java18
发布时间:2024年01月22日
集合
Set
- set是无序不可重复的 (不是一定无序, 是有可能无序)
- HashSet 底层是哈希表 就是HashMap
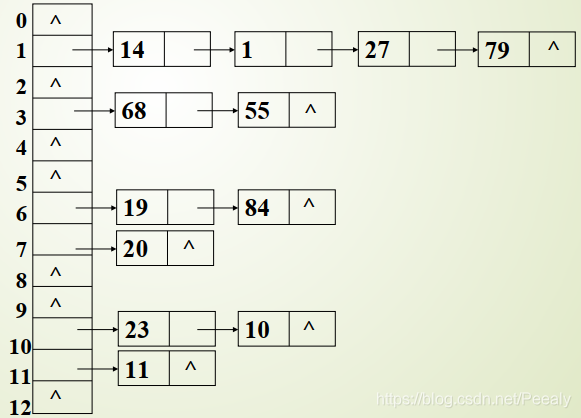
- TreeSet 底层是红黑树, 会自动自动排序 ( 存储的类型必须是同类型的元素不然没办法排序 )
- 数字从小到大, 字符串每一位ASCII码值, 日期 : 自然日期, 昨天 今天 明天 后天
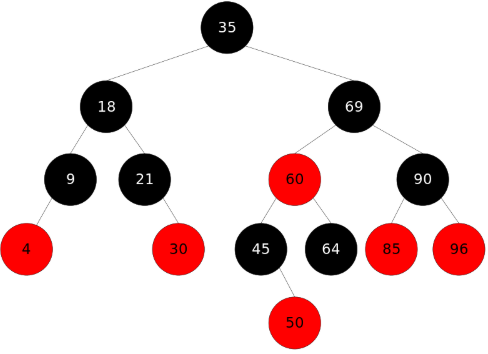
TreeSet
添加
- 添加元素不能重复
Set set = new TreeSet();
set.add(1)
删除
- 根据内容删除元素.
set.remove(1);
遍历
for (Object o : set){}
HashSet
- 定义
Set set = new HashSet();
- 常用方法和TreeSet一样;
排序
Comparable
- 为什么TreeSet可以自动排序? 因为 要添加的数据都实现了Comparable接口,比如 Integer String等 都实现了
- 如果我们添加的为自定义类型的对象,则需要让该类也实现Comparable接口并实现compareTo方法
class User implements Comparable {
int age;
public User(int age) {
this.age = age;
}
@Override
public int compareTo(Object o) {
// this 是 要添加的元素
// o 是集合中的元素
if (o instanceof User) {
User oldUser = (User) o;
// 返回0 说明 相等,则不添加
// 返回大于0,说明要添加的元素,比集合中的大,往后放
// 返回小于0,说明要添加的元素,比集合中的小,往前放
return this.age - oldUser.age;
}
return 0;
}
}
Comparator
-
虽然我们可以自己写排序规则但当我们用系统提供的类时并不能修改的他的排序方法, 那么我们想要进行逆序排序的时候怎么办. 这时候就出现了Comparator
-
或者我们要存的数据没有实现 Comparable 也需要使用 Comparator.
-
以上两种场景,可以使用 comparator接口解决 , 只要使用comparator之后,不管原来是否有comparable 都会按照comparator来进行排序 ( comparator 优先级大于 comparable )

使用
- 写一个继承这个Comparator的类并把他创建对象传入对应方法, 这是我们只使用一次这个方法可以使用匿名内部类实现Comparator接口来简化代码
set排序
- set在我们创建对象时可以直接传入这个比较器类(使用构造方法传入)
Set set = new TreeSet(new Comparator(){
@Override
public int compare(Object o1, Object o2) {
// o1 是要添加的元素
// o2 是集合中的元素
// 返回0 说明相同
// 返回大于0 , 往后放
// 返回小于0 , 往前放
return (Integer)o2 - (Integer)o1;
}
})
List排序
- 当然list排序也可以使用这样的方法
- 它使用的是 Collections 类中的一个 sort 方法, 可以进行排序
List list = new ArrayList();
Collections.sort(list); // 可以直接进行排序
Collections.sort(list, new Comparator(){ //也可以把 要排序的集合和 比较器类一起传入
@Override
public int compare(Object o1, Object o2) {
return (Integer)o2 - (Integer)o1;
})
总结
- 如果添加的元素类,是我们写的,比如User,那么我们想要排序,可以使用comparable来解决,这样还能保留comparator的扩展性
- 如果添加的元素类,不是我们写的,意味着我们没办法修改对应的源码,就使用comparator来解决
HashMap & TreeMap
-
那么我们的Map 与 set 之前有什么区别呢 set我们只保存值 而 Map我们通常是通过键值对的形式进行保存 ( 保存映射关系 ).
-
Map特性 : 无序,key不可重复,value可重复, 保存的是key和value键值对
-
Map 的继承家族
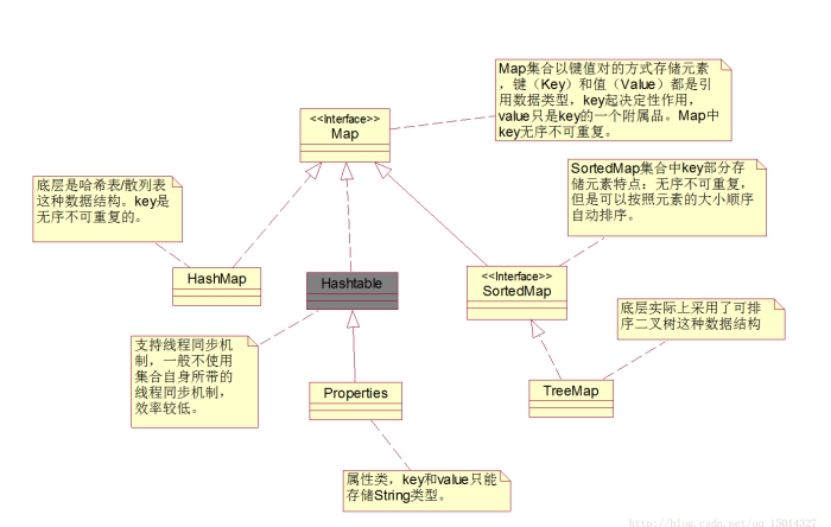
散列表
- 散列表 又叫哈希表 , 数组中保存的是单向链表
- hash算法 : 是一种安全的加密算法,可以把不定长数据改为定长数据,并且不保证其唯一性
- 其中算法包括 : 直接寻址法,数字分析法,平方取中法,折叠法,随机数法,除留余数法
- 添加过程 :
- 添加数据时(key,value) , 调用key的hashCode方法,生成hash值,然后通过hash算法得到数组下标
- 如果该下标对应的空间中,没有数据,就创建一个Node对象,把key和value封装进去,保存到对应的下标上
- 如果该下标对应的空间中有数据,则调用key的equals方法,和空间中所有的数据进行比较
- 如果没有相同的,则创建一个Node对象,保存在这个单向链表中的尾部
- 如果equals判断有相同的,则不添加对应的key,value值替换原来的value
- 1.8开始,为了提高查询效率,对链表进行了优化,如果数组对应的链表中的数据大于7(第八个),会把链表转换为红黑树
其中重要的几个参数
-
哈希表数组的默认长度 ( 16 )

