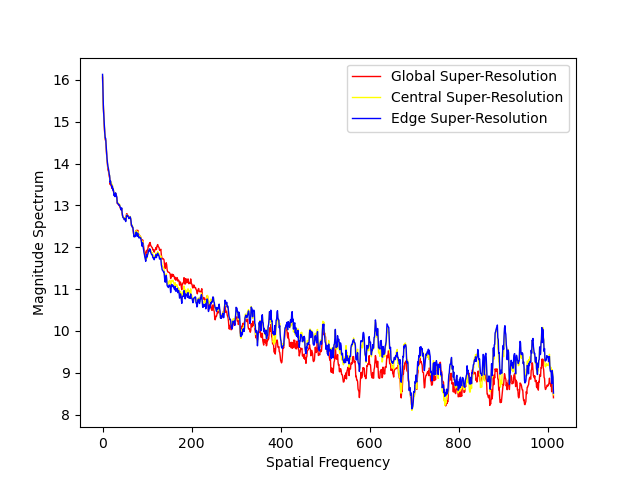
图2:频谱特性曲线
亮度统计差异: GSR亮度特性与CSR和ESR均不同。GSR图像缺乏亮度饱和区域,并且整个直方图分布较为不均匀。ESR和CSR图像则出现饱和的像素值,相对于ESR,CSR亮度分布更加均匀一点。
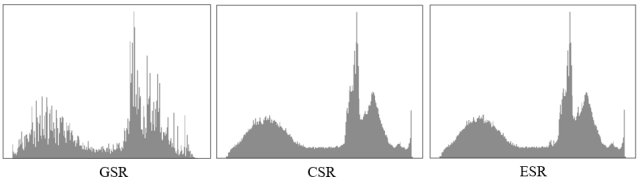
图3:亮度直方图
局部亮度、对比度以及频率的t检验差异: t检验(t-test)旨在利用两组样本数据判断其均值是否存在显著差异。在这里我们利用t检验的p值进行比较。p值越小,代表两组数据存在显著性差异。我们比较GSR与CSR和GSR与ESR的t检验p值,相较后者,GSR与CSR的p值较大,这也就意味着,从统计平均的意义而言,GSR与CSR之间的统计特性更加接近。从像素域到频域,GSR和CSR共享统计特征。
| P-value | 亮度 | 对比度 | 频率 |
|---|---|---|---|
| GSR+CSR | 0.487 | 0.581 | 0.00100 |
| GSR+ESR | 0.485 | 0.558 | 0.00003 |
三种统计特性的分析旨在证明CSR这种启发式的超分策略与一般的全局超分策略GSR之间存在更强的统计一致性。而NIQE指标正是建立在这种统计特性基础之上,因此CSR相较于其他超分策略,其NIQE值会更接近GSR。
2.3 前后处理集成
一方面TPU的算力比较强大,另一方面我们采用了中央超分的设计,因此我们观察到在处理图像时,TPU推理时间相对较短,而前后处理时间则占据了整体处理时间的较大部分。
通过查阅手册我们了解到,TPU配套软件提供的bmcv可以通过TPU的加速来提高前后处理的速度,但是我们认为这样仍然不如直接把计算以算子形式直接放到TPU上运行的速度快。
考虑到本任务的前后处理相对简单,使用的均为TPU软件支持的算子,同时前后处理方式固定,没有分支等结构,我们希望能够把数据的前后处理都集成到模型中,直接使用TPU进行处理。
具体而言我们集成的包括如下操作:输入图像0-255到0-1的转换、BGR到yCbCr和yCbCr到BGR的通道转换、输入TPU图像的插值放大,其中输入TPU的图像也要插值放大的原因是超分辨率模型仅对y通道进行处理,其余通道需要插值获得。
2.4 流程总结
最终总结流程图如下:
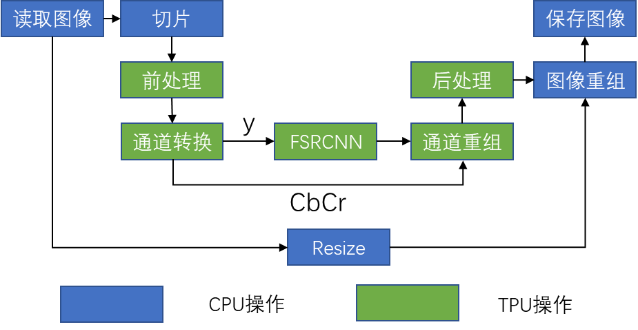
图4:方案流程图
3 效果对比说明
3.1 模型对比
我们采用官方提供的推理流程代码进行实验,仅对输入输出的不同进行少量处理,测试了ESRGAN、SRCNN和FSRCNN在官方代码下的运行效果,如下表所示:
| 项目 | ESRGAN | SRCNN | FSRCNN |
|---|---|---|---|
| 时间/s | 5.1833 | 2.3728 | 1.8364 |
| NIQE | 4.4012 | 5.8864 | 4.7701 |
FSRCNN以少量的NIQE的损失,大大减少了处理时间,显著提高了运行效率。
3.2 超分策略对比
修改代码逻辑为CSR的形式,通道域转换等前后处理操作在CPU上进行,模型推理使用TPU进行,结果如下表所示:
| 项目 | GSR | CSR |
|---|---|---|
| 时间/s | 1.8364 | 0.5896 |
| NIQE | 4.7701 | 5.9271 |
采用CSR处理之后模型以一定的NIQE损失换来了巨大的推理时间改善;我们的结果证实了中央超分不仅在视觉效果上符合人类的观察习惯,而且在客观的图像质量评估标准上也显示出优越性。
3.3 前后处理集成对比
未集成表示前后处理均通过Opencv进行,集成表示将所有可以转移到TPU处理的步骤都通过TPU支持的算子进行,结果如下表所示:
| 项目 | 未集成 | 集成 |
|---|---|---|
| 时间/s | 0.5187 | 0.0141 |
| NIQE | 6.0481 | 6.3400 |
TPU的加速显著减少了前后处理的时间,使结果又有一次比较大的提升。
4 性能改进讨论
4.1 Bmcv加速
虽然我们把大部分前后处理操作转移到TPU进行,但是仍有一部分无法转移,这部分操作可以使用官方库Bmcv通过硬件加速。
我们详细阅读文档使用了Bmcv对代码进行了改写,但是23.5.1版本的Bmcv不支持cubic插值,这对我们方案的效果影响比较大,因此最终放弃了Bmcv加速的方案。
致谢
感谢史政立和刘渝同学的共同辛苦努力,感谢崔琳、张长昊、郭金伟同学的共同积极参与。
参考
[1] Dong C, Loy C C, Tang X. Accelerating the super-resolution convolutional neural network[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14. Springer International Publishing, 2016: 391-407.
[2] Tseng P H, Carmi R, Cameron I G M, et al. Quantifying center bias of observers in free viewing of dynamic natural scenes[J]. Journal of vision, 2009, 9(7): 4-4.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解决flask中jinja2插值变量变成字符串的办法
- nodejs+vue+ElementUi摄影预约服务网站系统91f0v
- Golang使用redis在 Gin 框架中集成使用 go-redis
- LLaVA-v1.5-7B:实现先进多模态学习的开源AI
- Head First Design Patterns - 装饰者模式
- 免费封装App,让你的网页变身为独立应用!
- python多线程并发执行和异步处理
- 常用的dom操作
- 小红书达人矩阵:提升粉丝互动与转化的秘密武器!
- 苹果M系列芯片安装Notepad-- 详细教程(亲测14以上系统也可用)