【数据库】第三章 MySQL库表操作
3.1 SQL语句基础(SQL命令)
3.1.1 SQL简介
SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作,数据检索以及数据维护的标准化语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务:
1、改变数据库的结构
2、更改系统的安全设置
3、增加用户对数据库或表的许可权限
4、在数据库中检索需要的信息
5、对数据库的信息进行更新 备份 还原
综上所述 :想要使用Mysql数据库 必须要学习Sql语言。
3.1.2 SQL语句的分类
MySQL致力于支持全套ANSI/ISO SQL标准。在MySQL数据库中,SQL语句主要可以划分为以下几类:
1、DDL(Data Definition Language): 数据定义语言。定义对数据库对象(库、表、列、索引)的操作。
关键字:CREATE、DROP、ALTER、RENAME、 TRUNCATE等。
2、DML(Data Manipulation Language):数据操作语言。定义对数据库记录的操作。
关键字:INSERT、DELETE、UPDATE等。
3、DCL(Data Control Language):数据控制语言。定义对数据库、表、字段、用户的访问权限和安全级别。
关键字:GRANT、REVOKE等。
4、DQL(Data Query Language):数据查询语言。检索并获取数据。
关键字: SELECT。
3.1.3 SQL语句的书写规范
1、在数据库系统中,SQL语句不区分大小写(建议用大写) 。
2、字符串常量区分大小写。
3、SQL语句支持单行 || 多行书写,但必须以;结尾。
4、关键字 || 词汇不能跨行书写。
5、支持空格或缩进以提升语句的可读性。
6、子语句通畅位于独立行,便于编辑,提高可读性。
3.2 数据库操作
1、查看?
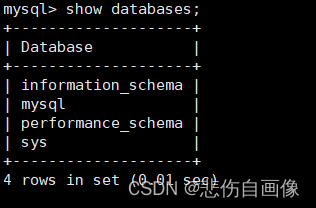
SHOW DATABASES [LIKE wild] ;?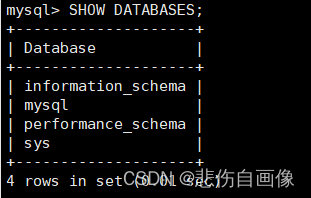
功能:列出Mysql主机上的数据库。
Mysql自带数据库(系统库): ?
information_schema:主要存储了系统中的一些数据库对象信息,如用户信息,列信息,权限信息,字符集信息,分区信息等(数据字典)
performance_schema:主要存储了数据库服务器的性能参数
mysql:主要存储了系统的用户权限信息和帮助文档
sys:5.7后新增产物,information_schema 和 performance_schema 的结合体,并以视图形式显示出来的,查询出更加令人容易理解的数据。
原则:不轻易访问,不轻易修改,不轻易删除!! ?
2、自建库
创建个人数据库
语法:CREATE DATABASE IF NOT EXISTS 数据库名;
CREATE DATABASE IF NOT EXISTS MySchool_db;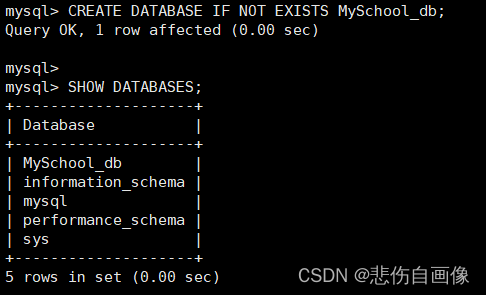 ?
?
 ?
?
一个数据库(微观)是由、表、视图、函数、查询、备份所构成,重中之重是 表
 ?
?
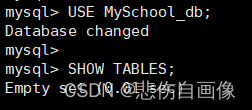
3、切换数据库
使用 USE 关键字进行切换
语法:USE 数据库名;
作用:指定数据库为我们的默认数据库,用于后期建表或其他使用。
其他:
(1)查看当前访问的数据库
SELECT DATABASE();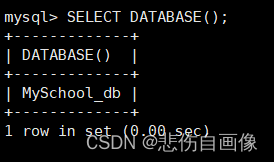 ?
?
(2)查看当前数据库服务器版本
SELECT VERSION();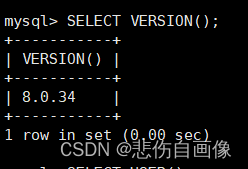 ?
?
