音频筑基:时延、帧长选取的考量
音频算法中,时延和音频帧长的选择通常是个需要平衡的参数,这里分析下背后的考量因素。
帧长与时延的关系
一般来说,帧长是音频算法端到端时延的子集,是时延的组成元素,所以,帧长越长,时延越大。
那为啥会有音频帧长的概念呢?原因是一般会做分块频域变换,根据音频信号的短时平稳性(10-30ms,信号是周期重复的),从而进行分块分帧做短时傅里叶变换,于是有了帧长的概念。
时延指标里的那个why
那时延是啥?之前文章有讲,简单说,就是音频信号从发出到接收经历的时间延迟。过长的延迟带给人体验就是有卡顿感,而人耳对时延的敏感性是有范围的:
-
人耳对端到端(嘴到耳的时延)
<150ms不会有明显感知<50ms可能感知不大50~100ms之间可能轻微感知100~200ms可感知
>200ms能明显感知>400ms会无法忍受
-
蓝牙传输链路
- 普通人对于80ms以下的声音延迟是没有知觉的
- 经过听力专门训练的人员可识别50ms左右的延迟,例如专业电竞人员
- 几乎没有人能识别35ms以下声音延迟
帧长变化的影响
以音频编解码为例,见下面描述:
First, the audio is sampled. Perceptual coding requires a codec to look at multiple, consecutive samples, as a lot of the opportunities for compression come from identifying periods of repeated sound (or lack of sound). This means that most codecs need to capture sufficient, successive samples to have enough data to characterise these changes. This period of sampling is called a frame.
Different encoding techniques use different frame lengths, but it’s almost always a fixed duration. If it’s too short, the limited number of samples starts to reduce the efficiency of the codec, as it doesn’t have enough information to apply the perceptual coding techniques, which impacts the quality. On the other hand, if the frame sizes grow, the quality improves, but the latency increases, as the codec has to wait longer to collect each frame of audio data.——《Introducing-Bluetooth-LE-Audio-book》
帧长选取里的那个why
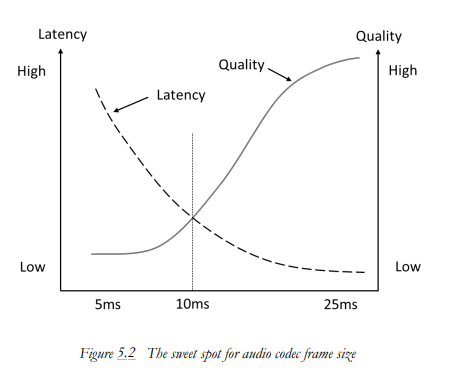
语音短时平稳性是在10-30ms这个区间有效,从下图可以看出,从编码质量和时延两个维度综合看,频域编解码最佳帧长是10ms及以上,5ms短帧的低码率编码就不太占优势。
参考资料
- Introducing-Bluetooth-LE-Audio-book.pdf, link
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【软考系统架构设计师】2023年系统架构师冲刺模拟习题之《软件工程》
- SAP设置修改&删除自动JOB
- Matlab中常见的数据平滑方式
- 2023年12月 C/C++(一级)真题解析#中国电子学会#全国青少年软件编程等级考试
- laravel-admin之 浏览器自动填充密码(如果需要渲染数据库密码的话,首先确认数据库密码是否可以逆向解密)
- 青少年CTF-qsnctf-Web-Queen
- C/C++汇编学习(四)——编写不同的C++程序并分析其汇编输出
- Opencv实时获取摄像头数据(附带解析)
- Qt 中如何将图片转化为yuv420p
- 【单元测试】使用Gradle运行@SpringBootTest单元测试提示“No tests found for given includes。。。 “解决