【深度学习:数据管理工具】2024 年计算机视觉的 7 大数据管理工具

【深度学习:数据管理工具】2024 年计算机视觉的 7 大数据管理工具
发现 2024 年计算机视觉的 7 种数据管理工具,您需要了解这些工具,以迎接新的一年。比较它们的功能和定价,并选择最适合您需求的数据管理工具。
我们明白了——
在计算机视觉 MLOps 管道中查找和实现高质量的数据管理工具可能是一个困难而乏味的过程。
特别是因为大多数工具需要您进行大量手动集成工作,以使其适合您的特定 MLOps 堆栈。
市场上有如此多的平台、工具和解决方案,很难清楚地了解每种工具提供什么,以及选择哪一种
在这篇文章中,我们将介绍截至 2023 年计算机视觉的顶级数据管理工具。 我们将根据注释支持、功能、自定义、数据隐私、数据管理、数据可视化、与机器学习管道的集成以及客户支持等标准对它们进行比较。
我们的目标是帮助您找到适合您特定用例和预算的最佳数据管理工具。
无论您是研究人员、开发人员还是数据科学家,本文都将为您提供有价值的信息和见解,帮助您做出明智的决定。
以下是我们将介绍的内容:
- Encord Active
- Sama
- Superb AI
- Lightly.ai
- Voxerl51
- Scale Nucleus
- ClarifAI
但在我们开始之前…
什么是计算机视觉中的数据管理?
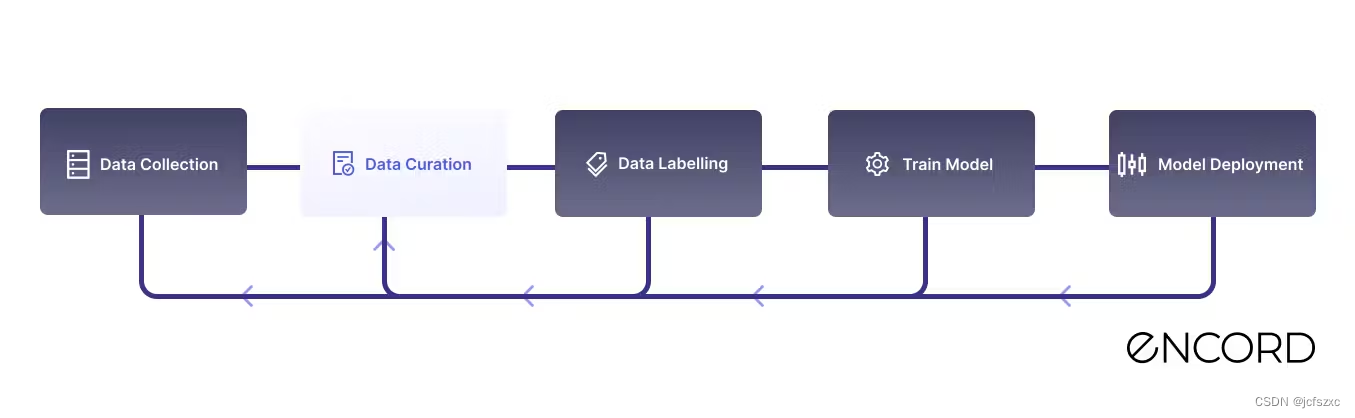
对于机器学习团队来说,数据管理是一个相对较新的重点领域。从本质上讲,它涵盖了跨 MLOps 管道的数据管理和处理。更具体地说,它指的是 1) 收集、2) 清理、3) 组织、4) 评估和 5) 维护数据以确保其质量、相关性和适合您的特定计算机视觉任务的过程。
最近,它还开始指查找模型边缘案例并显示相关数据,以提高这些案例的模型性能。
在数据管理范式进入之前,数据科学家和数据运营团队只是简单地向他们的标记团队提供原始的视觉数据,这些数据被标记并发送用于模型训练。随着训练数据管道的成熟,这种策略不再实用且具有成本效益。
这就是良好的数据管理进入画面的地方。

如果没有良好的数据管理实践,您的计算机视觉模型可能会受到性能、准确性和偏差的影响,从而导致结果欠佳,在某些情况下甚至失败。
此外,一旦您准备好扩展计算机视觉工作并将多个模型投入生产,将重要的生产数据汇集到训练数据管道中并确定下一步注释的优先级的任务将变得越来越具有挑战性。在基本情况下,您需要一种结构化的方法,在最好的情况下,需要一种高度自动化的以数据为中心的方法。
最后,当您在生产环境中发现计算机视觉模型的边缘情况时,您需要有一个清晰且结构化的流程来确定要发送哪些数据进行标记,以改进训练数据并覆盖边缘情况。
因此,拥有正确的数据管理工具对于任何计算机视觉项目都至关重要。
在计算机视觉中的数据管理工具中要考虑什么?