3 查看当前登录用户
SELECT USER();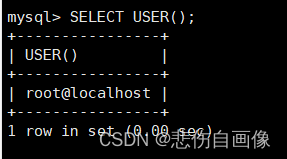 ?
?
(4)查看用户详细信息
SELECT User,Host [,PassWord] FROM mysql.user;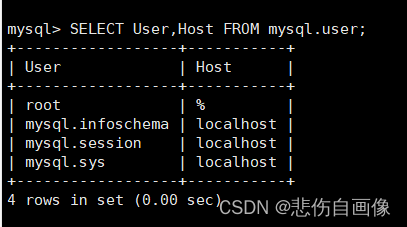 ?
?
注意:目前版本无法直接查看密码(PassWord)?
4、删库
DROP DATABASE [IF EXISTS] 数据库名; ?
?
 ?
?
 ?
?
功能:删除当前数据库 >>>> 里面的结构 数据 全都没了(慎用) ?
3.3 MySQL字符集
MySQL字符集包括 基字符集(CHARACTER)&& 校对规则 (COLLATION)这两个概念:
latin1支持西欧字符、希腊字符等 gbk支持中文简体字符 big5支持中文繁体字符 utf8几乎支持世界所有国家的字符。 utf8mb4是真正意义上的utf-8
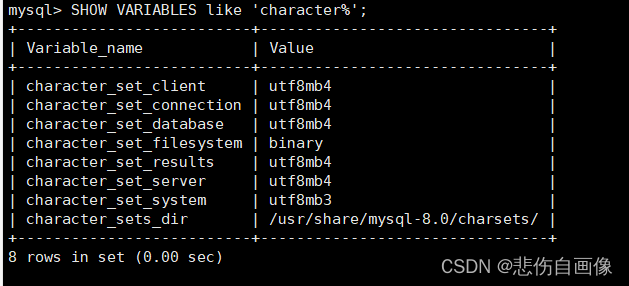
可以使用命令 SHOW VARIABLES like 'character%'; 查看当前数据库默认的字符集
 ?
?
character_set_client MySQL ====> 客户机字符集。 character_set_connection ====> 数据通信链路字符集,当MySQL客户机向服务器发送请求时,请求数据以 该字符集进行编码。 character_set_database ====> 数据库字符集。
utf8和utf8mb4的区别:
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符,如表情等等(utf8的缺点)。
因此在8.0之后,建议大家使用utf8mb4这种编码。
3.4 数据库设计与数据库对象
3.4.1数据库设计的步骤
为啥要进行数据库设计??
1、糟糕的数据库设计 VS 成熟的数据库设计
2、数据冗余,存储空间造成浪费 VS 节省数据的存储空间
3、内存 日志 空间浪费 VS 完整性高,数据原子性强
4、数据的更新和插入时时刻刻伴随着风险和异常 VS 方便进行数据库应用和系统开发
那么如何进行数据库设计??
?
步骤:
1、需求分析阶段:旨在分析客户的业务和数据处理的需求
2、概要设计阶段:设计出数据库的E-R模型图,确认需求信息的正确和完整性
3、详细设计阶段:运用数据库三大范式越泽,规范审核数据库结构,形成数据库模型图
4、代码编写阶段:物理实现数据库,代码实现应用
5、测试阶段: 实践 || 实验
6、备份还原阶段:...
3.4.2 如何绘制数据库E-R图
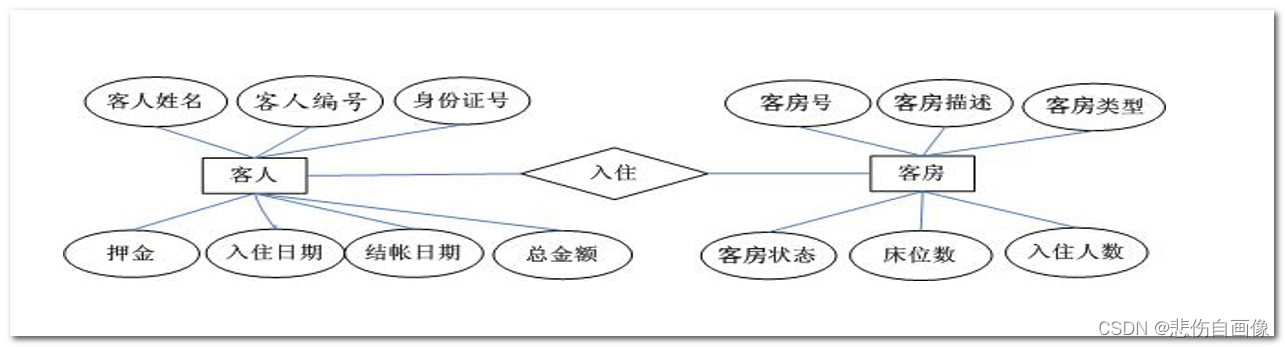
例题:酒店管理系统的基本功能:
1、收集信息:系统有关人员进行交流、座谈,充分了解用户需求,理解数据库需要完成的任务
-
旅客办理入住手续:后台数据库需要存放入住客人的信息和客房信息
-
客房信息:后台数据库需要存放客房的相关信息,如客房号、床位数、价格等
-
客房管理信息:后台数据库需要保存客房类型信息和客房当前状态信息
2、标识出实体:数据库要管理的关键对象或实体内容,实体通常情况下是一个名词
-
客人:入住酒店的旅客。办理入职手续时,需填写用户信息。
-
客房:酒店为客人提供休息的住所。
3、标识出每个实体的属性:
-
客人属性:编号 姓名 身份证.....
