Redis - 主从集群下的主从复制原理
发布时间:2023年12月17日
主从复制过程

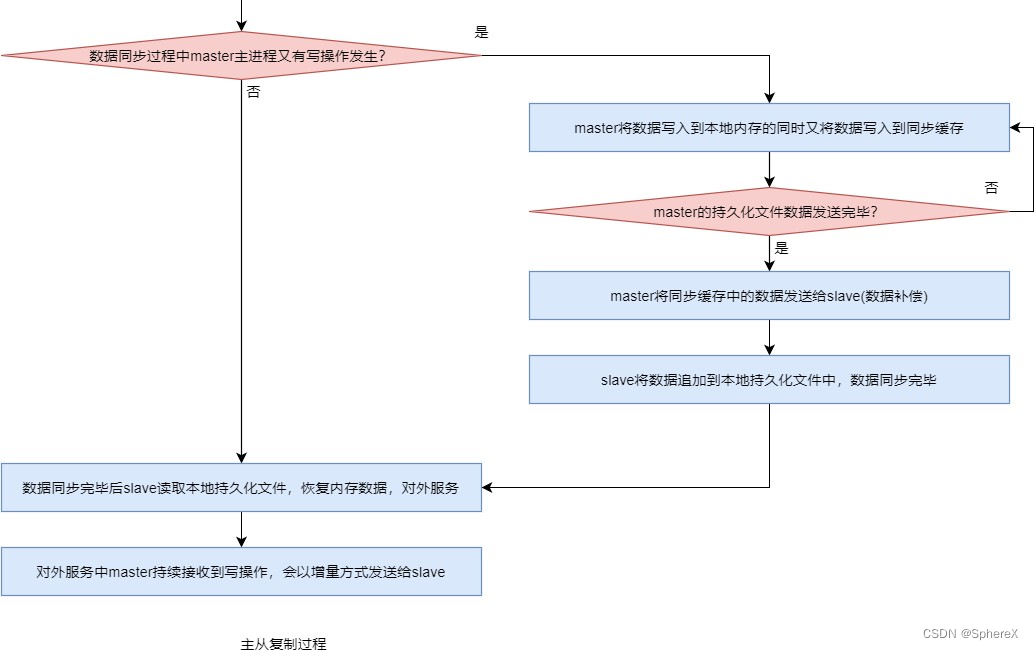 ?
?
数据同步演变过程
sync 同步Redis 2.8 版本之前,首次通信成功后, slave 会向 master 发送 sync 数据同步请求。然后master 就会将其所有数据全部发送给 slave ,由 slave 保存到其本地的持久化文件中。这个过程称为全量复制。但这里存在一个问题:在全量复制过程中可能会出现由于网络抖动而导致复制过程中断。当网络恢复后, slave 与 master 重新连接成功,此时 slave 会重新发送 sync 请求,然后会从头开始全量复制。由于全量复制过程非常耗时,所以期间出现网络抖动的概率很高。而中断后的从头开始不仅需要消耗大量的系统资源、网络带宽,而且可能会出现长时间无法完成全量复制的情况。
psync
同步
Redis 2.8
版本之后,全量复制采用了
psync
(
Partial Sync
,不完全同步)同步策略。当
全量复制过程出现由于网络抖动而导致复制过程中断时,当重新连接成功后,复制过程可以
“断点续传”
。即从断开位置开始继续复制,而不用从头再来。这就大大提升了性能。
系统为每个要传送数据进行了编号,该编号从
0
开始,每个字节一个编号。该编号称为
复制偏移量。参与复制的主从节点都会维护该复制偏移量。
当
master
启动后就会动态生成一个长度为
40
位的
16
进制字符串作为当前
master
的复
制
ID
,该
ID
是在进行数据同步时
slave
识别
master
使用的。通过
info replication
的
master_replid
属性可查看到该
ID
。
当
master
有连接的
slave
时,在
master
中就会创建并维护一个队列
backlog
,默认大小
为
1MB
,该队列称为
复制积压缓冲区
。
master
接收到了写操作数据不仅会写入到
master
主
存,写入到
master
中为每个
slave
配置的发送缓存,而且还会写入到复制积压缓冲区。其作
用就是用于保存最近操作的数据,以备“断点续传”时做数据补偿,防止数据丢失。
在 psync 数据同步过程中,若 slave 重启,在 slave 内存中保存的 master 的动态 ID 与续传 offset 都会消失,“断点续传”将无法进行,从而只能进行全量复制,导致资源浪费。? 在 psync 数据同步过程中, master 宕机后 slave 会发生“易主”,从而导致 slave 需要从新 master 进行全量复制,形成资源浪费。Redis 4.0 对 psync 进行了改进,提出了“同源增量同步”策略。针对“ slave 重启时 master 动态 ID 丢失问题”,改进后的 psync 将 master 的动态 ID 直接写入到了 slave 的持久化文件中。slave 易主后需要和新 master 进行全量复制,本质原因是新 master 不认识 slave 提交的psync 请求中“原 master 的动态 ID ”。如果 slave 发送 PSYNC < 原 master_replid> <repl_offset>命令,新 master 能够识别出该 slave 要从原 master 复制数据,而自己的数据也都是从该 master复制来的。那么新 master 就会明白,其与该 slave“师出同门”,应该接收其“断点续传”
同步请求。而新 master 中恰好保存的有“原 master 的动态 ID ”。由于改进后的 psync 中每个 slave都在本地保存了当前 master 的动态 ID ,所以当 slave 晋升为新的 master 后,其本地仍保存有之前 master 的动态 ID 。而这一点也恰恰为解决“ slave 易主”问题提供了条件。通过 master的 info replicaton 中的 master_replid2 可查看到。如果尚未发生过易主,则该值为 40 个 0 。
?
Redis 7.0
版本对复制积压缓冲区进行了改进,让各个
slave
的发送缓冲区共享复制积压
缓冲区。这使得复制积压缓冲区的作用,除了可以保障数据的安全性外,还作为所有
slave
的发送缓冲区,充分利用了复制积压缓冲区。
文章来源:https://blog.csdn.net/m0_65228708/article/details/134976535
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux 一键部署二进制Gitea
- 极市平台|100+深度学习各方向数据集资源大盘点
- Python 循环结构之for循环结合range()函数使用技巧
- jps命令 pwdx命令
- 003-09-07【RDD-Transformation】老王家女儿大红用GPT学习Spark: pipe、coalesce、 repartition
- ElasticSearch 复合查询 Boolean Query
- 强化学习入门
- 【论文笔记】ZOO: Zeroth Order Optimization
- Redis怎么测?这篇文章写的太全了
- 判断自守数