我们每年与数百个 ML 和数据科学家团队合作,将数千个模型部署到生产环境中,在选择工具时收集了一份全面的最佳实践列表。该列表并非 100% 详尽无遗,因此,如果您有任何想添加的内容,我们很乐意在这里收到您的来信。
Data Prioritization 数据优先级
选择正确的数据对于训练和评估计算机视觉模型至关重要。一个好的数据管理工具应该能够为给定的任务过滤、排序和选择适当的数据。这包括能够处理大型数据集,以及根据某些属性或标签选择数据的能力。如果该工具支持可靠的自动化功能以进行数据优先级排序,那将是一大优势。
Visualizations 可视 化
可自定义的数据可视化对于理解和分析大型数据集非常重要。一个好的工具应该能够以各种形式显示数据,例如表格、绘图和图像,并允许自定义这些可视化以满足用户的特定需求。
Model-Assisted Insights 模型辅助见解
模型辅助调试是数据管理工具的另一个重要功能。这允许对模型性能进行可视化和分析,并有助于识别数据或模型本身中可能存在的问题。这可以通过混淆矩阵、类激活图或显著性图等功能来实现。
Modality Support 模态支持
对不同模式的支持对于计算机视觉也很重要。一个好的数据管理工具应该能够处理多种不同类型的数据,例如图像、视频、DICOM 和地理。TIFF,同时将支持扩展到所有注释格式,例如边界框、分割、折线、关键点等。
Simple & Configurable User Interface (UI) 简单且可配置的用户界面