-
客房属性:编号 名称 床位 状态 类型....
4、标识出实体和实体之间的关系:
实体和实体之间的关系 通常用动词去描述
入住 关系
客房和客人之间 存在主从关系 ====> 客房是主1 客人是从N
1对N关系 ====> 被引用 引用关系
从设计角度上来说 就是N个人可以住一个房子
客房被客人引用了 >>>> 客人引用了客房
绘制E-R 实体关系图(三要素):
| 符号 | 含义 |
|---|---|
| 矩形 | 实体,一般是名词 |
| 椭圆形 | 实体,一般是名词 |
| 菱形 | 关系,一般是动词 |
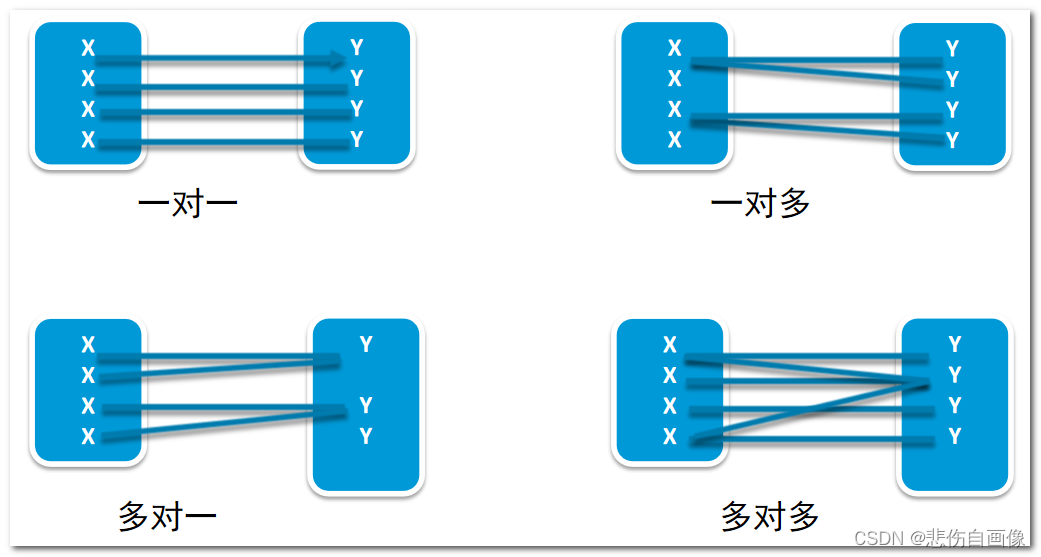
关系型数据库常见映射基数
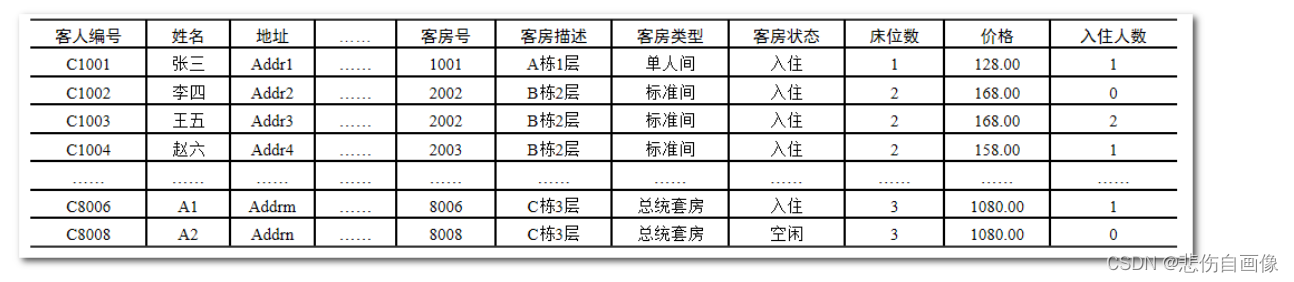
转化E-R图形成数据库模型图
1、将各实体转化为对应的各表,将各属性对应成为各表的列。
2、标识出每个表的主键列(非空+唯一),一张表有且只有一个主键列。