-
最大容量
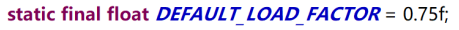
-
加载因子 ( 到多少扩容大概 )
- 链表个数到达八个就转换成红黑树

-
红黑树节点小于 6 个就转换为链表

-
还有个64

重要底层代码
- 可以看到下面这个底层代码, 如果key存在的话只会赋值value

HashMap
- 在使用 hashSet 和 hashMap 的时候,想要代表对象的唯一性,需要同时覆写hashCode方法和equals方法
- 先定义一个 HashMap
HashMap map = new HashMap();
添加, 修改方法
- 如果key未出现过,则为添加, 如果key是已有的key,则是修改value的值 ( key不会重复 )
map.put(key, value)
根据key获取value值
map.get(key)
根据key删除
map.remove(key);
获取个数
map.size();
是否包含某个key
map.containsKey("");
是否包含某个value
map.containsValue("");
是否为空(个数是否为0)
map.isEmpty();
清空
map.clear();
获取所有value值
-
- 把map中所有的value保存到set中,并返回
map.values();
返回key
- 把map中所有的key保存到set中,并返回
Set set = map.keySet();
返回key和value
- 把key和value封装到entry中,然后保存在set中返回
Set entrys = map.entrySet();
Map没有自带遍历
- 但是可以通过曲线救国
Set set = map.keySet();
for (Object object : set) {
System.out.println(object+" : "+map.get(object));
}
TreeMap
- 和treeSet使用方式一样,只不过添加的时候需要使用put 需要添加键值对
- 排序比较 也是按照key比较, 和value没有关系
TreeMap map = new TreeMap();
常用方法
- 参考HashMap
泛型
概述
- 泛型 : 编译时进行类型检查 , 可以限制类型统一,并且在编译时进行类型校验,不符合条件的不能使用
- 现在集合中 是可以保存任意元素 , 加上泛型之后,就只能保存某一种数据类型的元素
- 泛型 不能写基本类型
使用方法
List list = new ArrayList();
list.add(1);
list.add("a");
for (Object object : list) {}
List<String> strs = new ArrayList<String>();
strs.add("a");
strs.add(1); // 此时会报错, 只能传入String类型
for (String string : strs) {}
自定义泛型
- 常用的自定义名称
- E
- eleme,一般在map中存储
- N
- Number
- T
- type,表示具体的一个java类型
- ?
- 表示不确定的类型
- 如果规定了泛型,但是不设置泛型的话,则默认为Object
MyClass<string> my = new MyClass<String>();
my.m1(1); //此时就只能传入字符串 传入1时就会报错
class MyClass<T> {
public void m1 (T t){
System.out.print(t);
}
}
文章来源:https://blog.csdn.net/jiangshicsdn/article/details/135709005
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL 高级SQL语句与存储过程
- 代码随想录算法训练营第47天|● 198.打家劫舍 ● 213.打家劫舍II ● 337.打家劫舍III
- 常见的DOM操作有哪些?常见的BOM对象有哪些?DOM操作与BOM对象的区别?
- SpringBoot进阶
- leetcode:32.有效的字母异位词
- ‘再战千问:启程你的提升之旅‘,如何更好地提问?
- python保姆级教程, 安装
- 进程地址空间
- 系统运维-Linux SSH密码登录免密登录密钥登陆
- 情感分析Baseline快速实现