数据管理工具通常由多个技术和非技术利益相关者使用。因此,一个好的工具应该易于导航和理解,即使对于那些在计算机视觉方面经验不足的人来说也是如此。应支持设置重复的自动化工作流,同时还应提供对 Webhook、API 调用和 SDK 的编程支持。
Annotation Integration 注释集成
重复注释和标记是计算机视觉数据管理的关键部分。一个好的工具应该能够轻松支持注释工作流,并允许创建、编辑和管理标签和注释。
Collaboration 协作
协作对于数据管理也很重要。一个好的工具应该能够支持多个用户,并允许在数据集和注释上轻松共享和协作。这可以通过共享注释项目和实时协作等功能来实现。
Encord Active
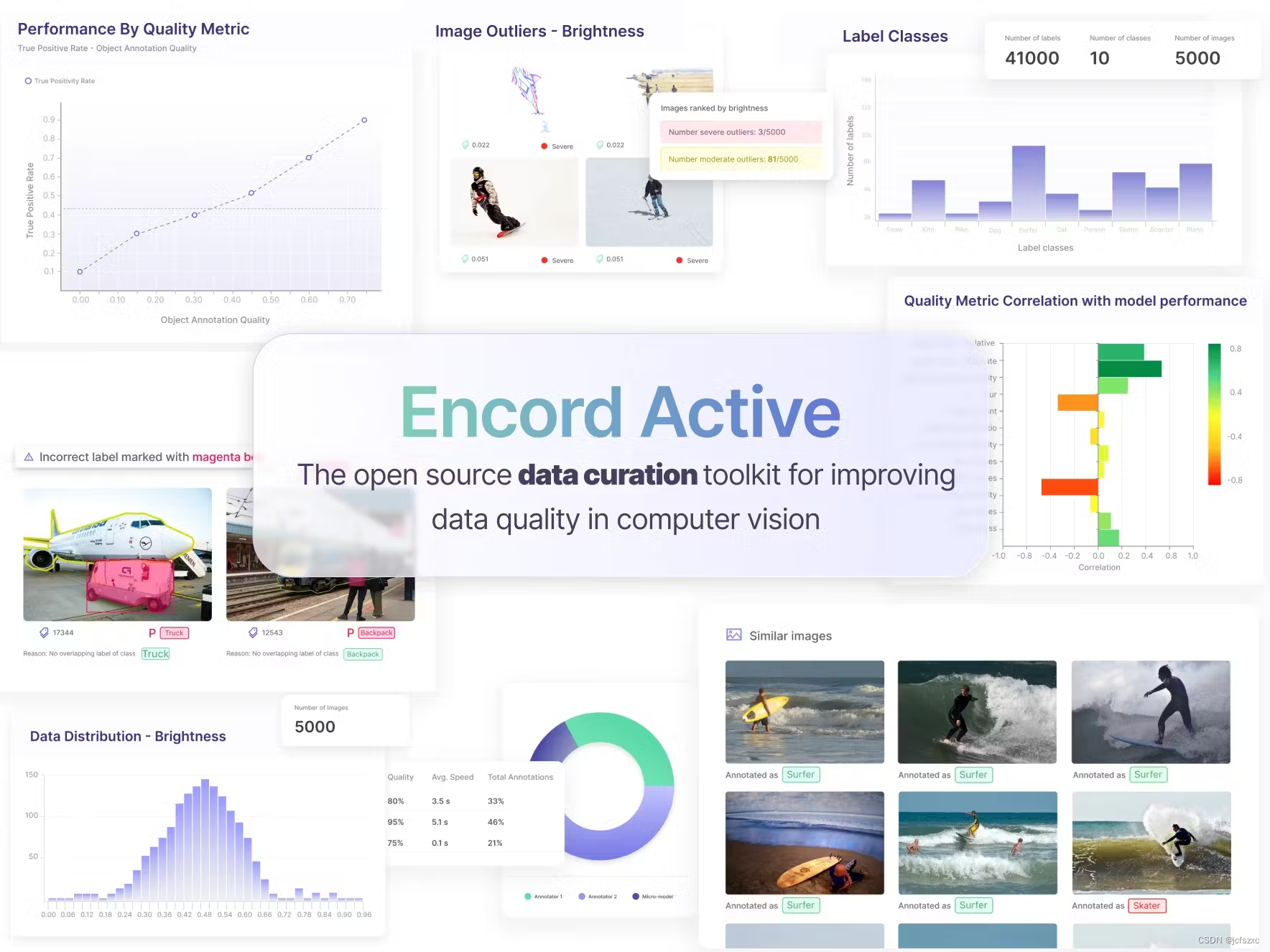
Encord Active 是一款开源的主动学习和数据整理工具包,专注于帮助人工智能工程师找到计算机视觉模型中的故障模式,确定下一步标注数据的优先级,并推动智能数据整理,以提高模型性能、降低标注成本并更好地理解模型。
Encord Active 支持以质量指标的形式进行模型辅助数据调试,这使其非常适合对象检测、分割和分类问题。该软件是开源的,可以在所有平台上运行良好:Linux、MacOS 和 Microsoft OS。但是,Encord Active 不支持 NLP 功能。
优势和主要特点:
- 庞大的质量指标库,用于了解您的数据
- 有机会根据图像特征、元数据、标签、嵌入等构建自定义指标,以支持数据管理
- 内置注释工具
- 利用基于机器学习算法的智能相似性搜索
- 支持图像处理和数据增强
- 模型辅助数据和标签调试
- 唯一为医学成像提供专业支持的医疗保健数据管理工具
最适合:
