爬虫之牛刀小试(五):爬取B站的用户评论
发布时间:2024年01月14日
小小地出手一下,这次使用selenium来自动化进行爬取,虽然速度很慢,但是还可以接受。
首先判断用户评论在哪里,随便找一下。
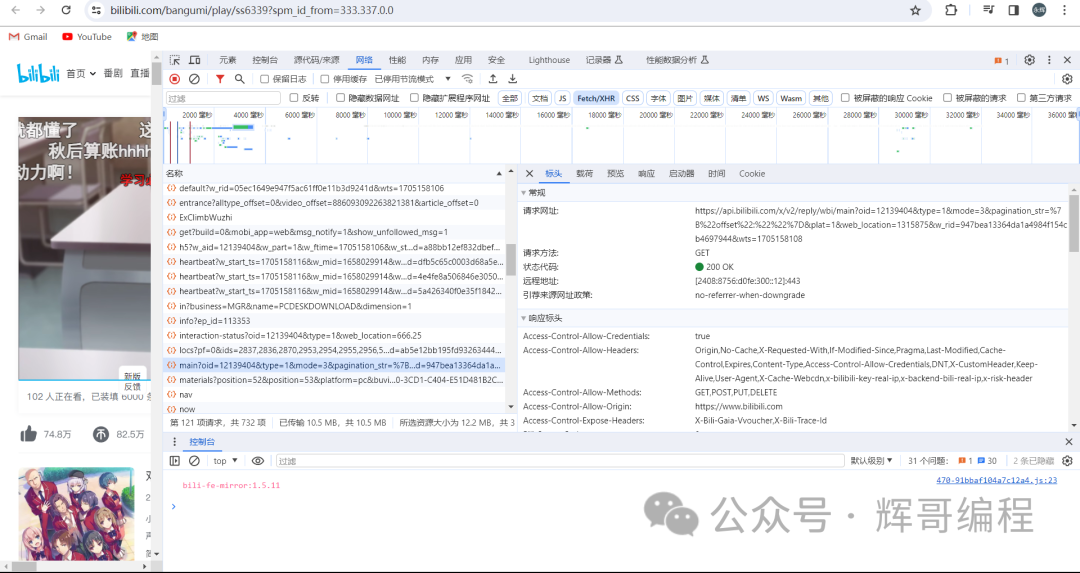
然后点进去看看是不是,发现是的!

接着我们的目标要获取多个网址(类似于https://api.bilibili.com/x/v2/reply/wbi/main?oid=12139404&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&web_location=1315875&w_rid=8e3a5b1eabee039b1642c773f5a46fbf&wts=1705157762)
使用selenium来模仿人的动作,获取多个网址,关键是B站需要登陆就很难受,不知道为什么Cookie用不了,只好手动操作一下了。现在尝试一下自动化刷新获取想要的网址,成功!!