3、在表之间建立主外键,形成引用被引用关系。

3.4.3使用三大范式实现数据库设计规范化
为什么要进行数据规范化设计
缺点:
-
信息重复
-
更新异常
-
插入异常_无法正确表示信息
-
删除异常_丢失有效信息
三大范式原则:
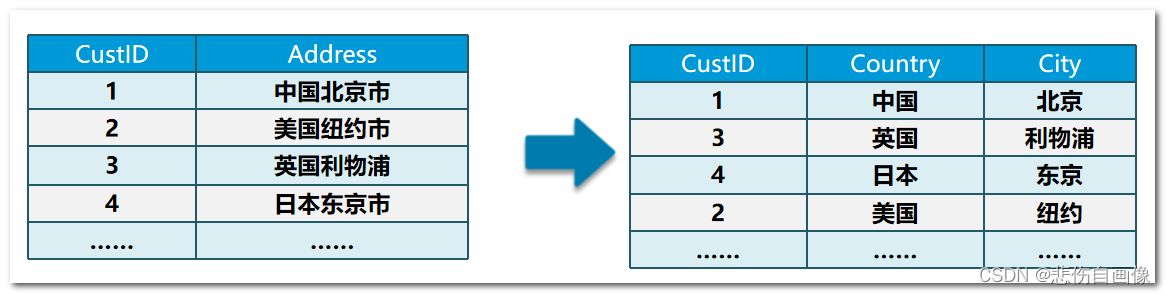
第一范式 (1st NF)
-
第一范式的目标是确保每列的原子性
-
如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)
 第二范式(2st NF)
第二范式(2st NF)
-
第二范式要求每个表只描述一件事情
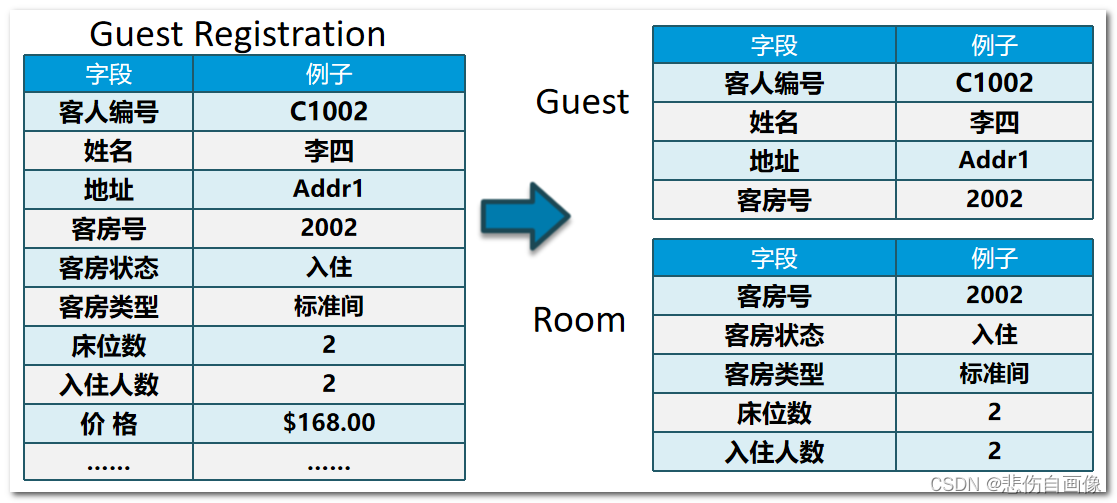
第三范式 (3st NF)
-
如果一个关系满足2NF,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式(3NF)