希望为其数据管理流程提供动力的公司。Encord Actrive 不仅是成熟计算机视觉公司的首选解决方案,也是刚起步并寻找免费开源工具包以添加到其 MLops 或训练数据管道中的公司的最佳解决方案。
开源许可证:
Encord Active 在 Apache-2.0 许可下可用。阅读我们的文档,详细了解如何自托管 Encord Active,并在此处查看 GitHub 存储库。
Sama

Sama Curate 采用的模型可以交互式地建议哪些资产需要标记,即使在预先过滤和完全未标记的人工智能数据集上也是如此。
这种智能分析和管理可优化您的模型准确性,同时最大限度地提高您的投资回报率。Sama 可以帮助您从“大数据”数据库中识别要标记的最佳数据,以便您的数据科学团队可以快速优化深度学习模型的准确性。
优势和主要特点:
- 交互式嵌入和分析
- 机器学习模型监控
- 本地部署
- 为企业提供简化的流程
最适合:
ML 工程团队正在寻找一种具有劳动力的工具。
开源许可证:
Sama 目前没有开源解决方案。
Superb AI DataOps
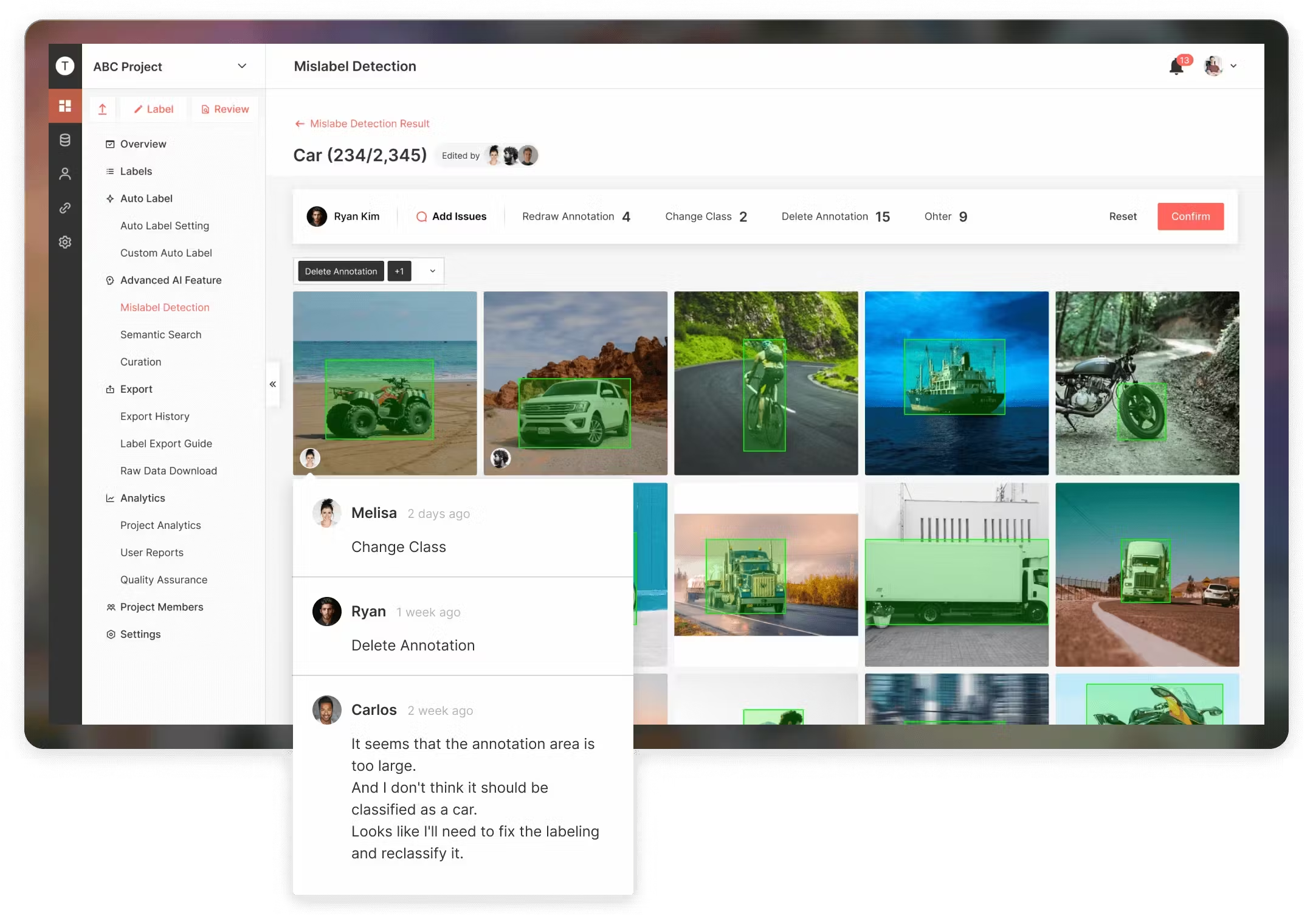
卓越的 AI DataOps 可确保您始终策划、标记和使用最佳机器学习数据集。使用 SuperbAI 的策展工具来策展更好的数据集,并创建为最终用户和您的业务带来价值的 AI。
让数据质量成为几乎不可思议的结论 DataOps 消除了数据探索、管理和质量保证中的劳动力、复杂性和猜测,因此您可以专注于构建和部署最佳模型。适用于简化为简单图像数据类型构建训练数据集的过程。
优势和主要特点:
- 相似性搜索
- 交互式嵌入