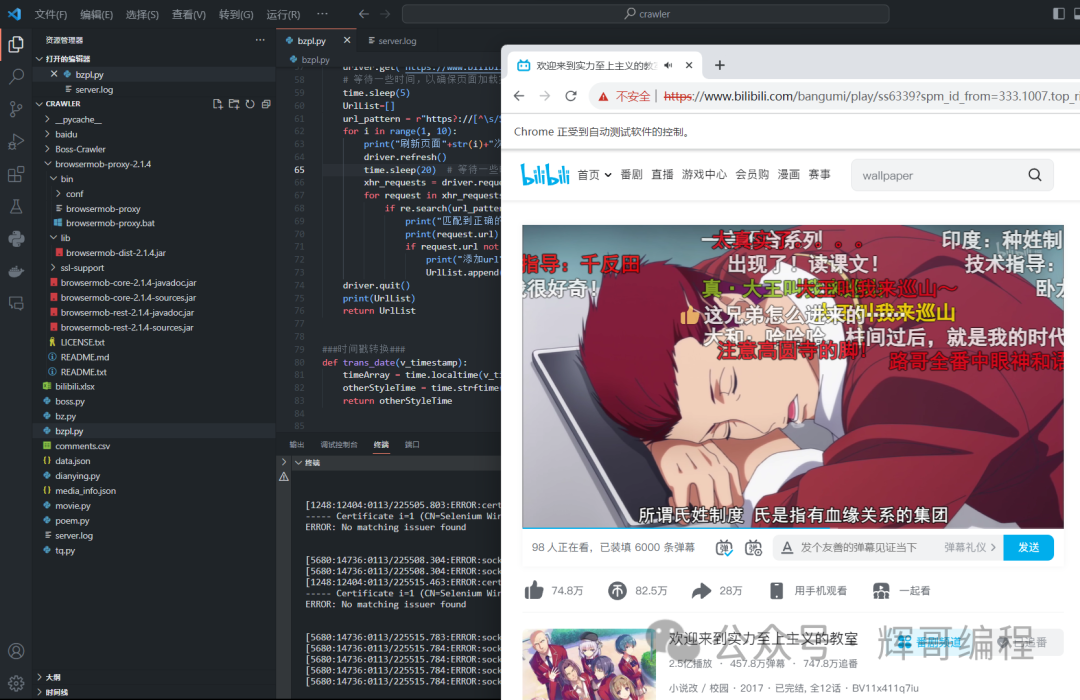
返回网址后接着看看返回的内容。
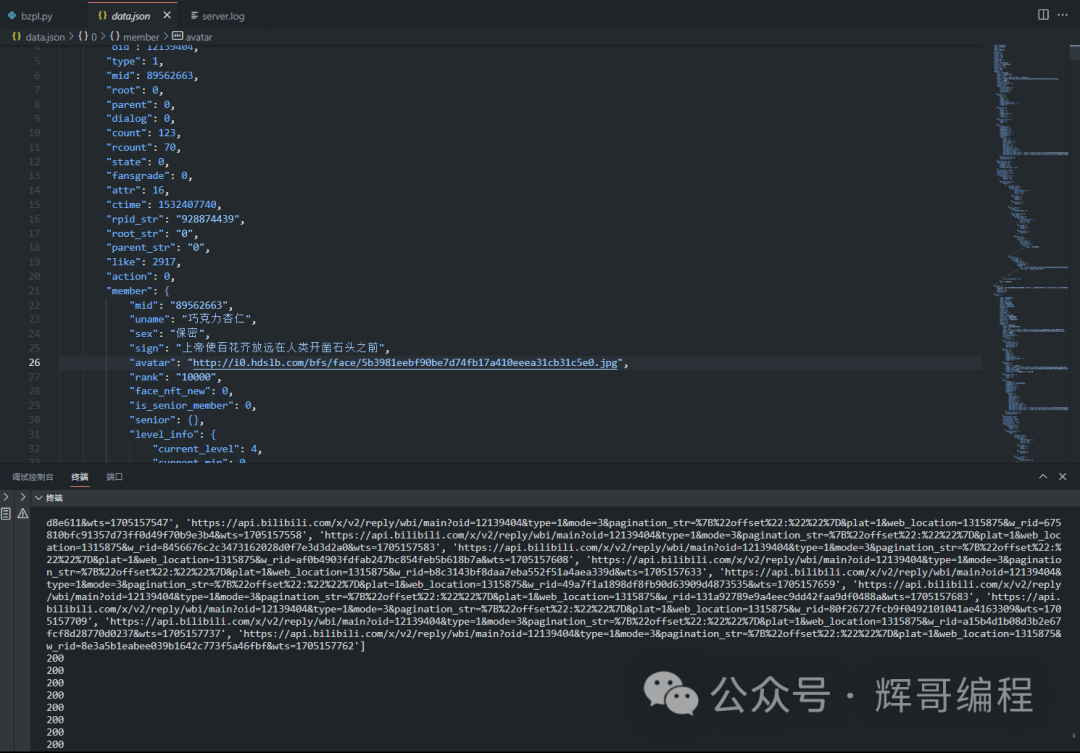
找到你想要的值,对了,时间记得要转化一下,不然会出错!接着写入文件,结果就变成了:
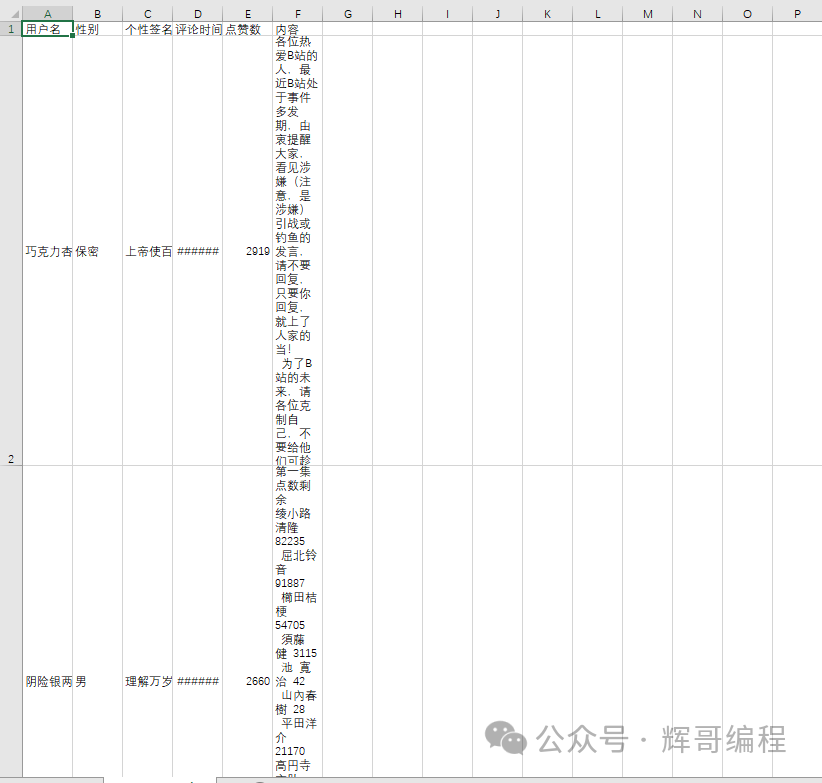
对比一下评论:
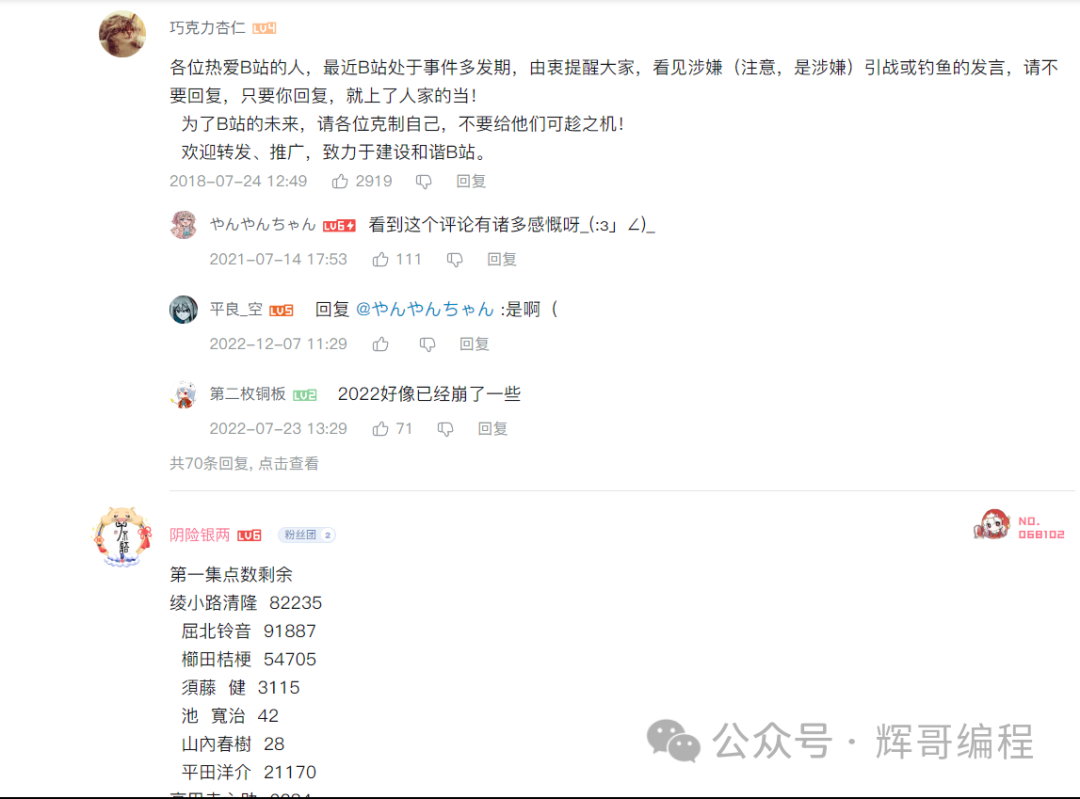
奉上代码:
import requests
import time
import pandas as pd
import json
from selenium.webdriver.chrome.options import Options
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from browsermobproxy import Server
from selenium.webdriver.common.keys import Keys
import re
from selenium import webdriver
from seleniumwire import webdriver as swd
from mitmproxy import proxy, options
from mitmproxy.tools.dump import DumpMaster
from selenium.common.exceptions import NoSuchElementException
### 配置爬虫条件 ###
# 请求评论url地址时需要的cookies
cookie=' '
# api请求头
apiheaders={
'User-Agent': ' ',
'Cookie':cookie
}
###获取目标url###
def target_url():
option = webdriver.ChromeOptions()
option.add_argument('--ignore-certificate-errors')
driver = swd.Chrome(chrome_options=option)