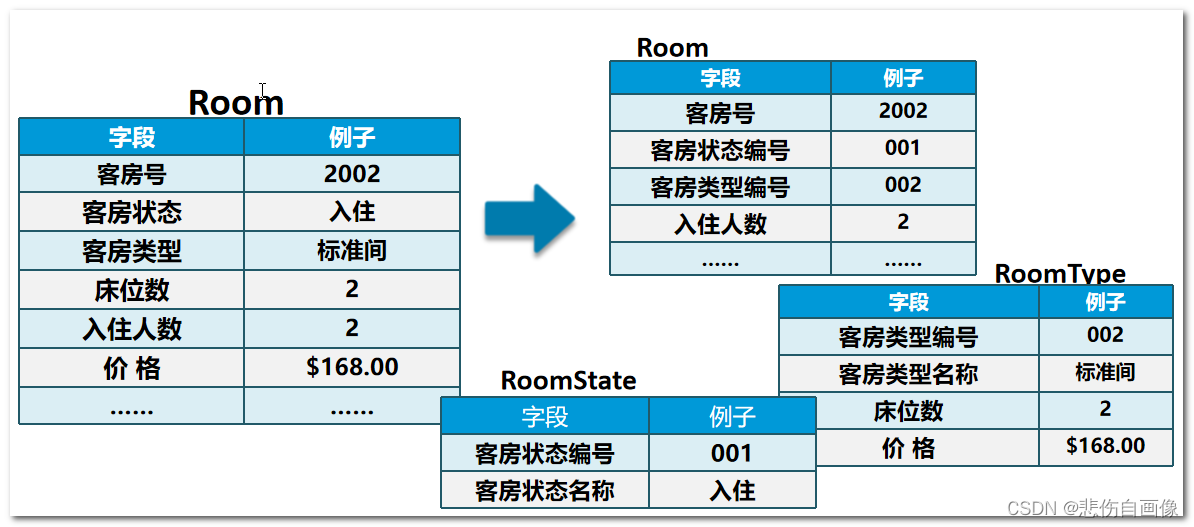
规范化的酒店管理系统E-R图
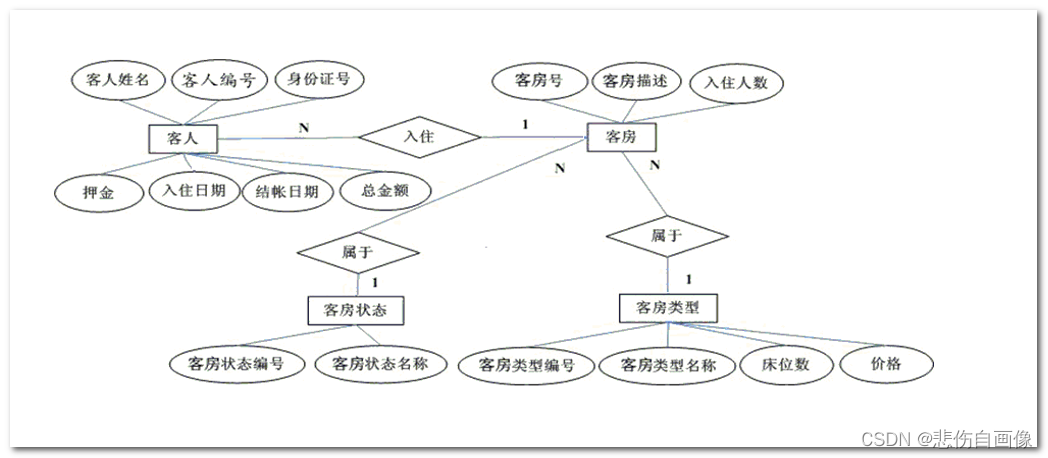
规范化的酒店管理系统数据库模型图
后面就可以开心的完成建表的操作了!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 零经验外贸SOHO怎么做?海洋建站的教程?
- JUC之CompletableFuture
- 字节8年经验之谈!如何做好联调测试?
- 【深度解析C++之初始化列表】
- CSS学习之路: 基础学习篇
- 美易平台:达沃斯论坛上谈论公司架构与未来发展
- ZCC2007--1.8V 同步升压到5V,工作电流5A,替代SY7066
- 部署智能合约以及 javascript 调用合约函数(Web3项目二实战之三)
- Android开发中报错总结之一
- 低代码平台浅析:引迈JNPF