- 模型辅助数据和标签调试
- 适用于对象检测,因为它支持边界框、分割和多边形
最适合:
正在寻找新工具的患者机器学习工程师。
开源许可证:
Superb AI 目前没有开源解决方案。
FiftyOne
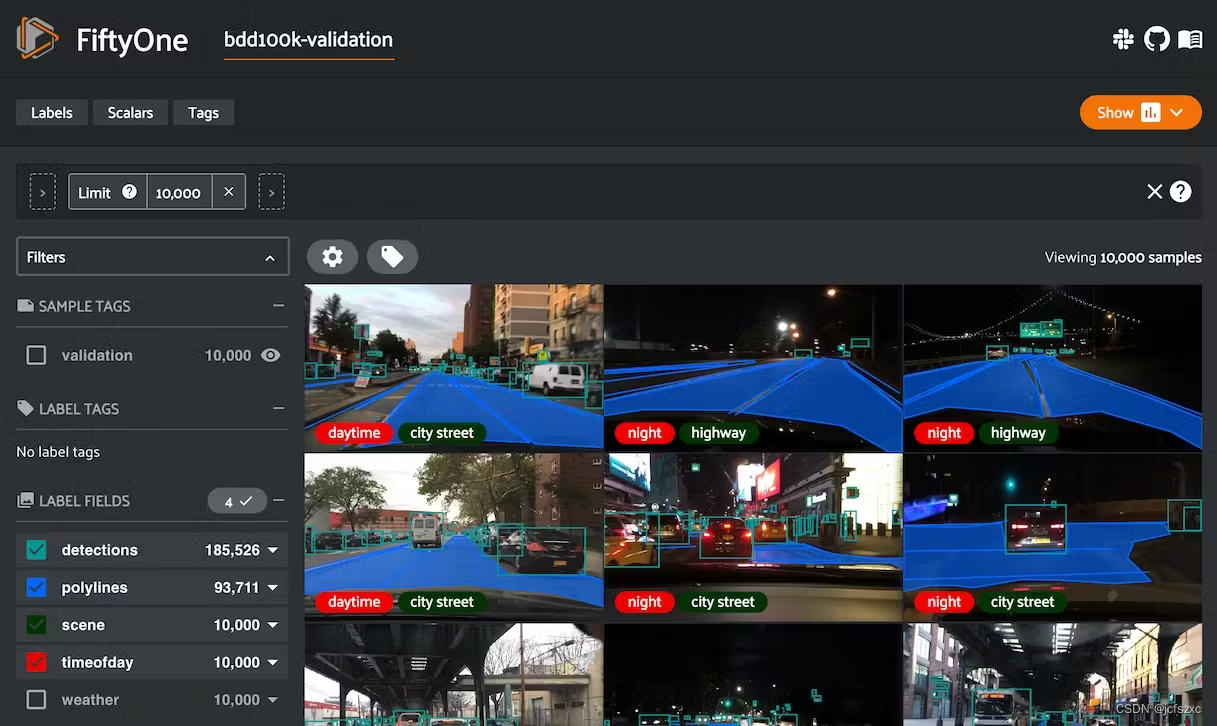
FiftyOne 最初由 Voxel51 开发,是一种用于可视化和解释计算机视觉数据集的开源工具。
该工具由三个组件组成:Python 库、Web 应用程序 (GUI) 和大脑。库和 GUI 是开源的,而 Brain 是闭源的。
FiftyOne 不包含任何自动标记功能,因此最适合以前注释过的数据集。此外,该工具支持图像和视频数据,但目前不适用于多模态传感器数据集。
FiftyOne缺乏有趣的视觉效果和图表,并且没有对Microsoft Windows机器的最佳支持。
优势和主要特点:
- FiftyOne拥有一个由开源数据集和开源模型组成的大型“动物园”。
- 使用 Fiftyone Brain(一个单独的闭源 Python 包)进行高级数据分析。
- 与流行的注释工具(如CVAT)的良好集成。
最适合:
个人、学生和机器学习研究人员,其项目不需要复杂的协作或托管。
开源许可证:
FiftyOne 在 Apache-2.0 下获得许可,可从他们的存储库中获得 这里.FiftyOne Brain 是一个闭源软件。
Lightly.AI
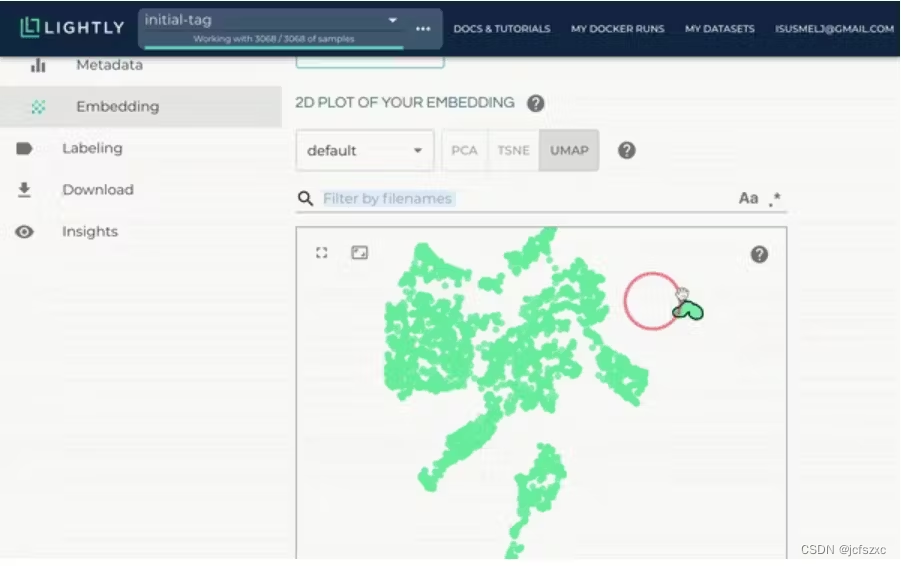
Lightly 是一款专门用于计算机视觉的数据管理工具。它使用自监督学习在数据集中查找相似数据的集群。它基于智能神经网络,可智能地帮助您选择接下来要标记的最佳数据(也称为主动学习,在此处阅读更多内容)。