# 访问网页
driver.get('https://www.bilibili.com/')
print("正在登录b站...")
# 用cookies登录b站
cookies_str = ' '
cookies = []
for item in cookies_str.split(';'):
parts = item.strip().split('=')
if len(parts) < 2:
continue
name, value = parts
cookies.append({'name': name, 'value': value})
# 现在你可以像之前一样使用这些 cookies
for cookie in cookies:
driver.add_cookie(cookie)
# 登录后等待一段时间,让页面加载完成
time.sleep(15)
# 尝试获取用户名元素
print("登陆成功")
driver.get("https://www.bilibili.com/bangumi/play/ss6339?spm_id_from=333.1007.top_right_bar_window_history.content.click")
# 等待一些时间,以确保页面加载完成(你可以根据需要使用等待条件)
time.sleep(5)
UrlList=[]
url_pattern = r"https?://[^\s/$.?#].[^\s]*\/main\?[^\s]*"
for i in range(1, 10):
print("刷新页面"+str(i)+"次")
driver.refresh()
time.sleep(20) # 等待一些时间,以确保页面刷新完成
xhr_requests = driver.requests
for request in xhr_requests:
if re.search(url_pattern, request.url):
print("匹配到正确的url")
print(request.url)
if request.url not in UrlList:
print("添加url")