优势和主要特点:
- 支持通过主动学习算法和AI模型进行数据选择
- 提供本地版本
- 基于元数据的交互嵌入。
- 开源 python 库
最适合:
寻找本地部署的 ML 工程师。
开源许可证:
Lightly.ai的主要工具是闭源的,但他们有一个广泛的python库,用于在麻省理工学院许可的自我监督学习。在 Github 上找到它 此处.
Scale Nucleus
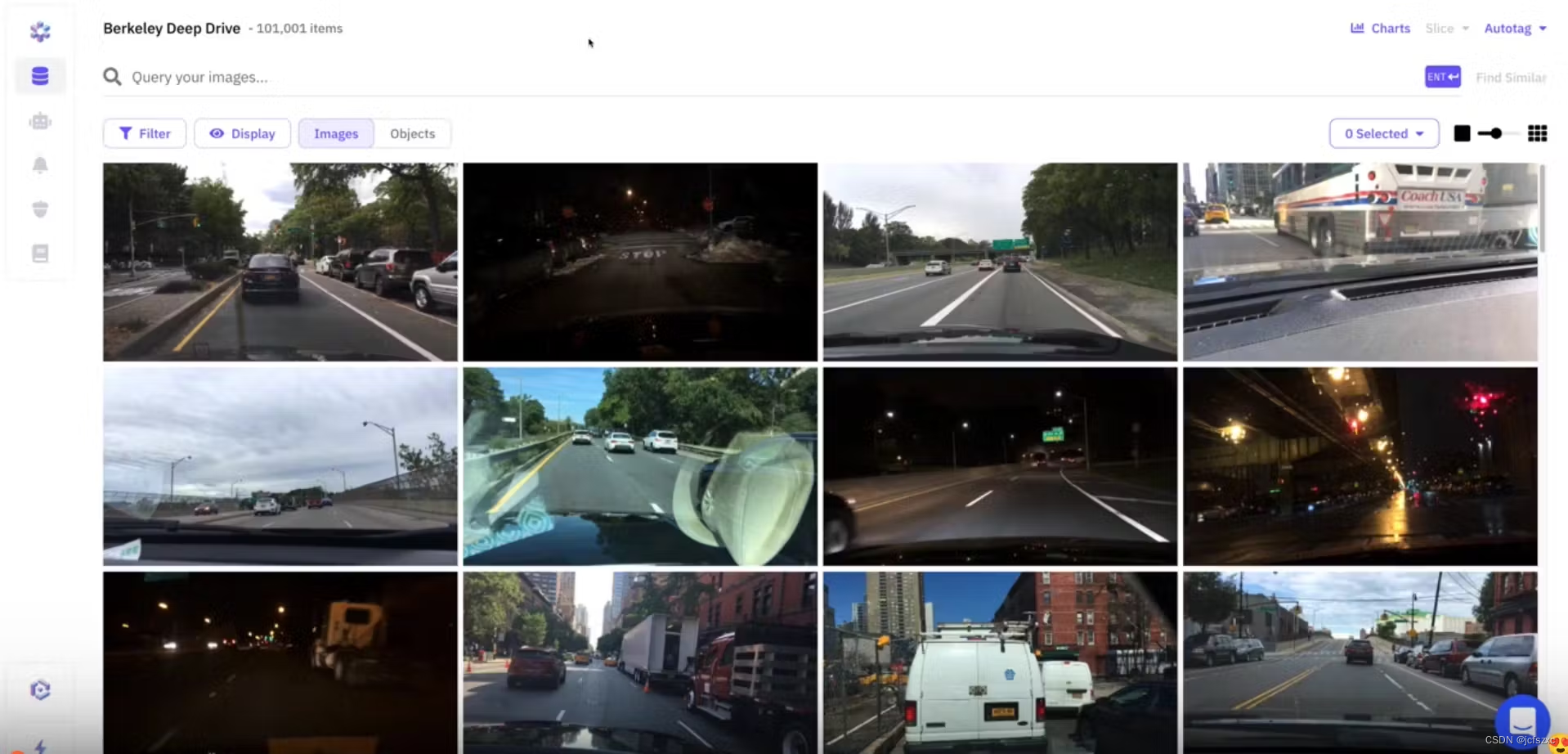
Nucleus 由 Scale AI 于 2020 年底创建,是一款适用于整个机器学习模型生命周期的数据管理工具。尽管最著名的是数据注释劳动力的提供者。新的 Nucleus 平台允许用户搜索视觉数据以查找模型失败(误报),并找到用于数据收集活动的类似图像。截至目前,Nucleus 支持图像数据、3D 传感器融合和视频。
遗憾的是 Nucleus 不支持智能数据处理或任何复杂或自定义指标。 Nucleus 是 Scale AI 生态系统的一部分,该生态系统由各种互连工具组成,可简化构建现实世界 AI 模型的过程。
优点和主要特点:
- 集成数据注释和数据分析
- 相似性搜索
- 模型辅助标签调试
- 支持边界框、多边形和图像分割
- 自然语言处理支持
最适合:
机器学习团队和正在寻找可访问注释人员的简单数据管理工具的团队。
开源许可证:
Scale Nucleus 目前没有开源解决方案。
ClarifAI