UrlList.append(request.url)
driver.quit()
print(UrlList)
return UrlList
###时间戳转换###
def trans_date(v_timestamp):
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
###获取数据###
def get_data(UrlList):
data = []
for url in UrlList:
response = requests.get(url, headers=apiheaders)
print(response.status_code)
if response.status_code == 200:
json_response = response.json()
replies = json_response['data']['replies']
# 将 replies 保存为 JSON 文件
# with open(f'data.json', 'w', encoding='utf-8') as f:
# json.dump(replies, f, ensure_ascii=False, indent=4)
data.append(replies)
else:
print("请求错误")
time.sleep(1)
return data
# 将文件写入csv中
def write_to_csv(data):
comments_data = [
['用户名', '性别', '个性签名', '评论时间', '点赞数', '内容']
]
for replies in data:
print("正在读取第"+str(data.index(replies)+1)+"个网址")
for reply in replies:
uname = reply['member']['uname']
sex = reply['member']['sex']
sign = reply['member']['sign']
time1 = trans_date(reply['ctime'])
like = reply['like']
content = reply['content']['message']
comments_data.append([uname, sex, sign, time1, like, content])
# 指定要保存的CSV文件路径
csv_file_path = "comments.csv"
# 创建一个DataFrame
df = pd.DataFrame(comments_data)
# 将DataFrame写入CSV文件
df.to_csv(csv_file_path, index=False, header=False, encoding='utf_8_sig')
print(f"正在写入数据进 {csv_file_path}")
if __name__ == '__main__':
print("开始爬取")
UrlList=target_url()
data = get_data(UrlList)
write_to_csv(data)
print("写入完成")
User-Agent和Cookie用自己的。
代码运行结果:
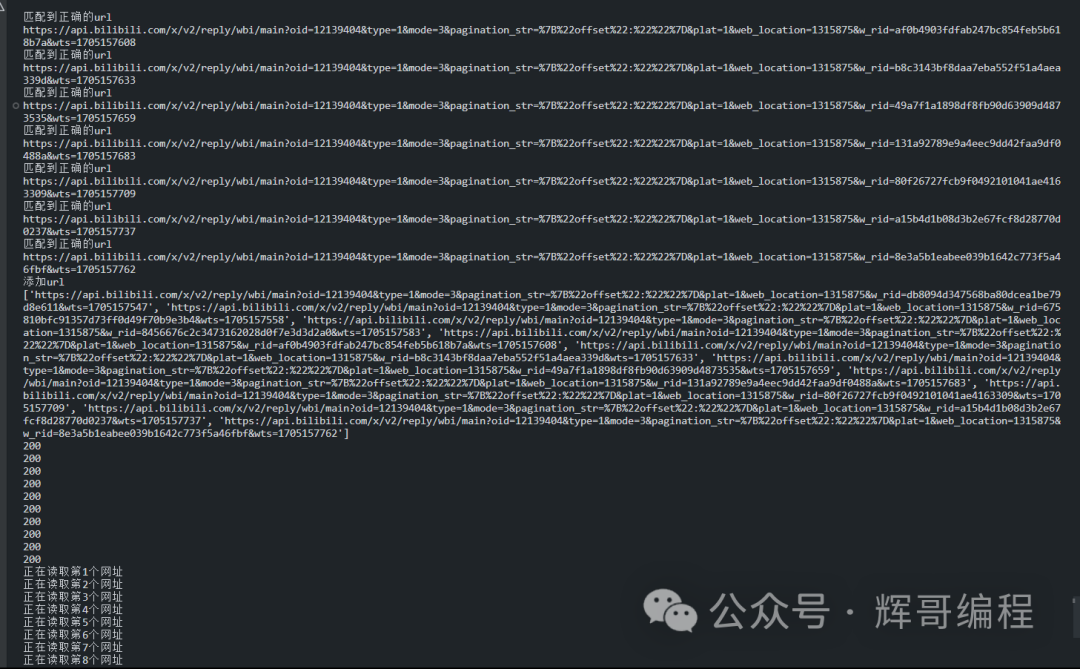
此次共读取了20X10共计200条评论,每一个网址有20条评论,需要花费大约30s左右,共计爬十个。
最近新开了公众号,请大家关注一下。

文章来源:https://blog.csdn.net/m0_68926749/article/details/135577824
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JetCache源码解析——概览
- 一径发布全新SPAD激光雷达|LiDAR平权,进入千元时代!
- WPF-UI HandyControl 控件简单实战
- 【Python】dbf批量转为excel(非arcpy和arcpy转法)
- 录制完视频如何去除重复部分?
- The loss converges too quickly. how to solve this problem.
- 爆了,AI表情包制作全攻略揭秘!
- 【K8S 资源管理】声明式资源管理
- python判断某字符串以某字符串开头
- openEuler安装KVM