Clarifai 是一个计算机视觉平台,专门对图像、视频和文本等非结构化数据进行标记、搜索和建模。作为最早的人工智能初创公司之一,他们提供了一系列功能,包括自定义模型构建、自动标记、视觉搜索和注释。然而,它更像是一个建模平台,而不是开发人员工具,并且它最适合刚接触 ML 用例的团队。他们在机器人和自动驾驶方面拥有广泛的专业知识,因此如果您正在寻找这些领域的机器学习咨询服务,我们会推荐他们。
优点和主要特点:
- 集成数据注释
- 支持大多数数据类型
- 类似于 Voxel51 的广泛模型动物园
- 端到端平台/生态系统
- 支持语义分割、对象检测和多边形。
最适合:
新的机器学习团队和寻求咨询服务的团队。
开源许可证:
ClarifAI 目前没有开源解决方案。
为什么数据管理在计算机视觉中很重要?
数据管理在计算机视觉中至关重要,因为它直接影响模型的性能和准确性。计算机视觉模型依赖大量数据来学习和做出预测,数据的质量和相关性决定了模型泛化和适应新情况的能力。
结论
数据管理是任何计算机视觉项目的一个重要方面。如果没有良好的数据管理实践,您的模型可能会出现性能差、准确性差和偏差的问题。为了确保获得最佳结果,拥有正确的数据管理工具至关重要。
在本文中,我们介绍了 2023 年计算机视觉的 7 个顶级数据管理工具,根据注释支持、功能、定制、数据隐私、数据管理、数据可视化、与机器学习管道的集成等标准对它们进行了比较客户支持。
我们希望本文提供了有价值的信息和见解,帮助您就哪种数据管理工具最适合您的特定用例和预算做出明智的决定。无论如何,请务必记住,工具选择应基于您的特定需求、预算和团队规模。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!